# A tibble: 4 × 7
组 n 均值_x 均值_y 方差_x 方差_y 相关系数
<chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 11 9 7.5 11 4.13 0.82
2 2 11 9 7.5 11 4.13 0.82
3 3 11 9 7.5 11 4.12 0.82
4 4 11 9 7.5 11 4.12 0.82数据挖掘与R语言
第7讲:数据可视化 ~ Part 1
2026年04月09日
1.1 Anscombe 四重奏:数字会撒谎,图不会
四组数据,统计摘要几乎完全相同:
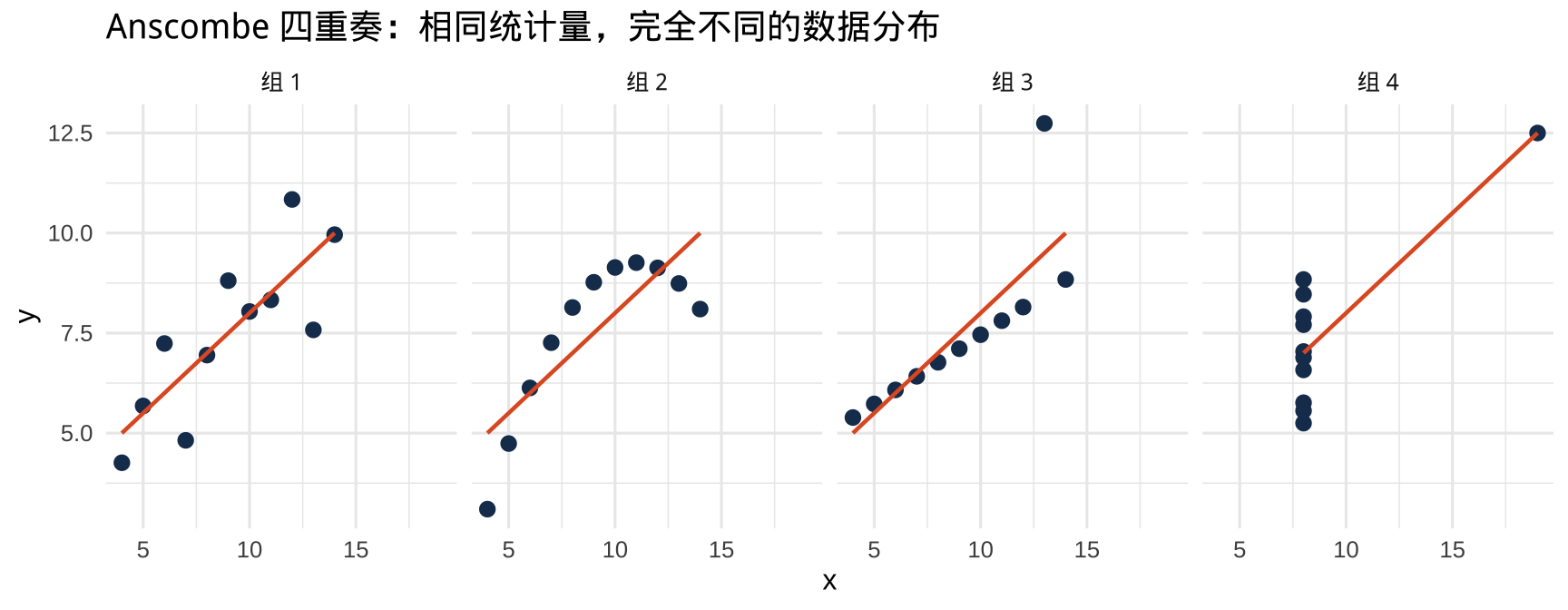
重要
同样的均值、方差、相关系数——只有作图才能发现真相。可视化不是分析的装饰,而是分析本身。
1.2 可视化的两个核心用途
探索性可视化(EDA)
- 对象:分析师自己
- 目的:快速理解数据——找分布、看异常、发现规律
- 标准:快、准、够用即可
- 工具:base R 或 ggplot2 默认设置
展示性可视化(Communication)
- 对象:读者、观众、决策者
- 目的:清晰传达结论,支持决策
- 标准:美观、信息密度高、自我解释
- 工具:ggplot2 精细调整
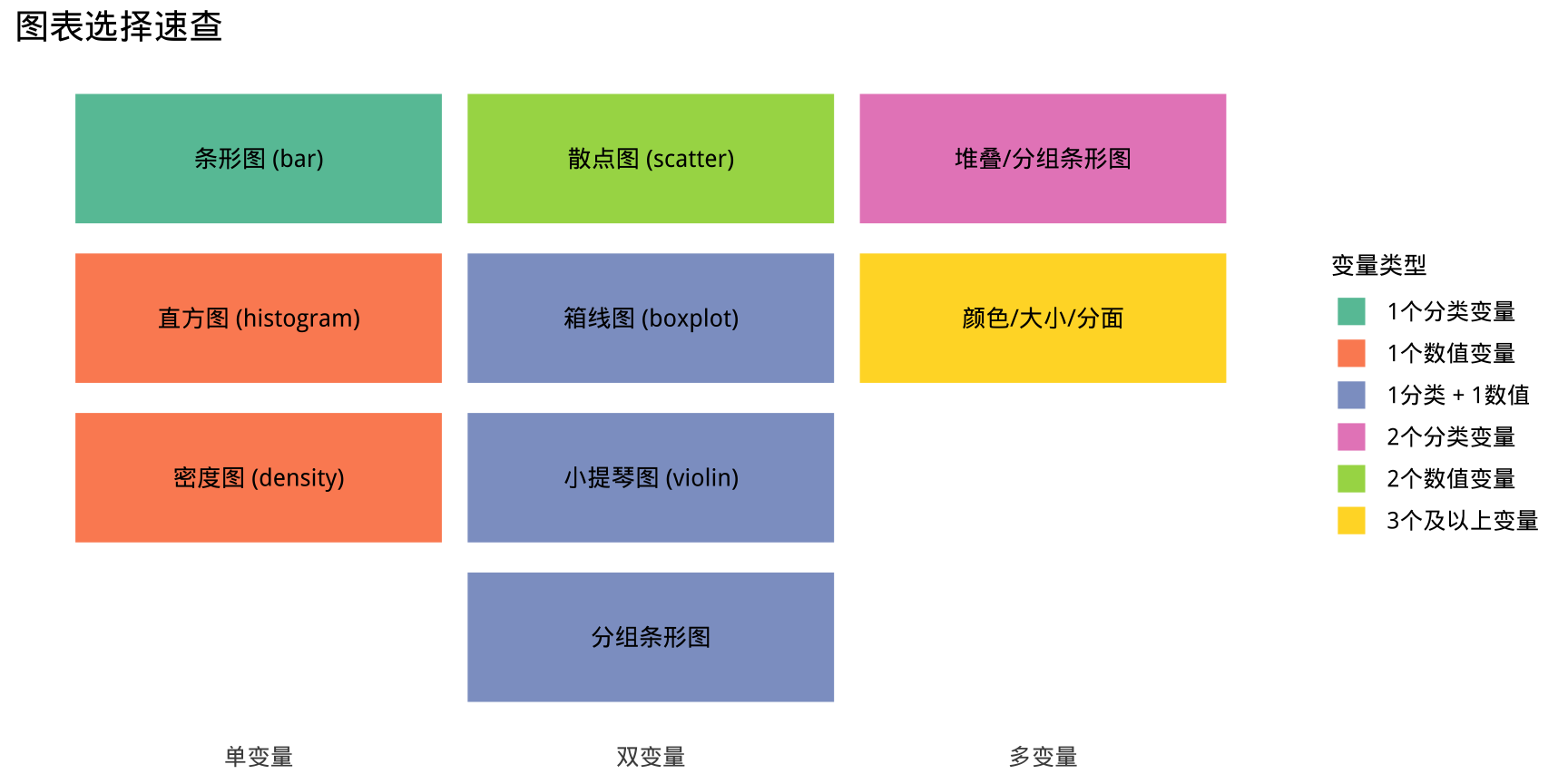
1.3 如何选择图表类型?
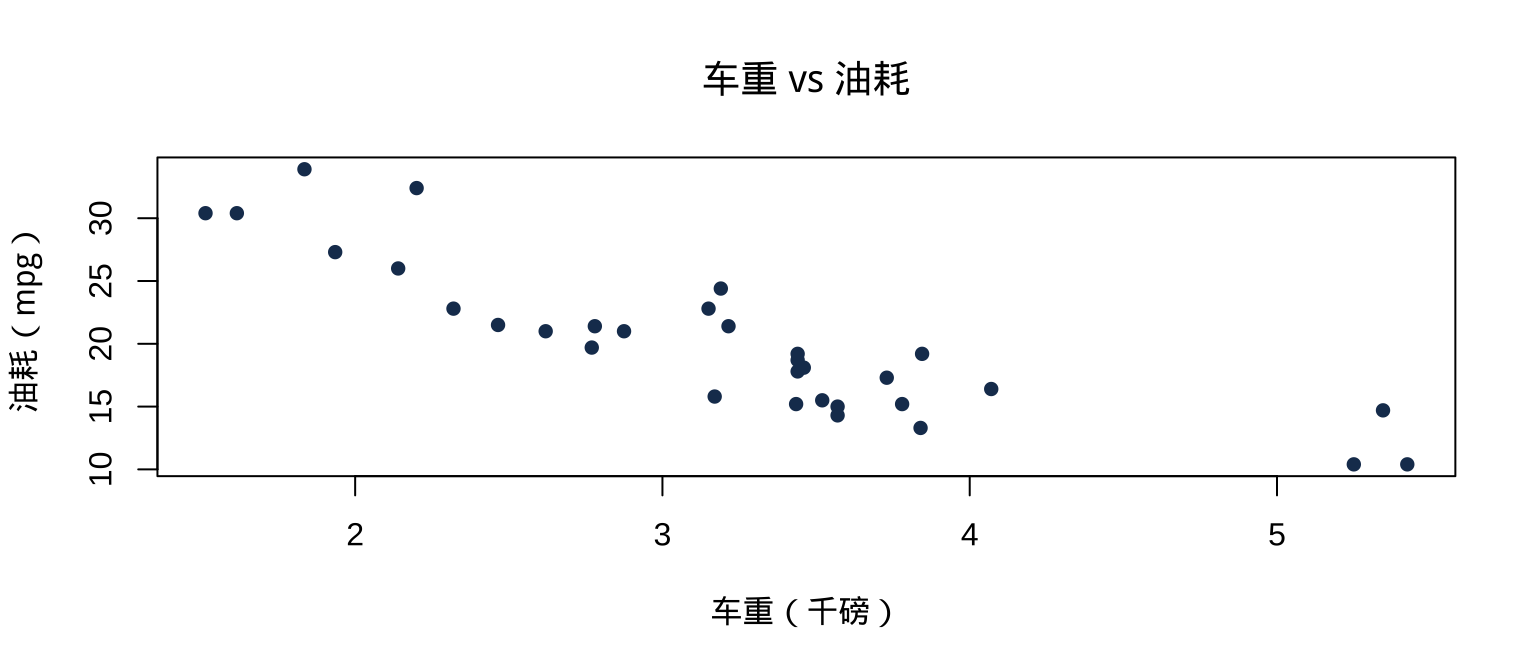
2.1 plot():万能的散点图
plot() 是 base R 最核心的作图函数,根据输入类型自动选择图形:
▶️ 查看代码
注记
pch 控制点的形状(16 = 实心圆),col 控制颜色,main/xlab/ylab 设置标题和轴标签。这几个参数几乎适用于所有 base R 图形函数。
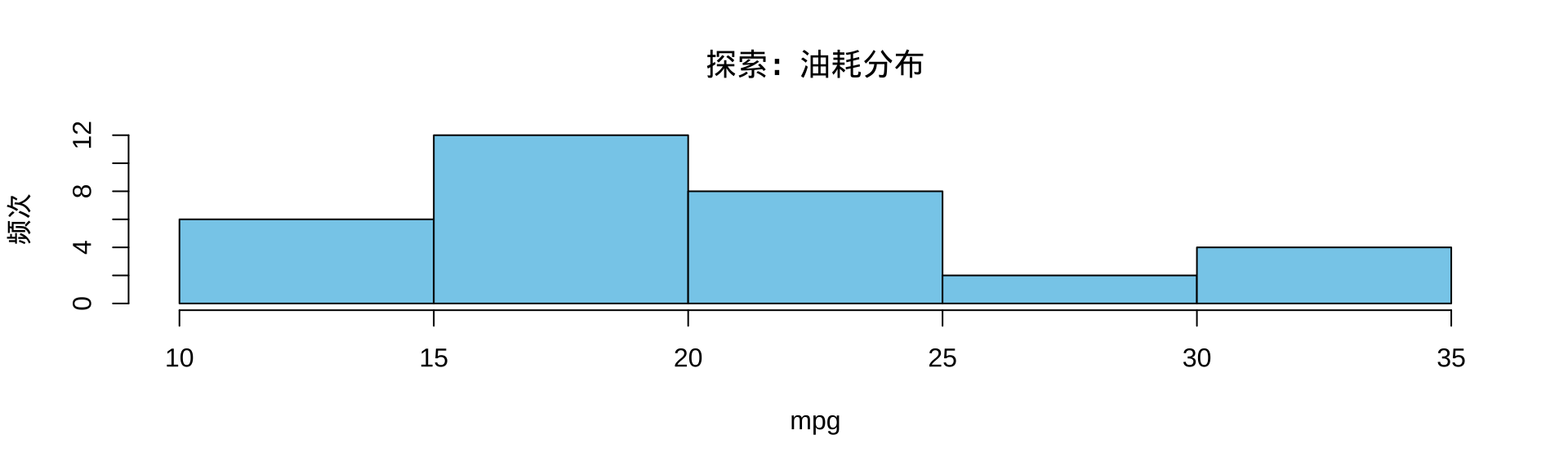
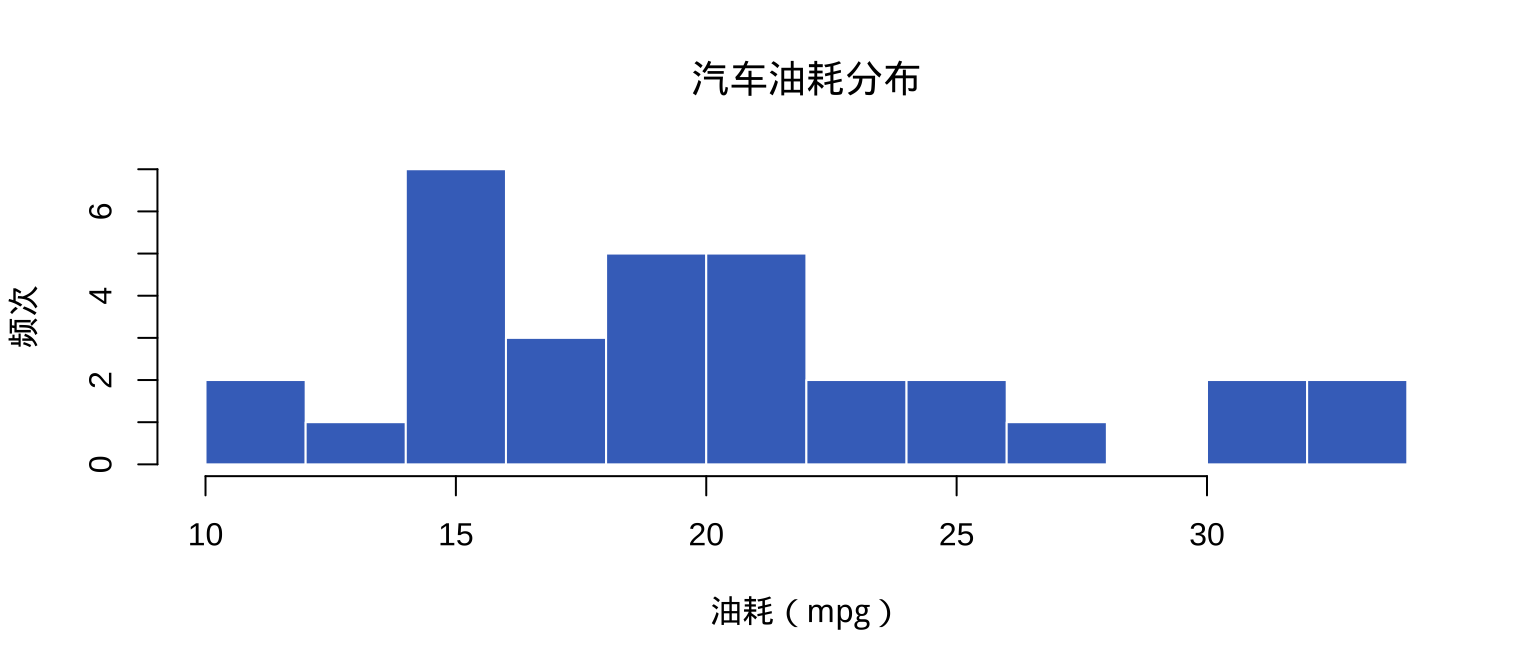
2.2 hist():直方图
▶️ 查看代码
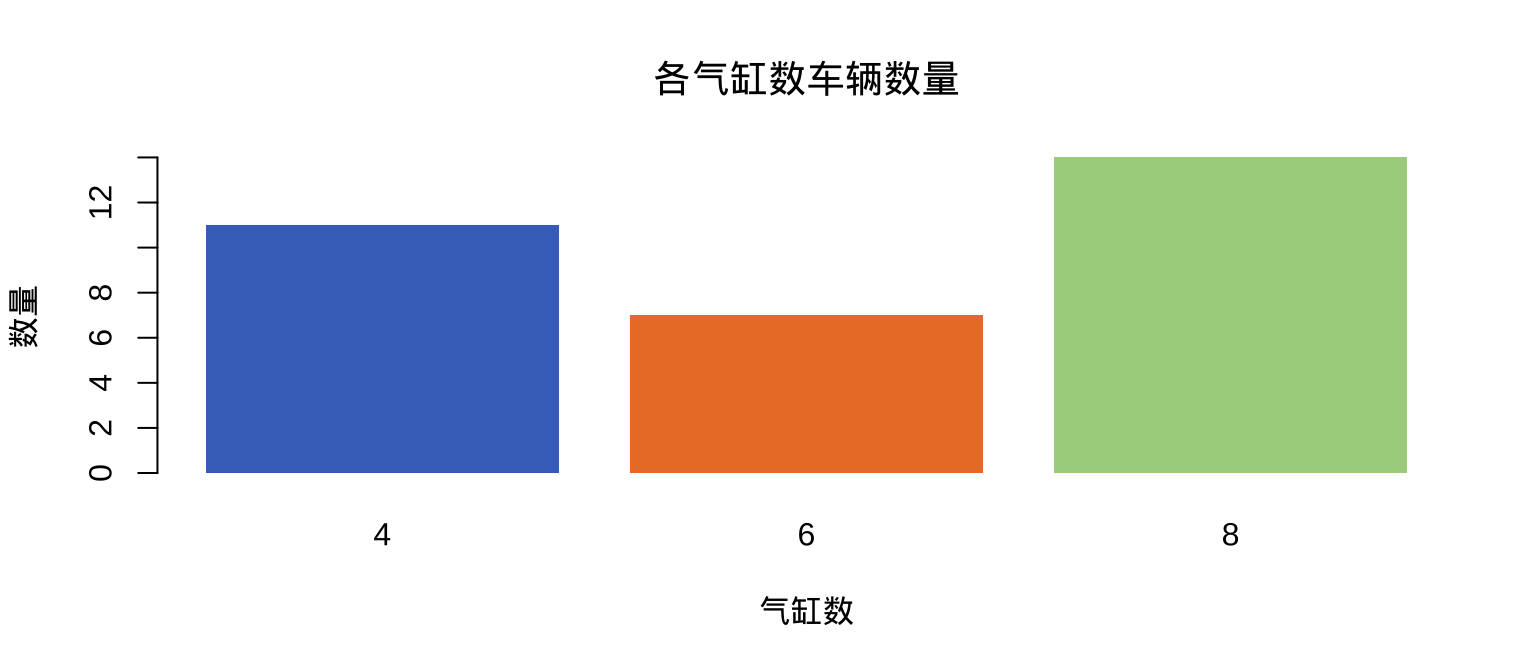
2.3 barplot():条形图
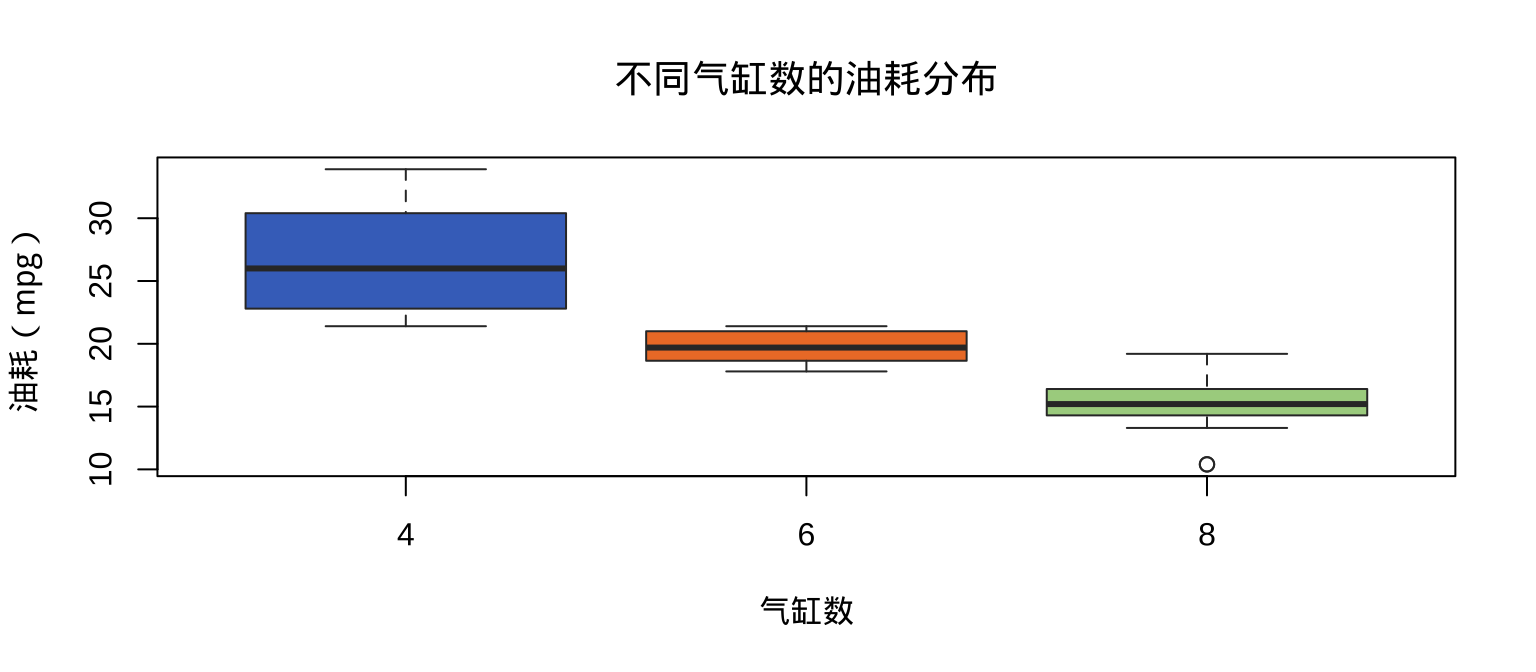
2.4 boxplot():箱线图
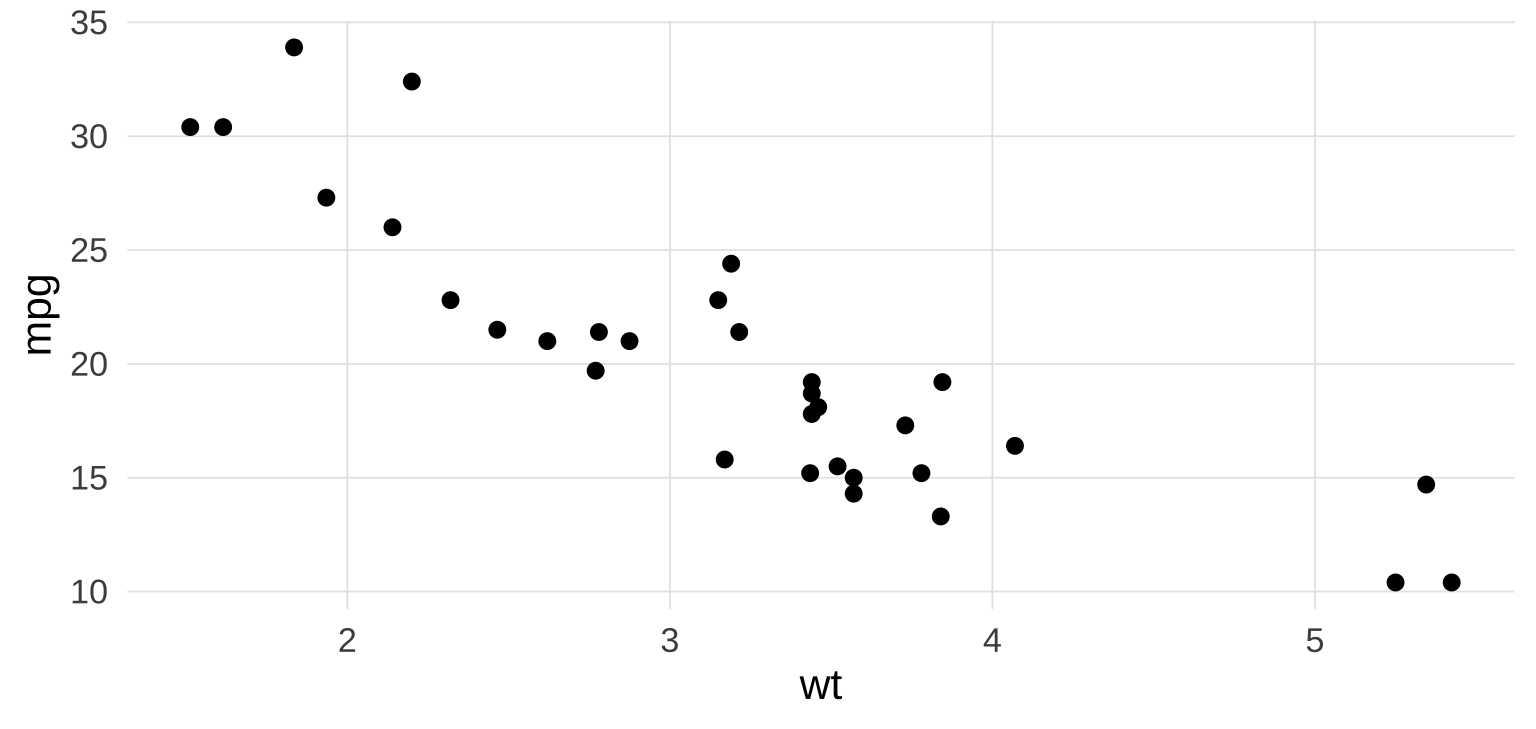
3.3 第一张 ggplot2 图
注记
这是最简单的一张散点图:提供数据、设定 x/y 映射、选择几何对象 geom_point()。其余(坐标轴范围、颜色、主题)全部使用 ggplot2 的默认值。
3.4 图层是可以叠加的
▶️ 查看代码
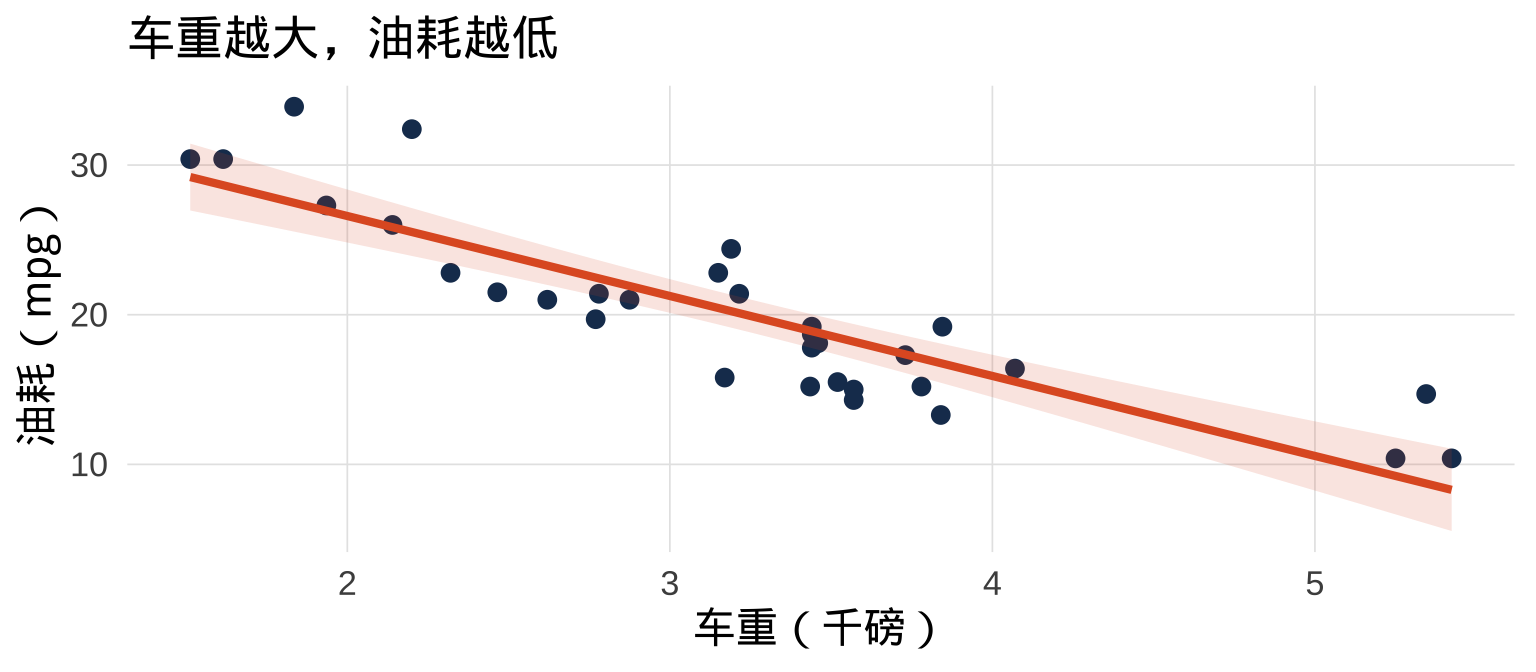
提示
geom_smooth(method = "lm") 自动拟合线性回归线,se = TRUE(默认)显示 95% 置信区间阴影。这两层的 aes() 继承自 ggplot() 中的全局映射——不需要重复写。
4.1 geom_bar():单变量条形图
geom_bar() 自动计数——只需提供 x 变量,无需预先 count():
▶️ 查看代码
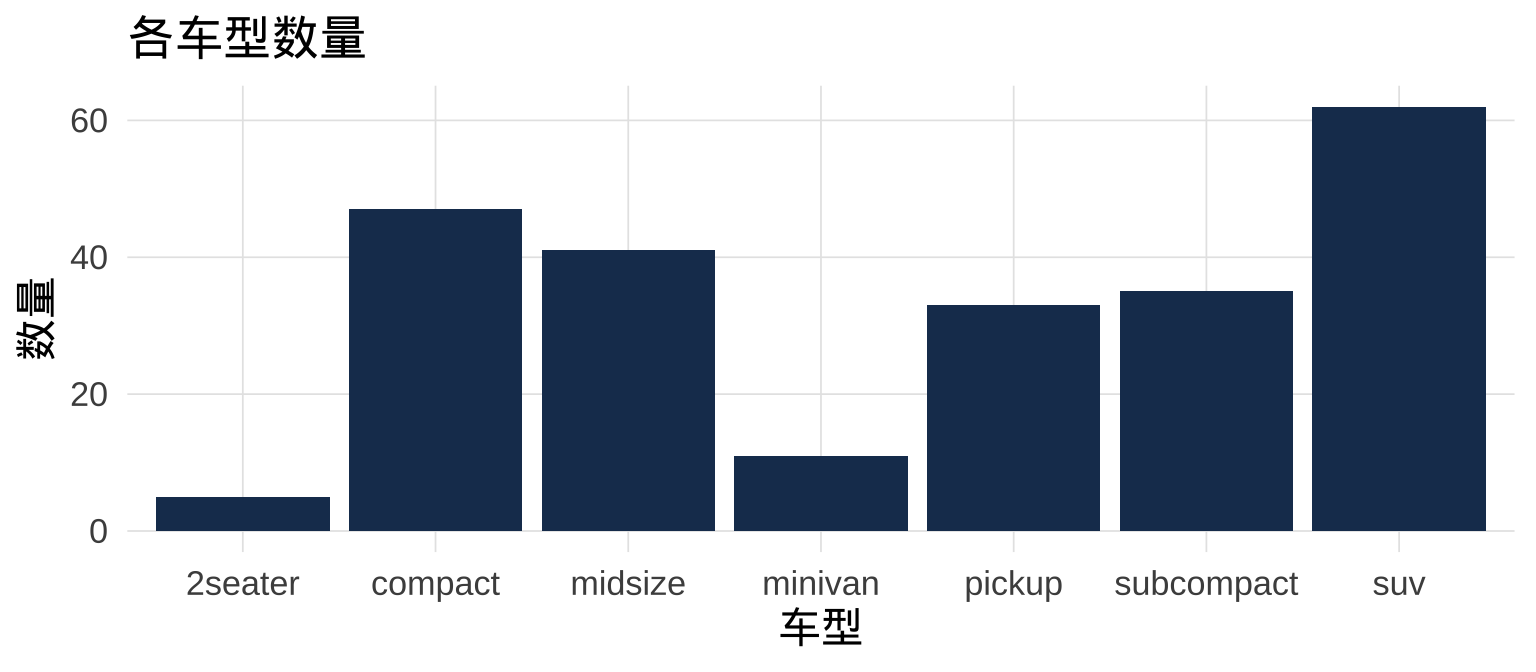
注记
mpg 是 ggplot2 内置数据集,记录 234 辆汽车的燃油效率。geom_bar() 等价于先 count() 再作图,内部调用 stat_count() 自动完成计数。
4.2 geom_col():已有计数时用这个
当数据已经是汇总好的计数/均值时,用 geom_col()(需同时提供 x 和 y):
▶️ 查看代码
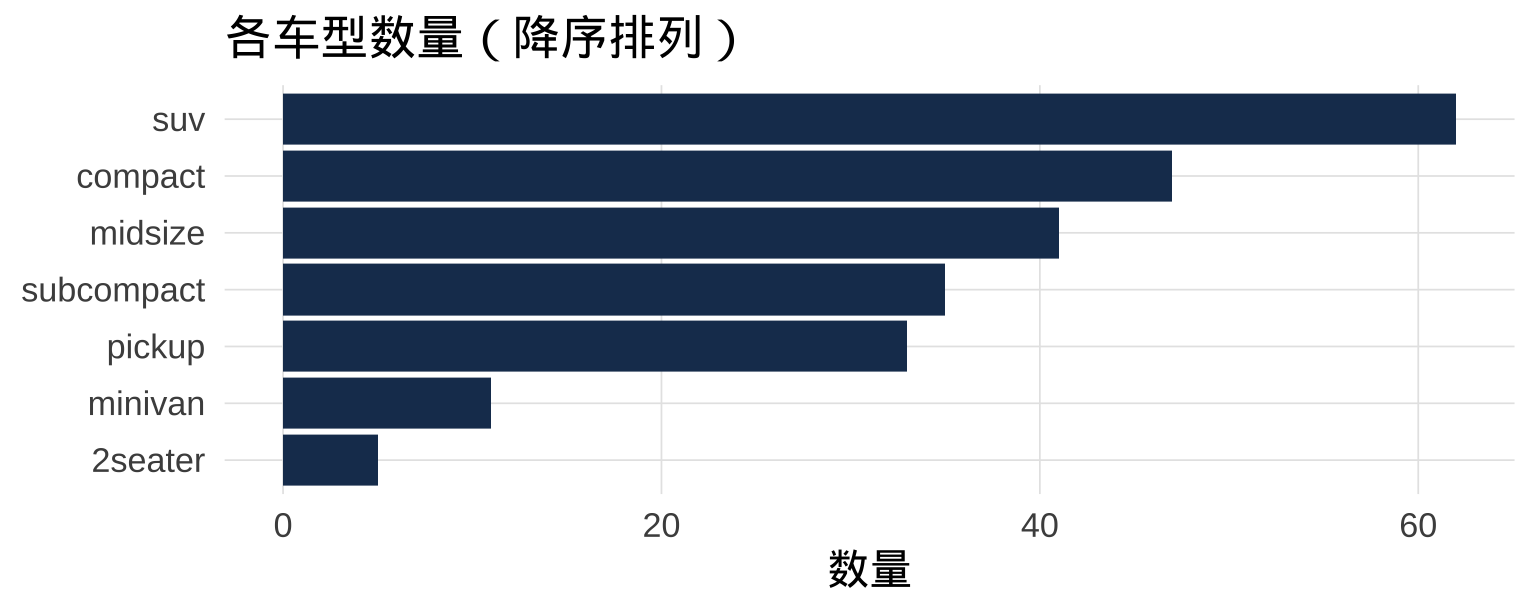
提示
reorder(因子列, 排序依据) 是让条形图按数值大小排序的最简洁写法。将 x/y 互换(横向条形图)读起来往往更清晰,尤其是类别名称较长时。
4.3 添加数值标签:geom_text() / geom_label()
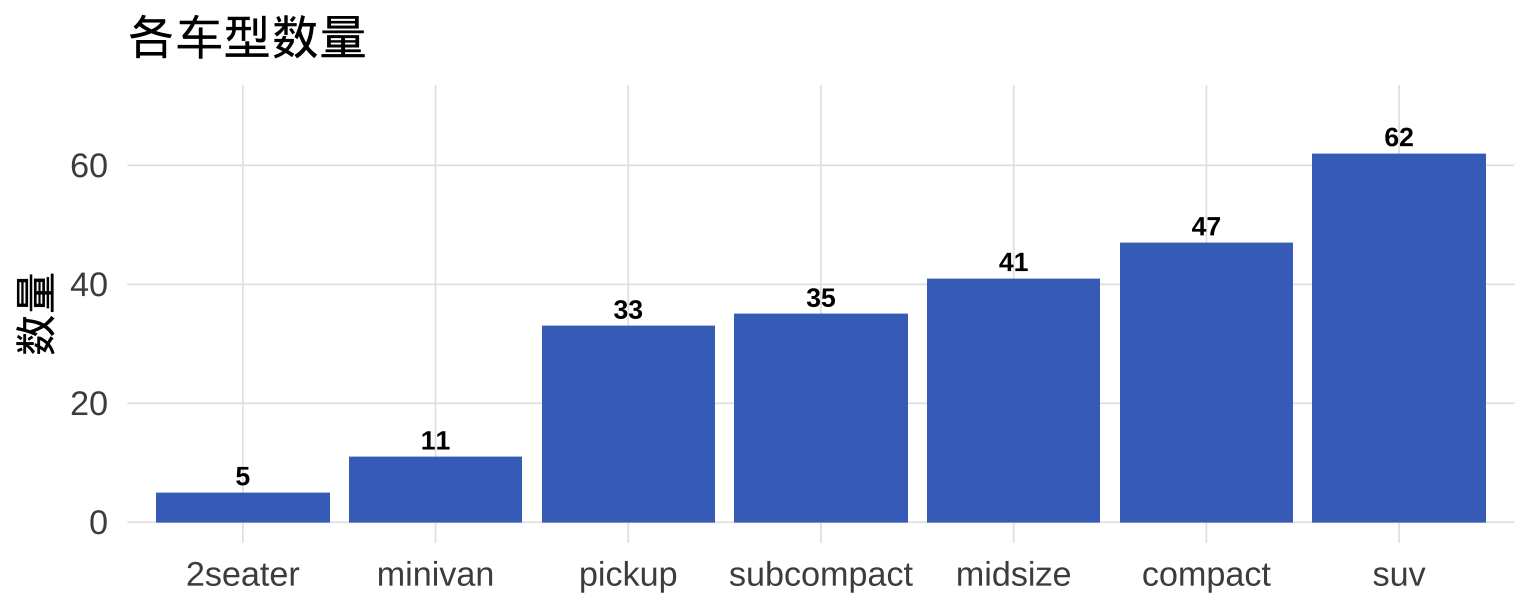
4.4 百分比条形图:先转换再作图
▶️ 查看代码
mpg |>
count(class) |>
mutate(pct = n / sum(n),
pct_label = scales::percent(pct, accuracy = 1)) |>
ggplot(aes(x = pct, y = reorder(class, pct))) +
geom_col(fill = "#1a3a5c") +
geom_text(aes(label = pct_label), hjust = -0.2, size = 3.5) +
scale_x_continuous(labels = scales::percent, limits = c(0, 0.25)) +
labs(title = "各车型占比", x = "占比", y = NULL)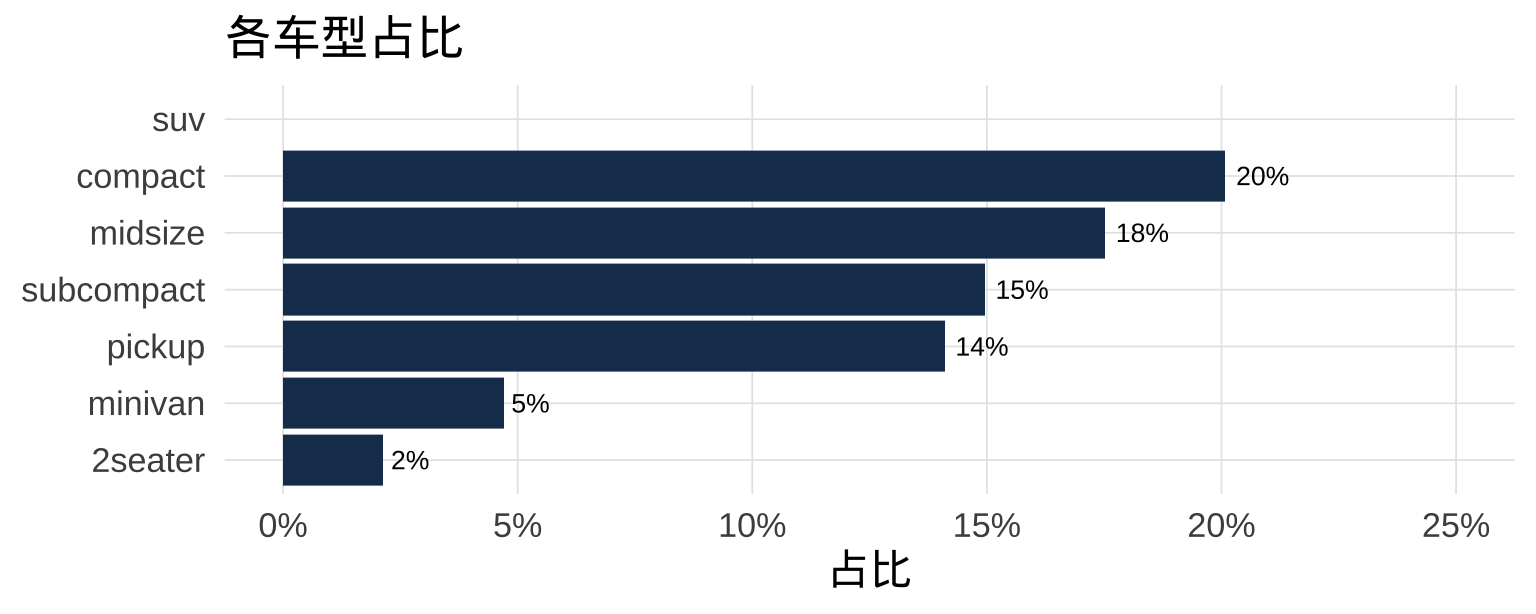
注记
scales::percent() 将小数格式化为百分比字符串(如 0.15 → "15%")。scales 包随 ggplot2 一起安装,无需单独 install.packages(),但需要 scales:: 前缀或 library(scales) 后直接调用。
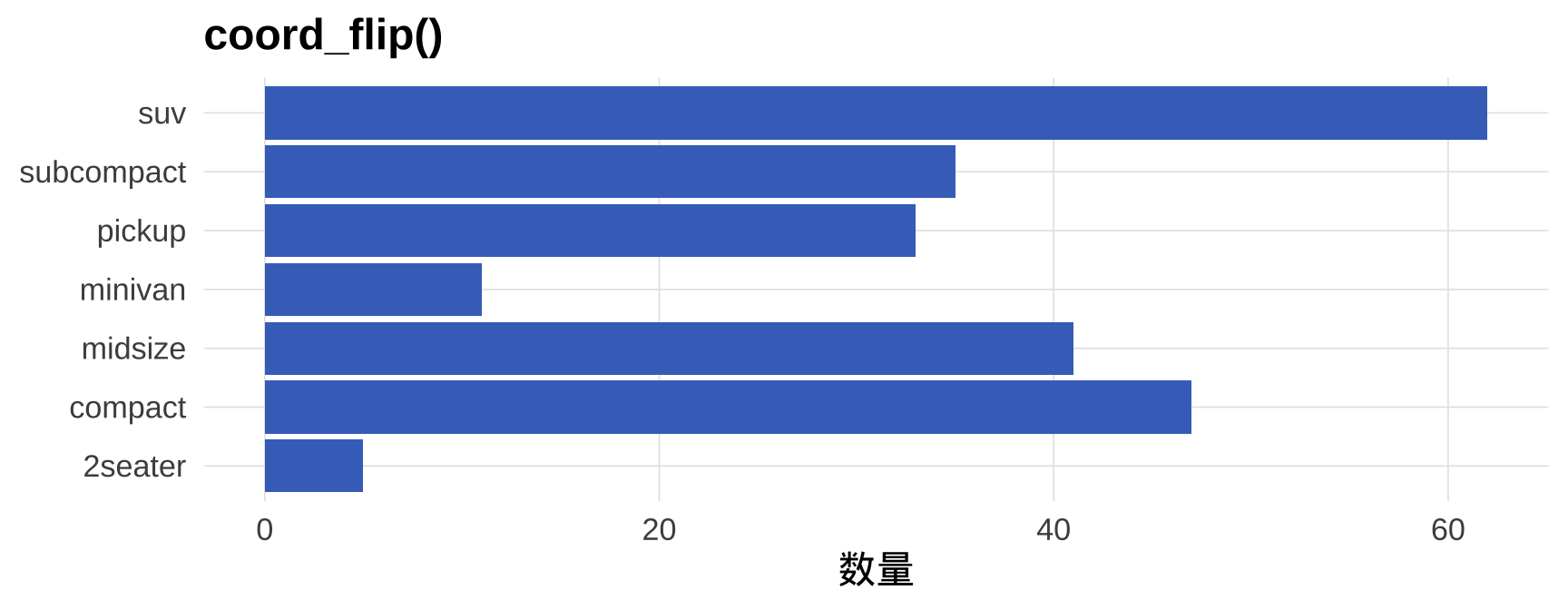
4.5 坐标翻转:coord_flip() vs 交换 x/y
▶️ 查看代码
# 交换 x/y(推荐方式,现代 ggplot2)
mpg |>
count(class) |>
ggplot(aes(x = n, y = class)) +
geom_col(fill = "#1a3a5c") +
labs(title = "交换 x/y", x = "数量", y = NULL)
# coord_flip()(旧写法,仍然有效)
mpg |>
count(class) |>
ggplot(aes(x = class, y = n)) +
geom_col(fill = "#4472C4") +
coord_flip() +
labs(title = "coord_flip()", x = NULL, y = "数量")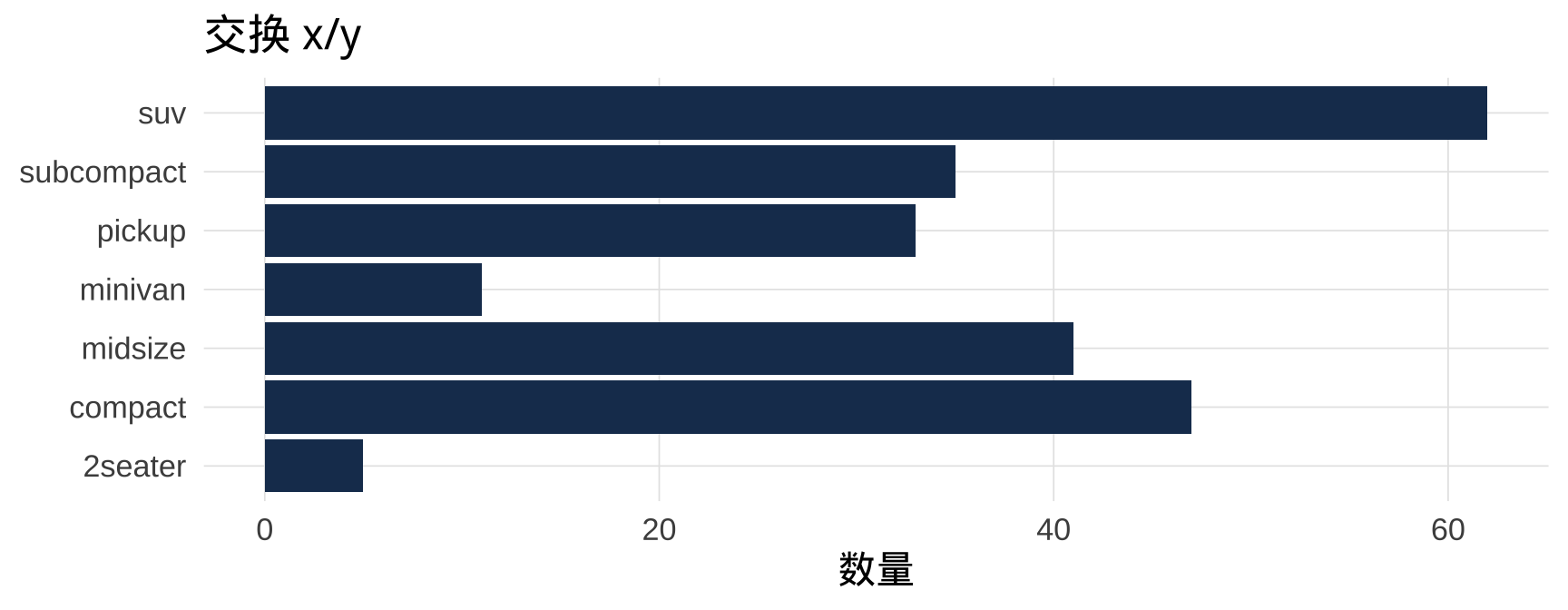
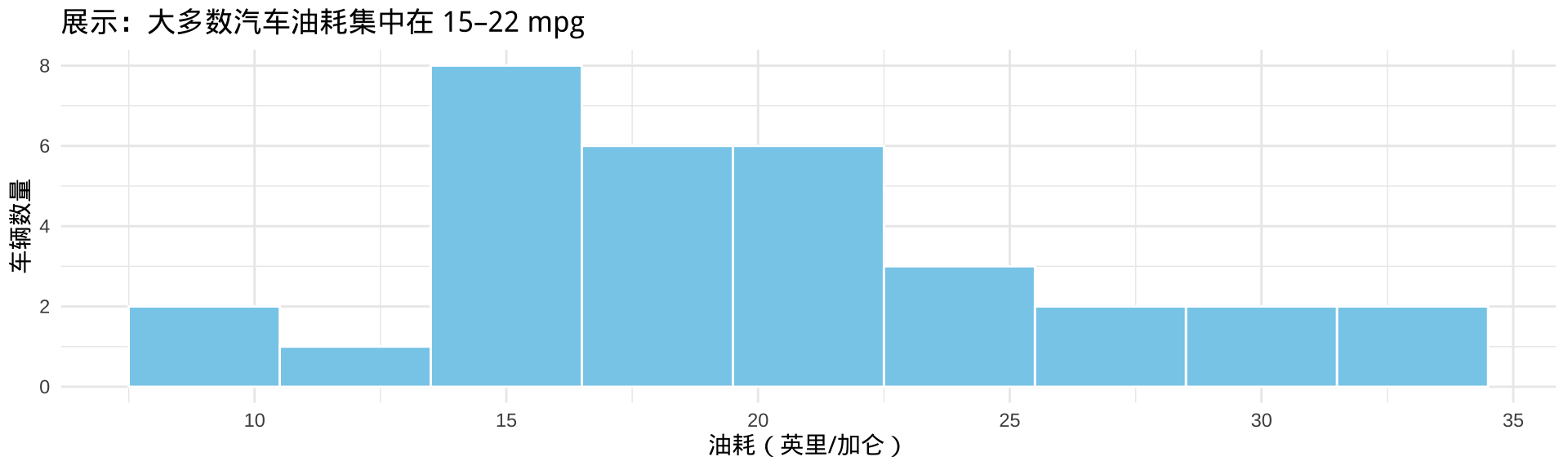
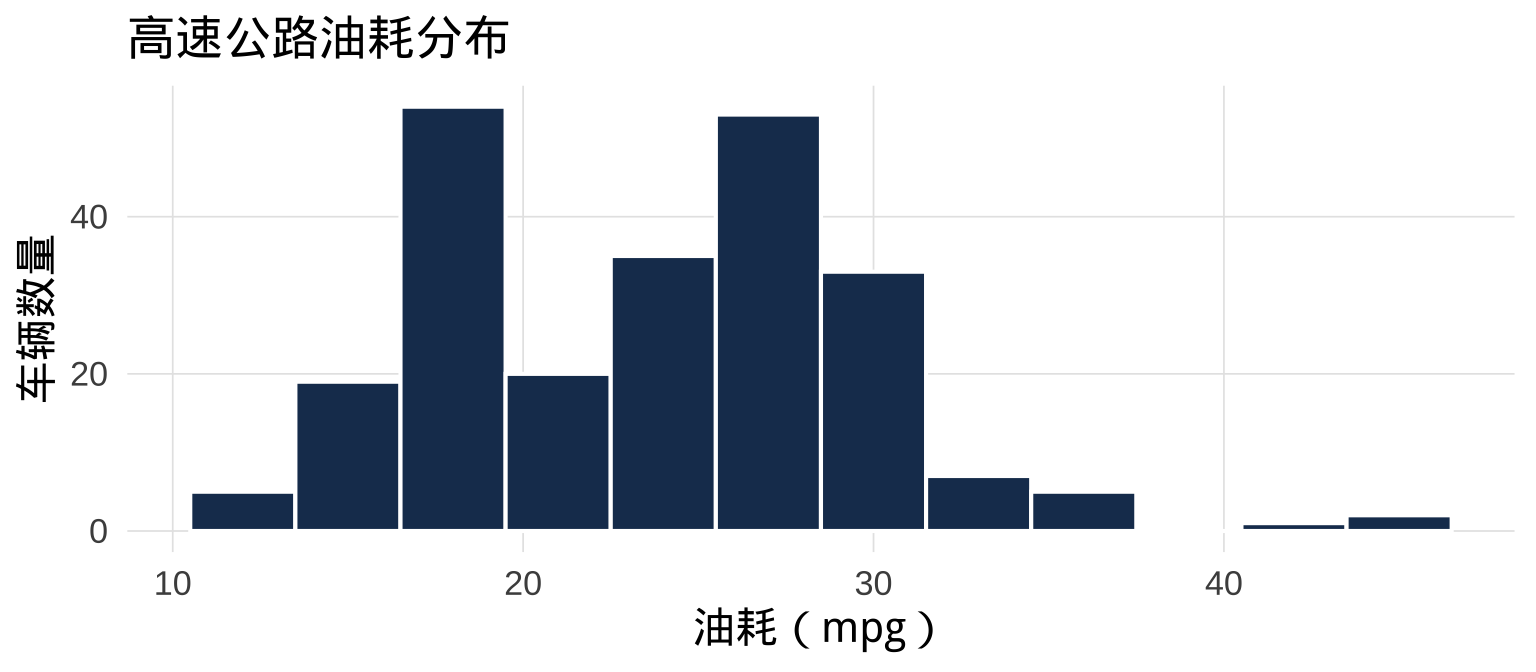
5.1 geom_histogram():直方图
直方图展示数值变量的频率分布——最常用的探索工具之一:
▶️ 查看代码
注记
binwidth(区间宽度)是直方图最重要的参数,没有通用最优值。经验法则:先用 bins = 30(默认),再根据分布形态调整。太少的箱会掩盖细节,太多会产生噪音。
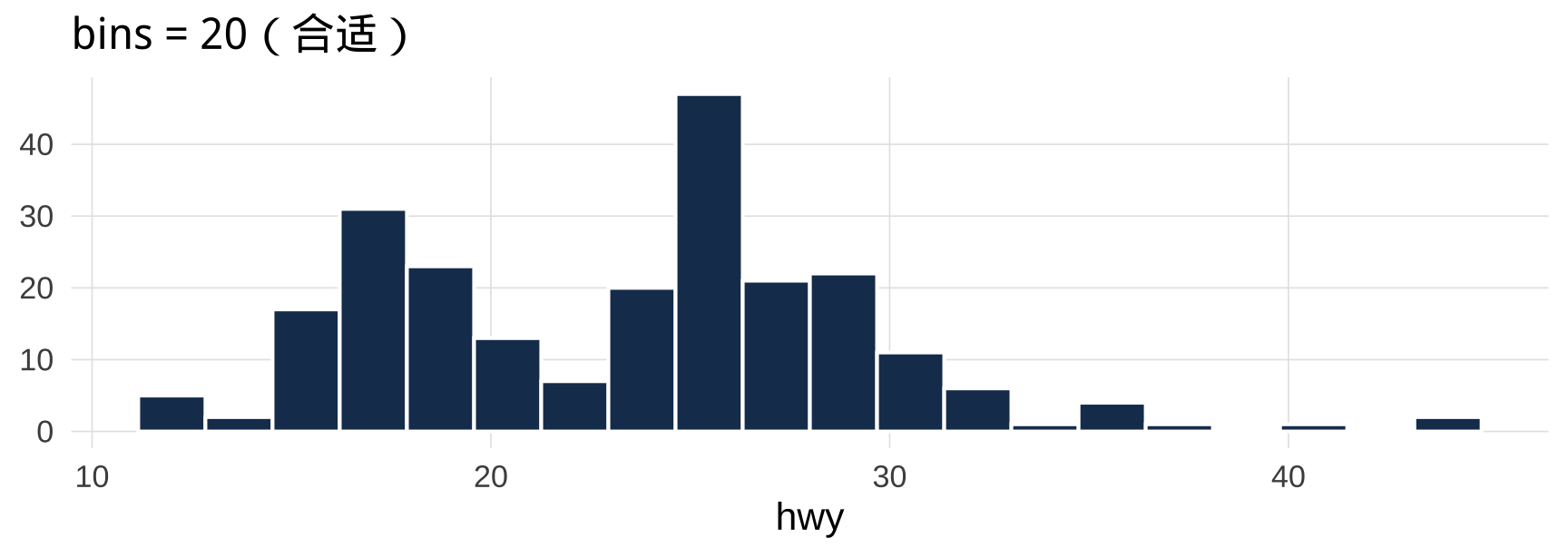
5.2 bins 参数的影响
▶️ 查看代码
ggplot(mpg, aes(x = hwy)) +
geom_histogram(bins = 5, fill = "#1a3a5c", color = "white") +
labs(title = "bins = 5(太粗)", x = "hwy", y = NULL)
ggplot(mpg, aes(x = hwy)) +
geom_histogram(bins = 20, fill = "#1a3a5c", color = "white") +
labs(title = "bins = 20(合适)", x = "hwy", y = NULL)
ggplot(mpg, aes(x = hwy)) +
geom_histogram(bins = 80, fill = "#1a3a5c", color = "white") +
labs(title = "bins = 80(太细)", x = "hwy", y = NULL)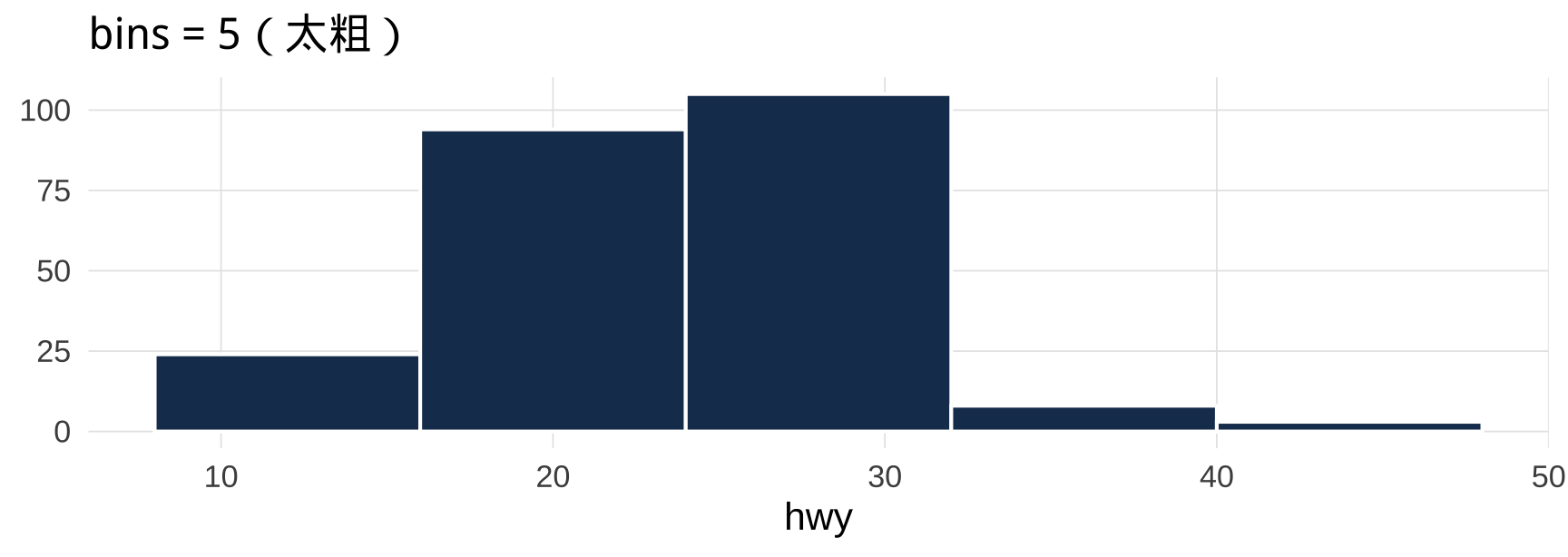
提示
没有"正确"的 bins 值——目标是如实呈现分布形态。实践中多试几个值,选最能讲清楚故事的那个。
5.3 geom_density():密度图
密度图是直方图的平滑版本,适合比较多组分布时使用:
▶️ 查看代码
注记
密度曲线下面积 = 1(概率密度),纵轴单位不是频次而是密度。bw(带宽)参数控制平滑程度,默认由核密度估计算法自动选择。
5.4 直方图 + 密度曲线叠加
▶️ 查看代码
注记
叠加时直方图纵轴必须改为 after_stat(density),否则密度曲线(数值极小)会被压扁在底部,看不见。after_stat() 是 ggplot2 3.x 的新写法,替代旧版的 stat(density) 或 ..density..。
5.5 geom_boxplot():箱线图
箱线图用五个统计量概括分布——最小值(非异常值)、Q1、中位数、Q3、最大值,以及超出范围的异常值:
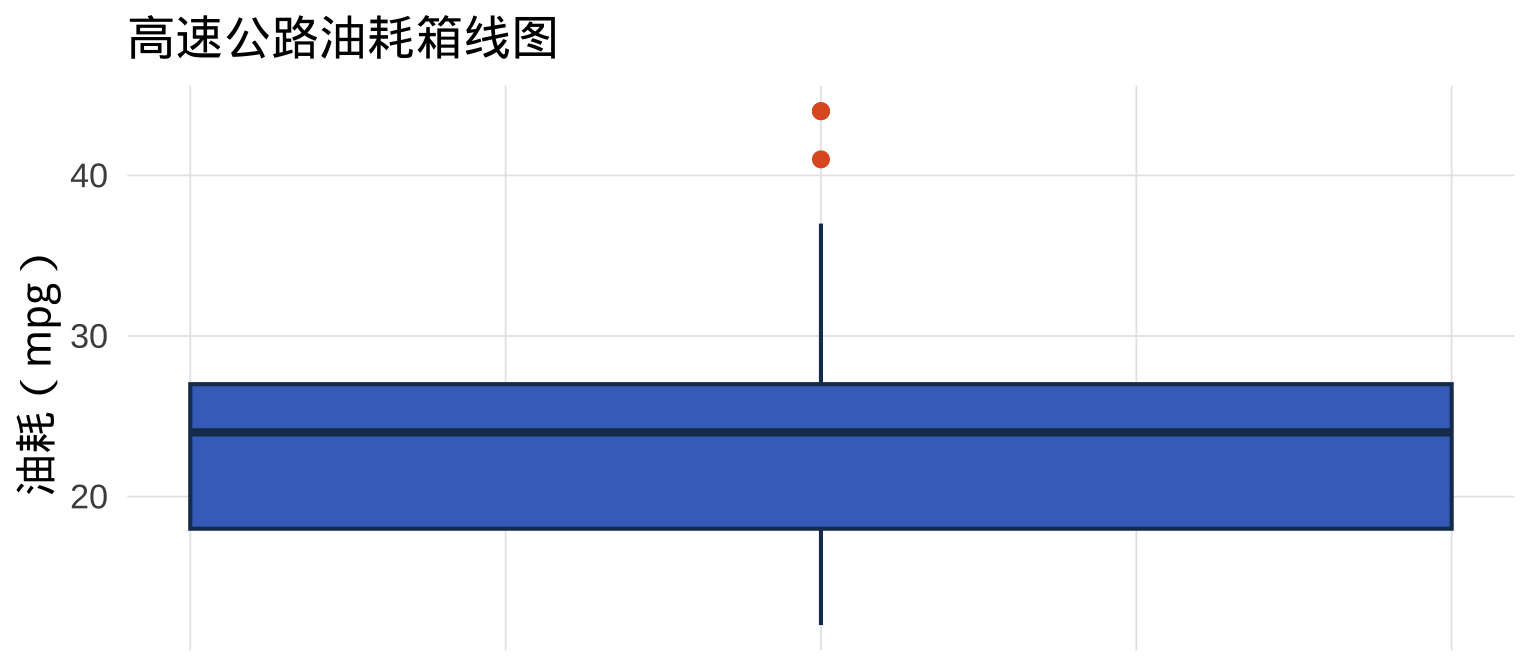
5.6 箱线图的结构解读
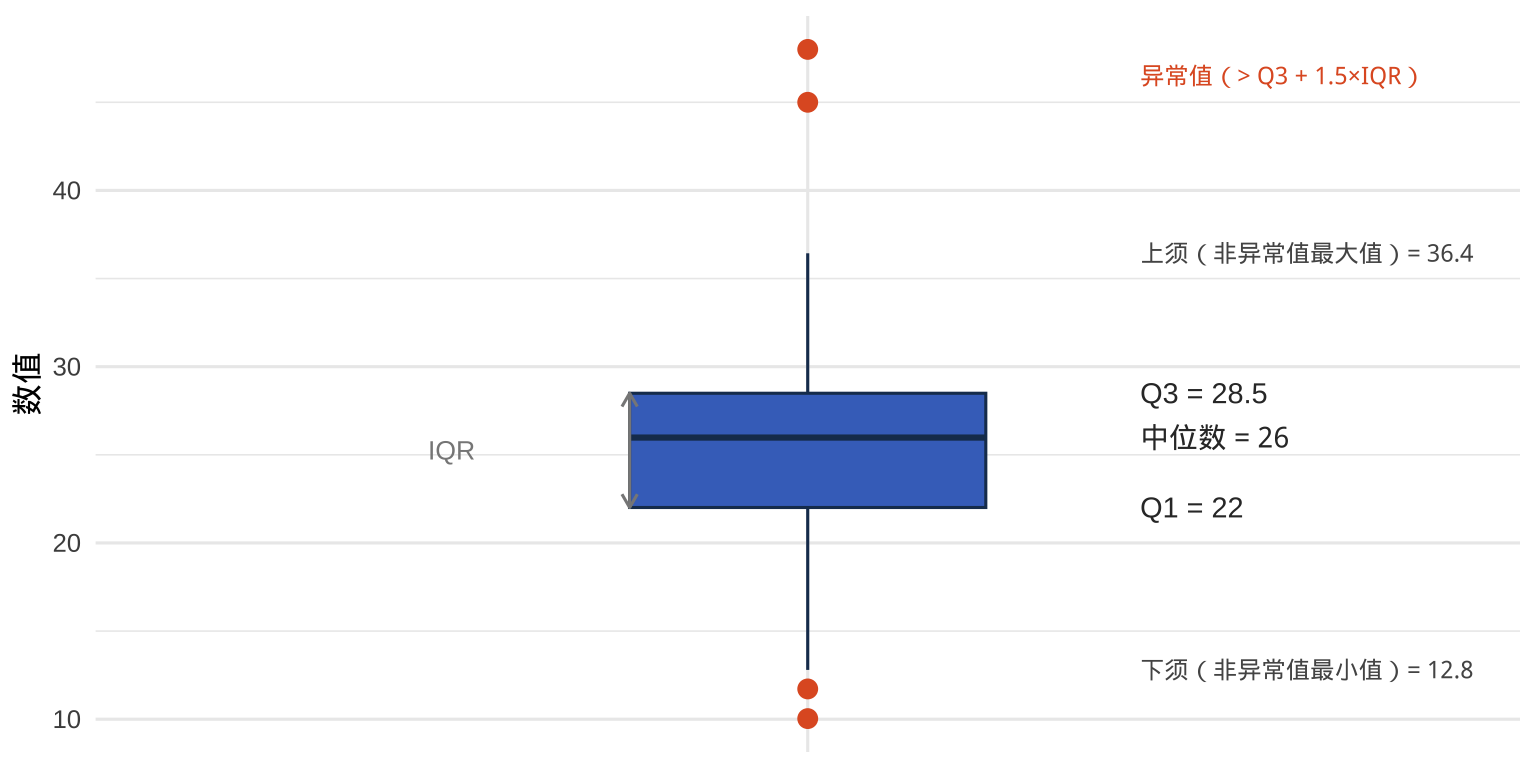
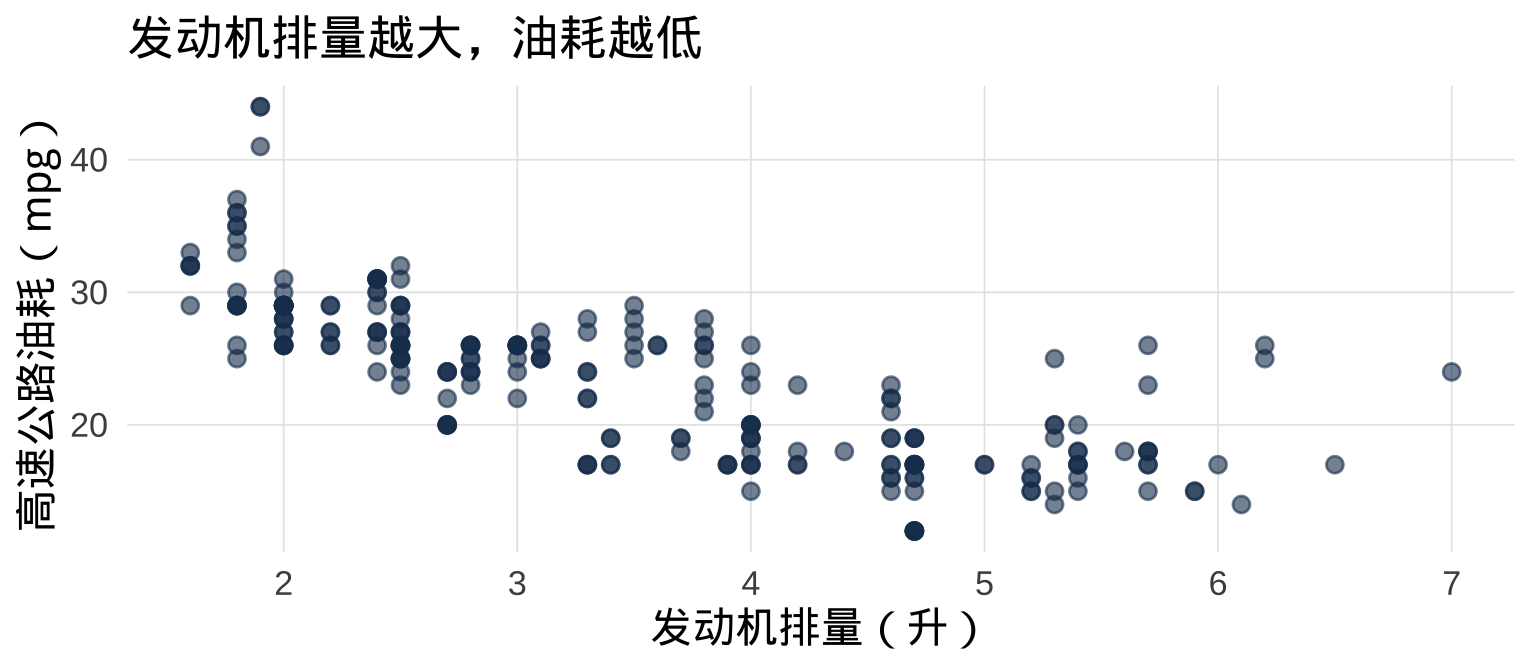
6.1 geom_point():散点图(数值 × 数值)
散点图是展示两个数值变量之间关系的首选:
6.2 散点图 + 趋势线
▶️ 查看代码
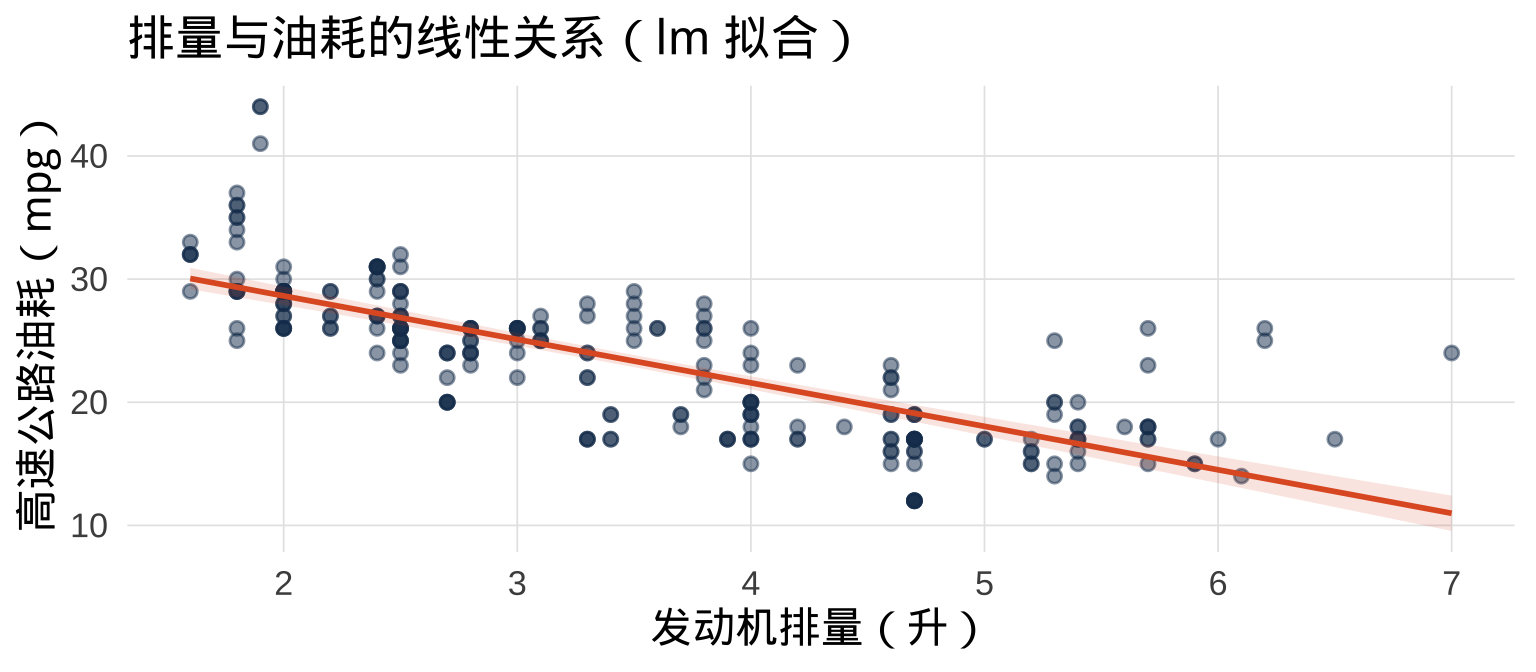
提示
method 还可以设为 "loess"(局部加权平滑,默认,捕捉非线性关系)或 "gam"(广义加法模型)。数据量 < 1000 时默认用 loess,≥ 1000 时默认用 gam。
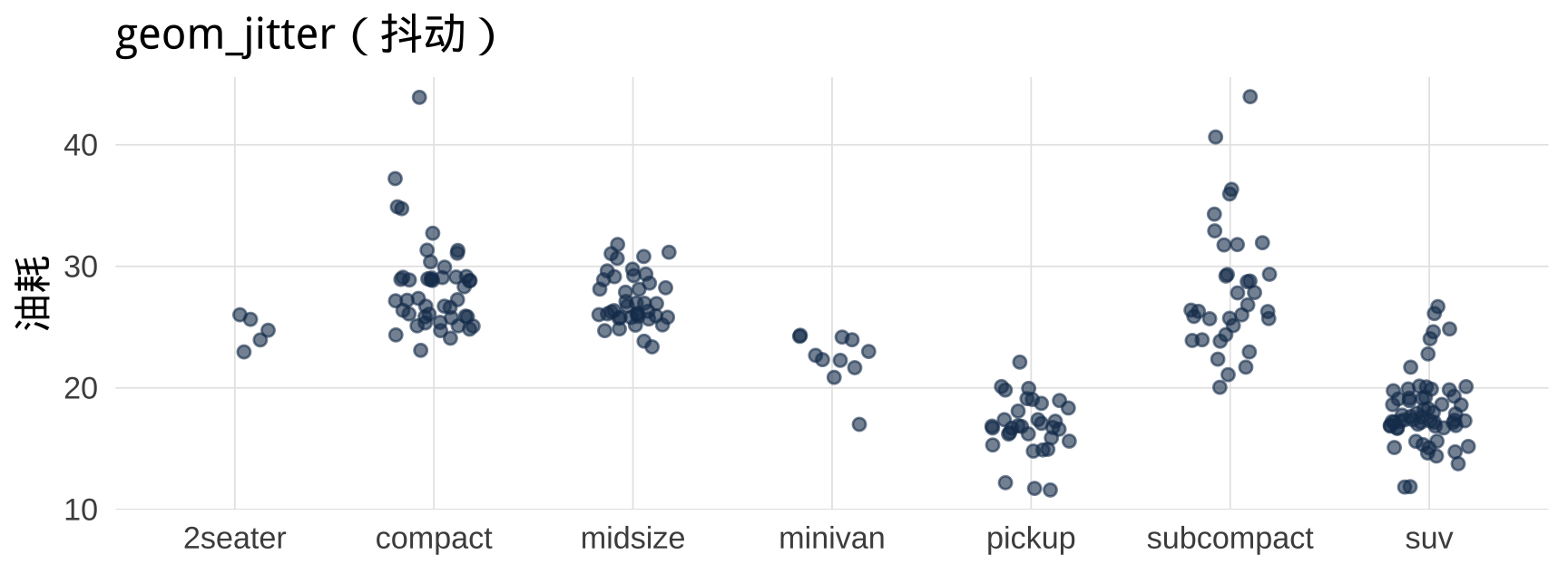
6.3 geom_jitter():处理点重叠
当数据点大量重叠时(尤其是分类 × 数值),用 geom_jitter() 添加随机抖动:
▶️ 查看代码
# 纯散点图:点重叠严重
mpg |>
ggplot(aes(x = class, y = hwy)) +
geom_point(color = "#1a3a5c") +
labs(title = "geom_point(重叠)", x = NULL, y = "油耗")
# 抖动图:清晰展示每个观测
ggplot(mpg, aes(x = class, y = hwy)) +
geom_jitter(width = 0.2, alpha = 0.6,
color = "#1a3a5c", size = 2) +
labs(title = "geom_jitter(抖动)", x = NULL, y = "油耗")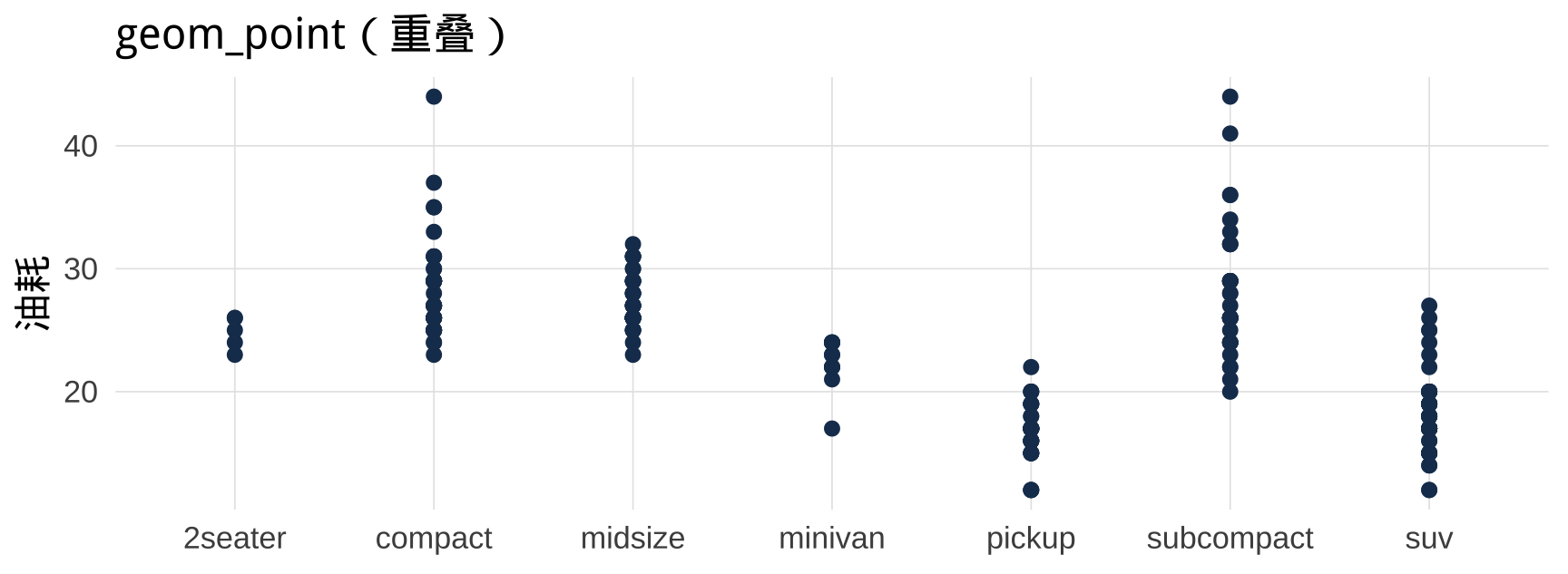
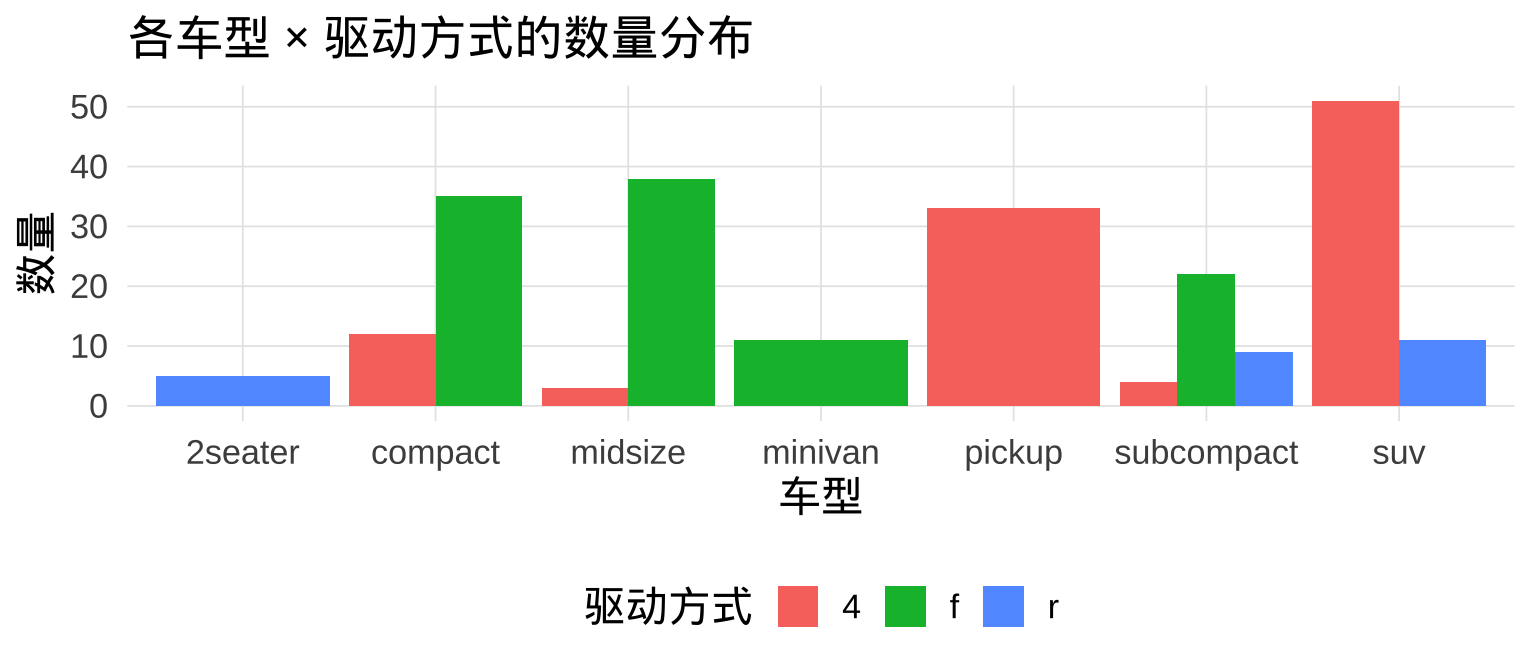
6.4 分组条形图(分类 × 分类)
用 fill 映射第二个分类变量,position = "dodge" 并排显示:
6.5 堆叠条形图与百分比堆叠
▶️ 查看代码
# 堆叠条形图(position = "stack",默认)
mpg |> count(class, drv) |>
ggplot(aes(x = class, y = n, fill = drv)) +
geom_col(position = "stack") +
labs(title = "堆叠", x = NULL, y = "数量", fill = "驱动")
# 百分比堆叠(position = "fill")
mpg |> count(class, drv) |>
ggplot(aes(x = class, y = n, fill = drv)) +
geom_col(position = "fill") +
scale_y_continuous(labels = scales::percent) +
labs(title = "百分比堆叠", x = NULL, y = "占比", fill = "驱动")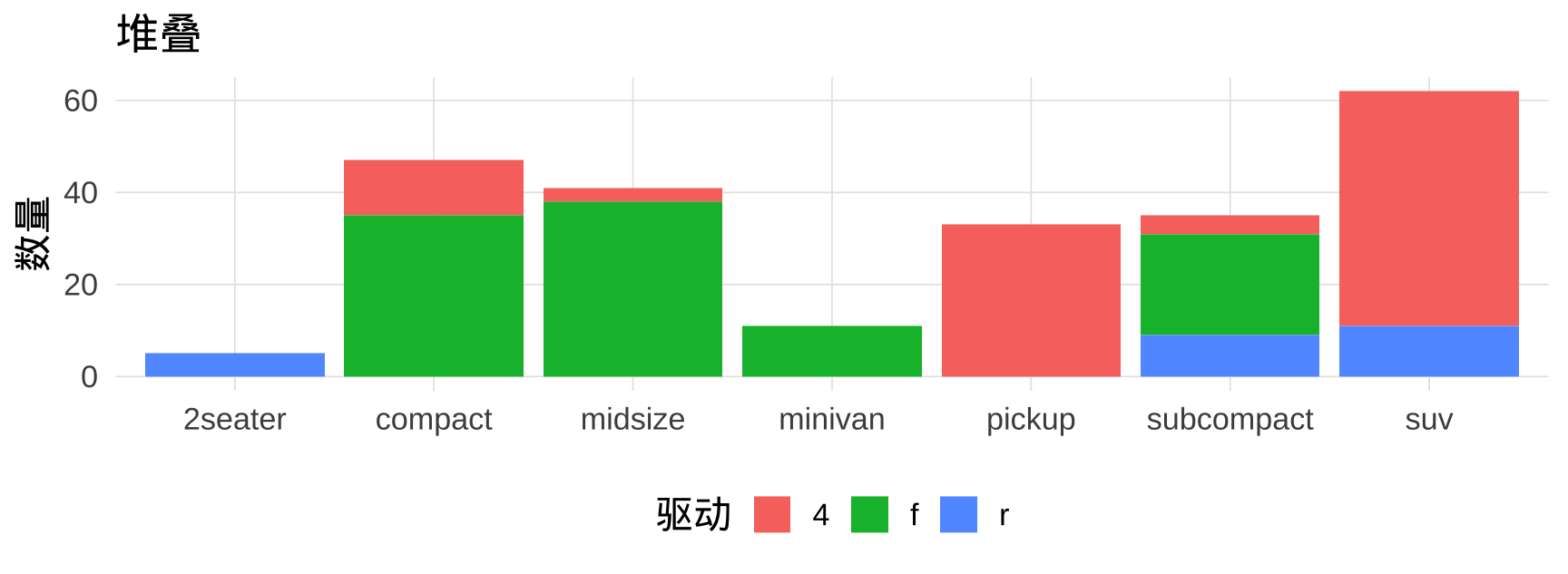
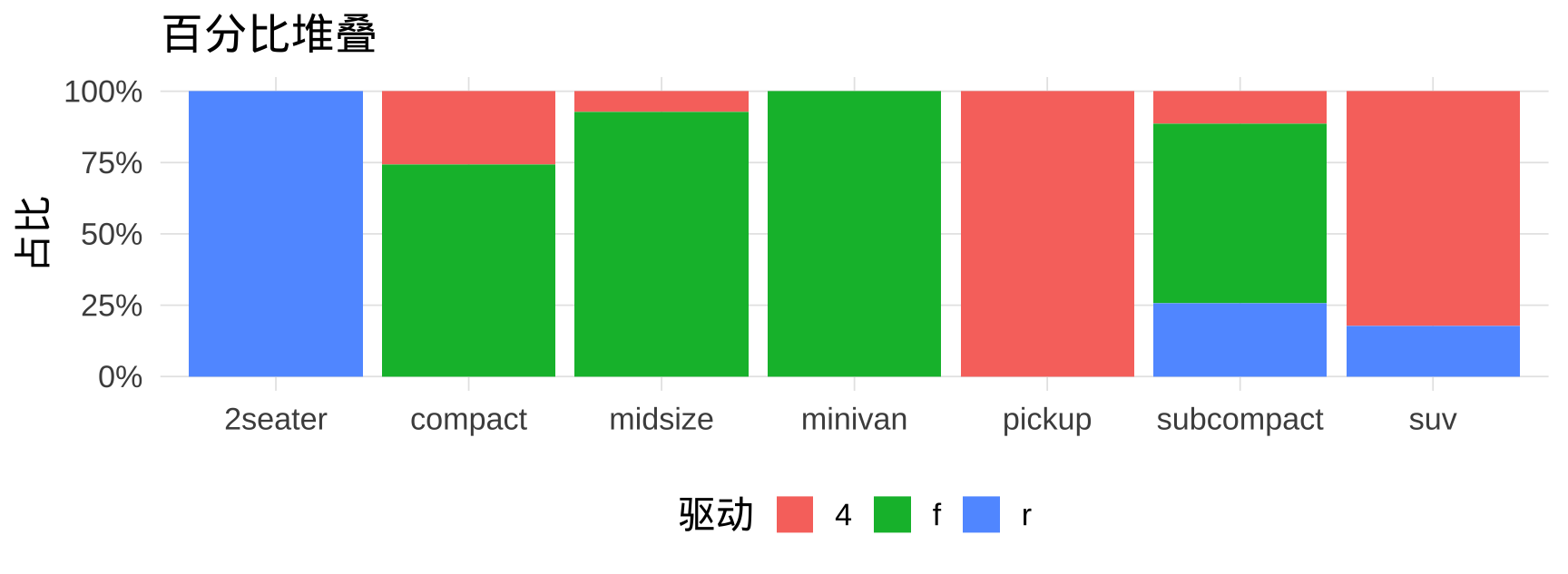
注记
position |
效果 | 适用场景 |
|---|---|---|
"dodge" |
并排 | 比较绝对数量 |
"stack" |
堆叠 | 显示整体与部分 |
"fill" |
百分比堆叠 | 比较组内构成比例 |
6.6 geom_boxplot():分组箱线图(分类 × 数值)
▶️ 查看代码
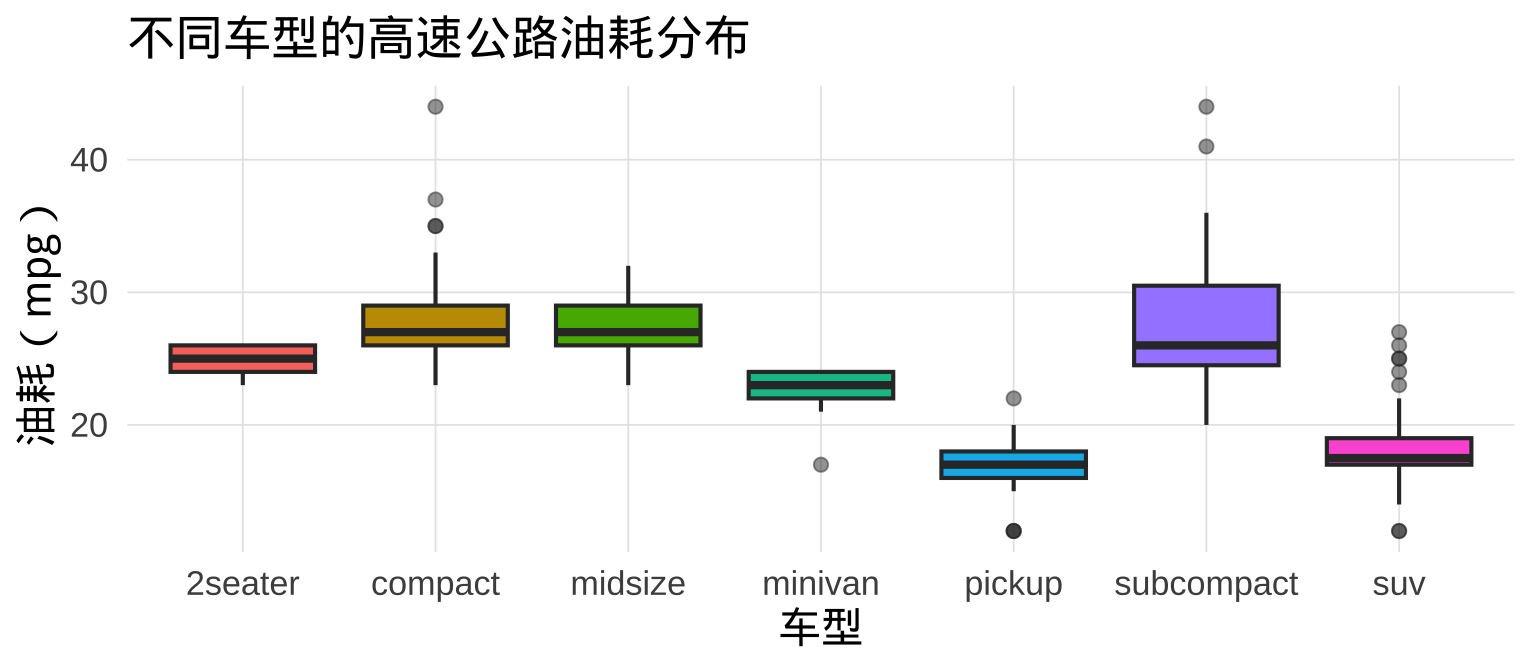
提示
将 fill 映射到 x 变量(fill = class)能自动给每个组上色,增加视觉区分度。show.legend = FALSE 避免图例重复出现。
6.7 geom_violin():小提琴图
小提琴图 = 箱线图 + 密度信息,同时展示分布的形状(峰、谷、长尾):
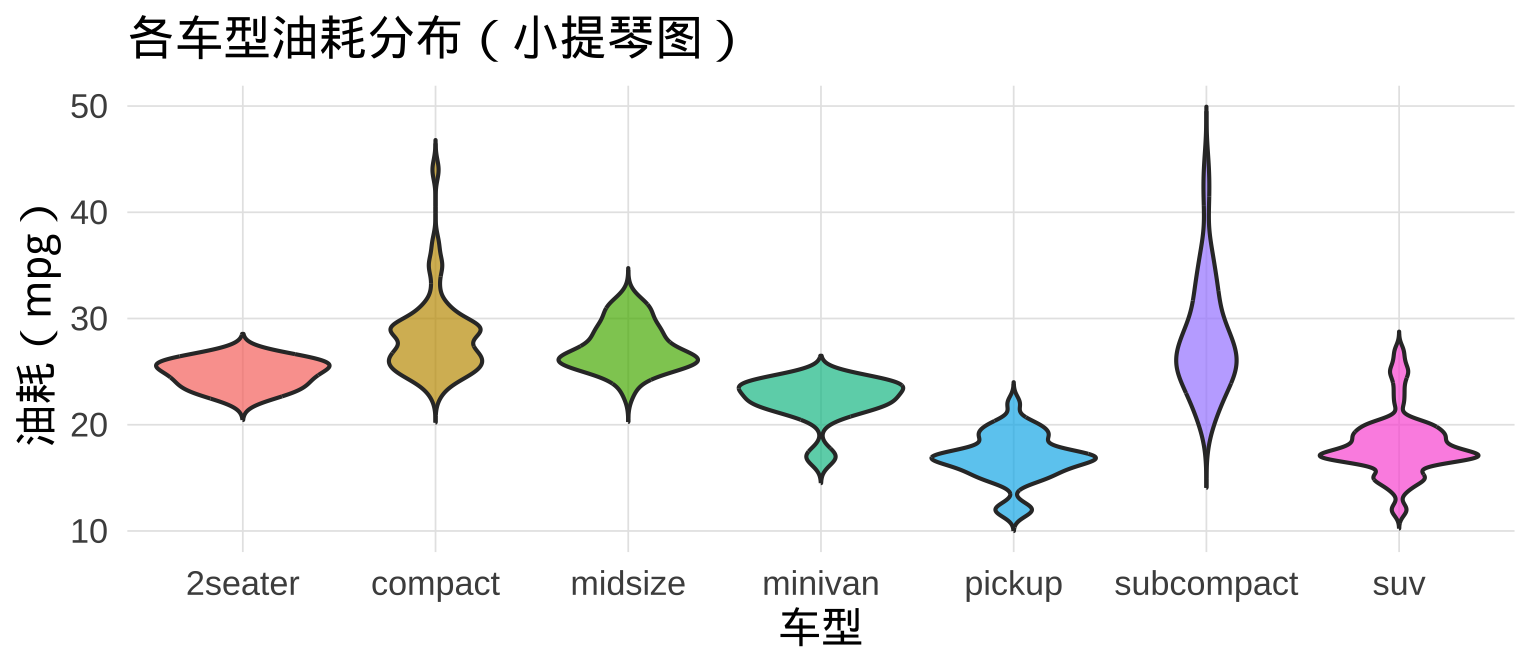
6.8 小提琴图 + 箱线图叠加
▶️ 查看代码
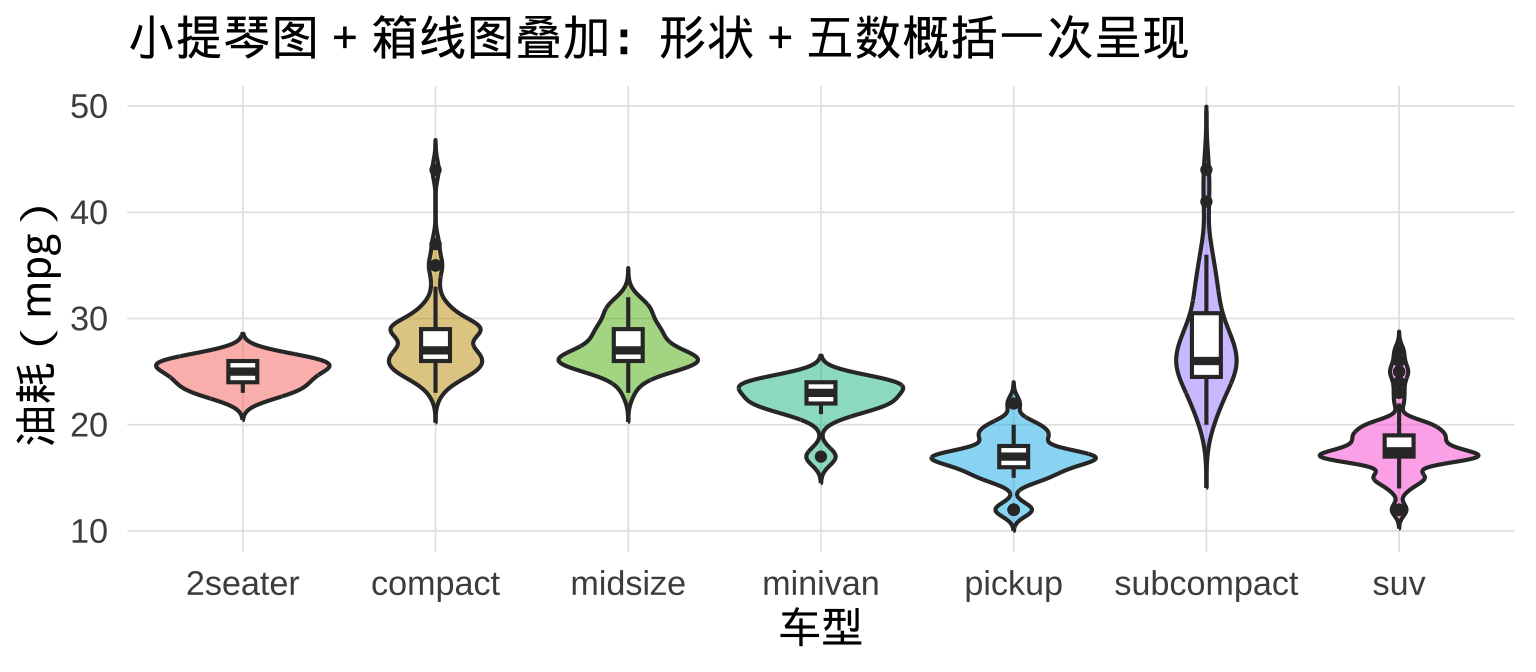
提示
叠加顺序很重要:先画 geom_violin(),再画 geom_boxplot(),箱线图才能覆盖在小提琴上面。width = 0.15 让箱线图足够细,不遮挡小提琴的轮廓。
7.1 颜色映射:第三个维度
在散点图中,将第三个变量映射到 color(分类)或 size(数值),可以同时展示三个变量的关系:
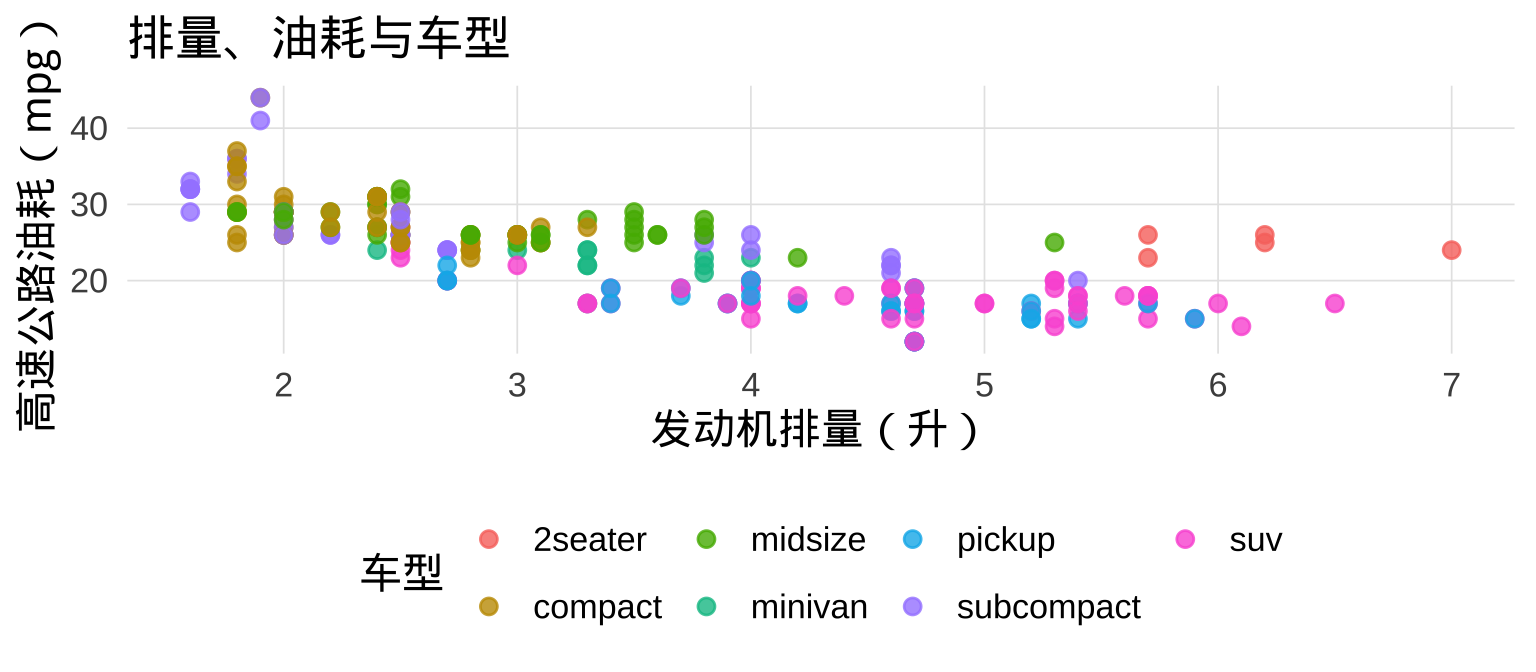
7.2 shape 与 size 映射
▶️ 查看代码
# color + shape 双重映射(黑白打印友好)
ggplot(mpg, aes(x = displ, y = hwy,
color = drv, shape = drv)) +
geom_point(size = 2.5, alpha = 0.8) +
labs(title = "color + shape 双重映射",
x = "排量", y = "油耗", color = "驱动", shape = "驱动")
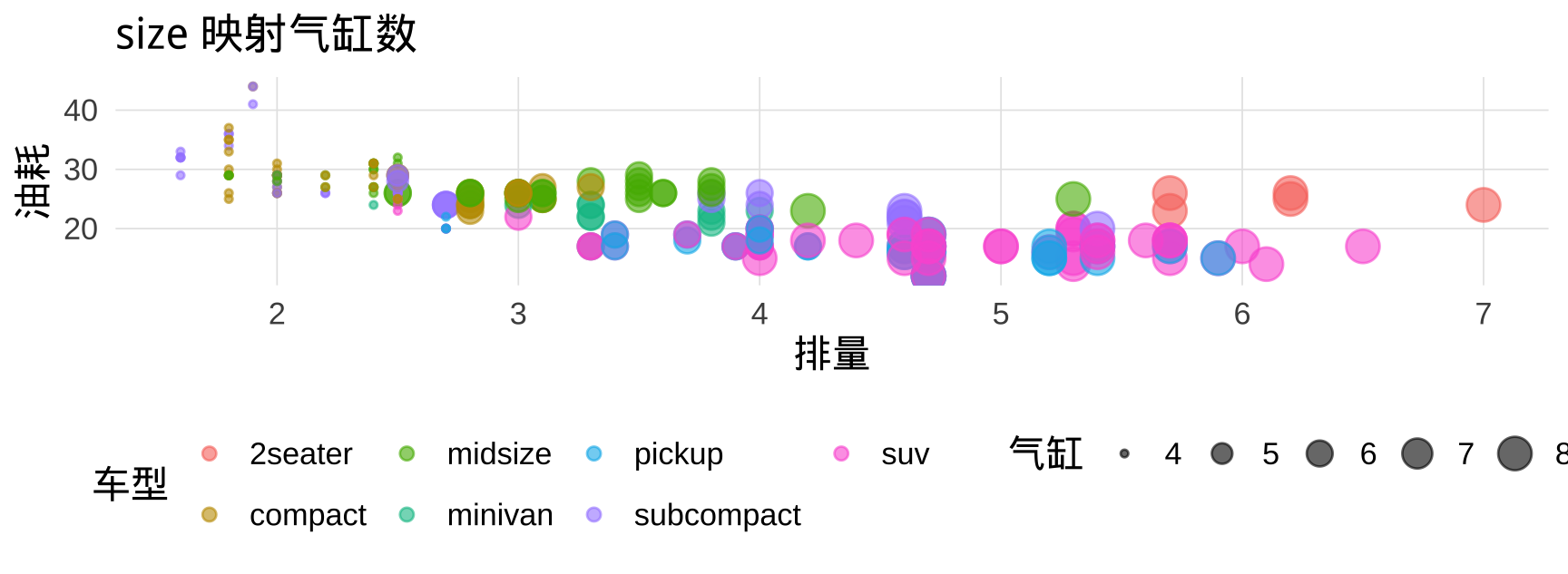
# size 映射数值变量
ggplot(mpg, aes(x = displ, y = hwy,
color = class, size = cyl)) +
geom_point(alpha = 0.6) +
labs(title = "size 映射气缸数",
x = "排量", y = "油耗",
color = "车型", size = "气缸")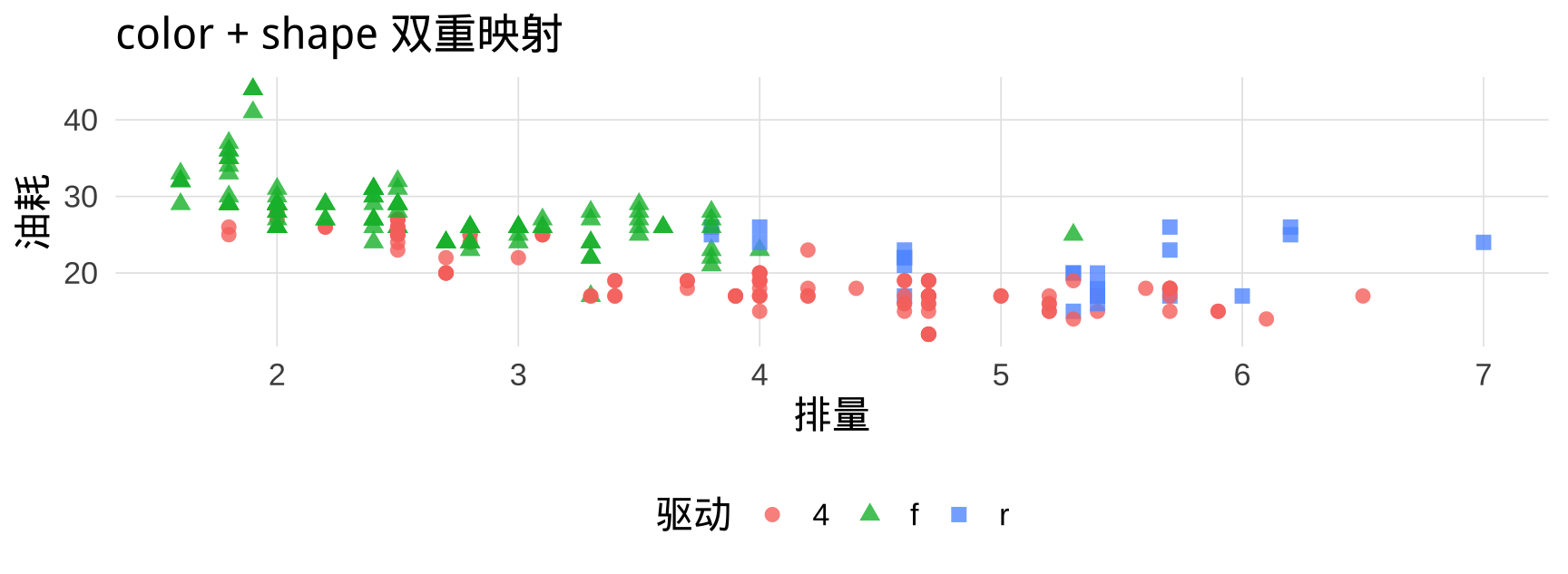
7.3 facet_wrap():单变量分面
分面(facet)将数据按某个变量拆分,在多个子图中分别绘制——是比颜色映射更清晰的多变量展示方式:
▶️ 查看代码
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(color = "#1a3a5c", alpha = 0.6, size = 1.8) +
geom_smooth(method = "lm", se = FALSE,
color = "#e05c2a", linewidth = 0.8) +
facet_wrap(~ drv, # 按 drv 列分面
nrow = 1, # 排成一行
labeller = labeller(drv = c("4" = "四驱", "f" = "前驱", "r" = "后驱"))) +
labs(title = "不同驱动方式下:排量与油耗的关系",
x = "发动机排量(升)", y = "油耗(mpg)")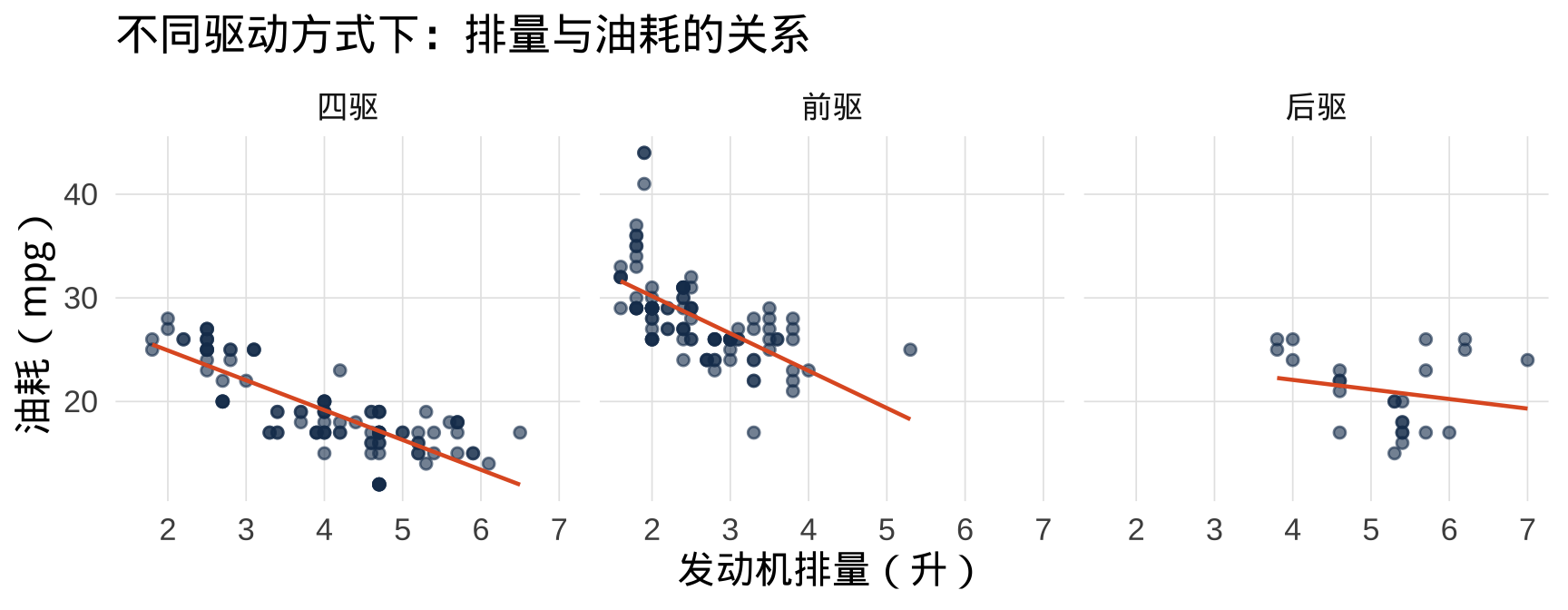
7.4 facet_grid():双变量分面
facet_grid() 按两个变量形成行列矩阵分面:
▶️ 查看代码
mpg |>
filter(class %in% c("compact", "suv", "pickup")) |>
ggplot(aes(x = displ, y = hwy)) +
geom_point(aes(color = class), alpha = 0.7, size = 2,
show.legend = FALSE) +
geom_smooth(method = "lm", se = FALSE,
color = "#333333", linewidth = 0.8) +
facet_grid(drv ~ class) + # 行:drv,列:class
labs(title = "分面矩阵:驱动方式(行)× 车型(列)",
x = "发动机排量(升)", y = "高速公路油耗(mpg)")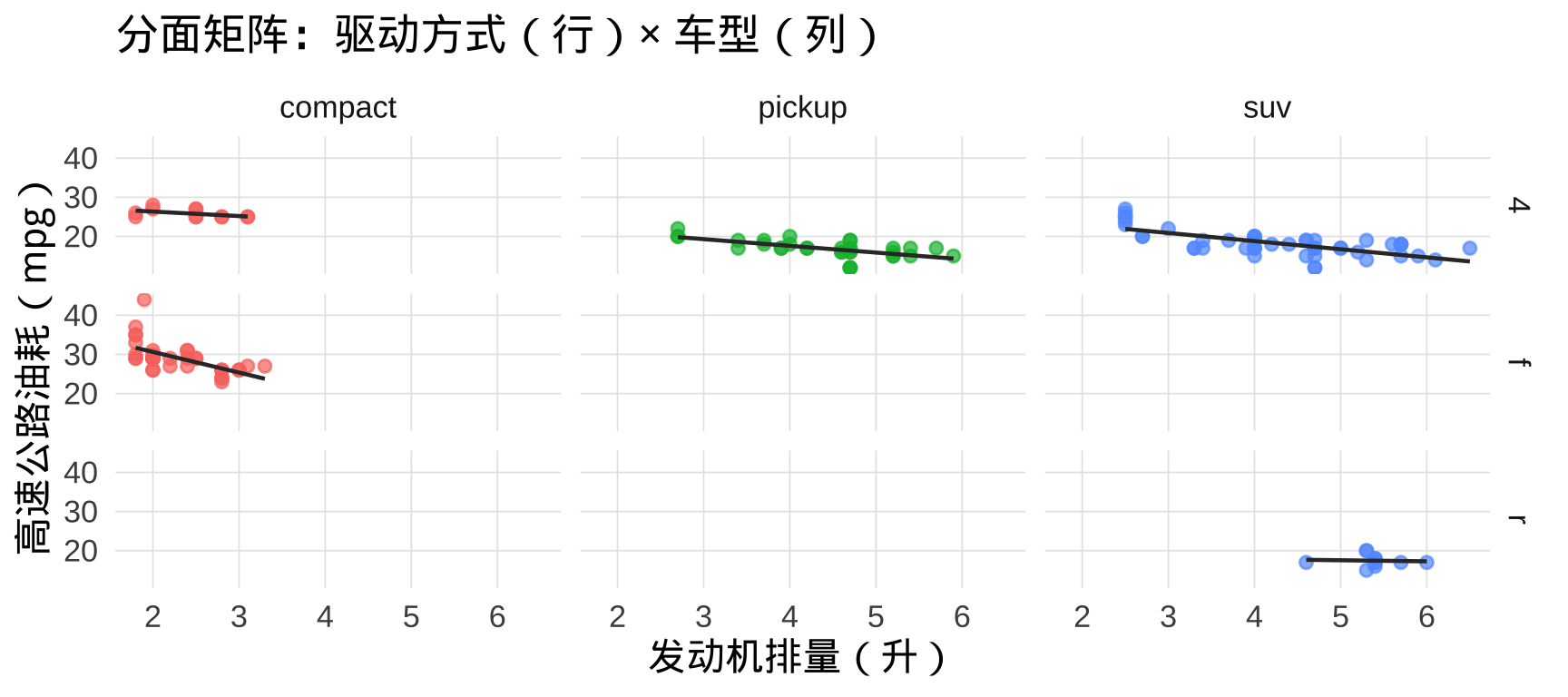
7.5 常用主题:theme_*()
ggplot2 内置多种主题,一行代码改变整体风格:
▶️ 查看代码
注记
其他常用主题:theme_bw()(黑白网格)、theme_light()(浅灰网格)、theme_dark()(深色背景)、theme_void()(无背景)。学术论文通常用 theme_classic() 或 theme_bw()。
7.6 用 labs() 完善图形信息
labs() 是添加所有文字标注的统一入口:
▶️ 查看代码
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point(size = 2.5, alpha = 0.7) +
geom_smooth(method = "lm", se = FALSE, linewidth = 0.8) +
labs(
title = "发动机排量越大,油耗越低——后驱车下降最明显", # 主标题
subtitle = "数据来源:ggplot2 内置 mpg 数据集,234 辆 1999–2008 年车型",
x = "发动机排量(升)",
y = "高速公路油耗(英里/加仑)",
color = "驱动方式",
caption = "注:4 = 四驱,f = 前驱,r = 后驱" # 图注
) +
theme_minimal(base_size = 11)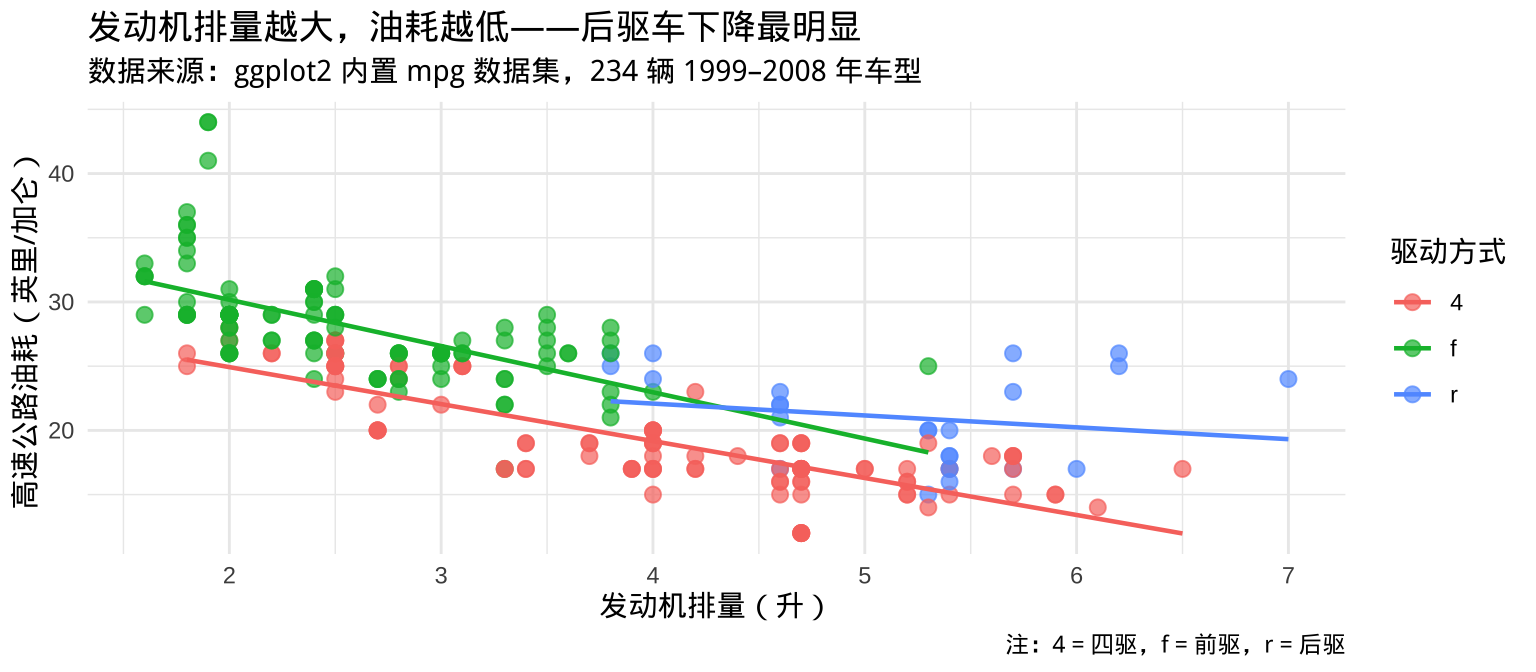
综合实战:diamonds 数据集探索
diamonds 是 ggplot2 内置数据集,含 53,940 颗钻石的价格与属性。
Rows: 53,940
Columns: 10
$ carat <dbl> 0.23, 0.21, 0.23, 0.29, 0.31, 0.24, 0.24, 0.26, 0.22, 0.23, 0.…
$ cut <ord> Ideal, Premium, Good, Premium, Good, Very Good, Very Good, Ver…
$ color <ord> E, E, E, I, J, J, I, H, E, H, J, J, F, J, E, E, I, J, J, J, I,…
$ clarity <ord> SI2, SI1, VS1, VS2, SI2, VVS2, VVS1, SI1, VS2, VS1, SI1, VS1, …
$ depth <dbl> 61.5, 59.8, 56.9, 62.4, 63.3, 62.8, 62.3, 61.9, 65.1, 59.4, 64…
$ table <dbl> 55, 61, 65, 58, 58, 57, 57, 55, 61, 61, 55, 56, 61, 54, 62, 58…
$ price <int> 326, 326, 327, 334, 335, 336, 336, 337, 337, 338, 339, 340, 34…
$ x <dbl> 3.95, 3.89, 4.05, 4.20, 4.34, 3.94, 3.95, 4.07, 3.87, 4.00, 4.…
$ y <dbl> 3.98, 3.84, 4.07, 4.23, 4.35, 3.96, 3.98, 4.11, 3.78, 4.05, 4.…
$ z <dbl> 2.43, 2.31, 2.31, 2.63, 2.75, 2.48, 2.47, 2.53, 2.49, 2.39, 2.…▶️ 查看代码
# 切割质量分布(分类变量)
diamonds |>
count(cut) |>
ggplot(aes(x = n, y = reorder(cut, n))) +
geom_col(fill = "#1a3a5c") +
geom_text(aes(label = scales::comma(n)), hjust = -0.1, size = 3.2) +
xlim(0, 25000) +
labs(title = "各切割质量的钻石数量", x = "数量", y = "切割质量") +
theme_minimal()
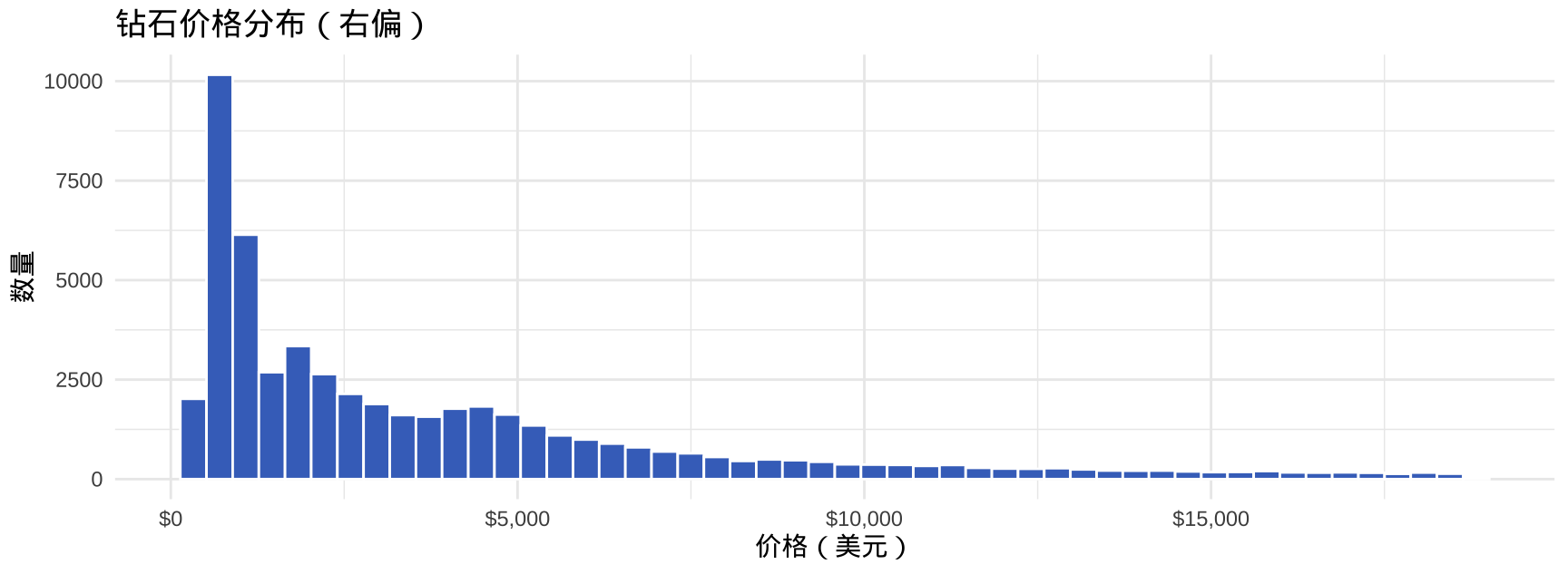
# 价格分布(数值变量)
ggplot(diamonds, aes(x = price)) +
geom_histogram(bins = 50, fill = "#4472C4", color = "white") +
scale_x_continuous(labels = scales::dollar) +
labs(title = "钻石价格分布(右偏)", x = "价格(美元)", y = "数量") +
theme_minimal()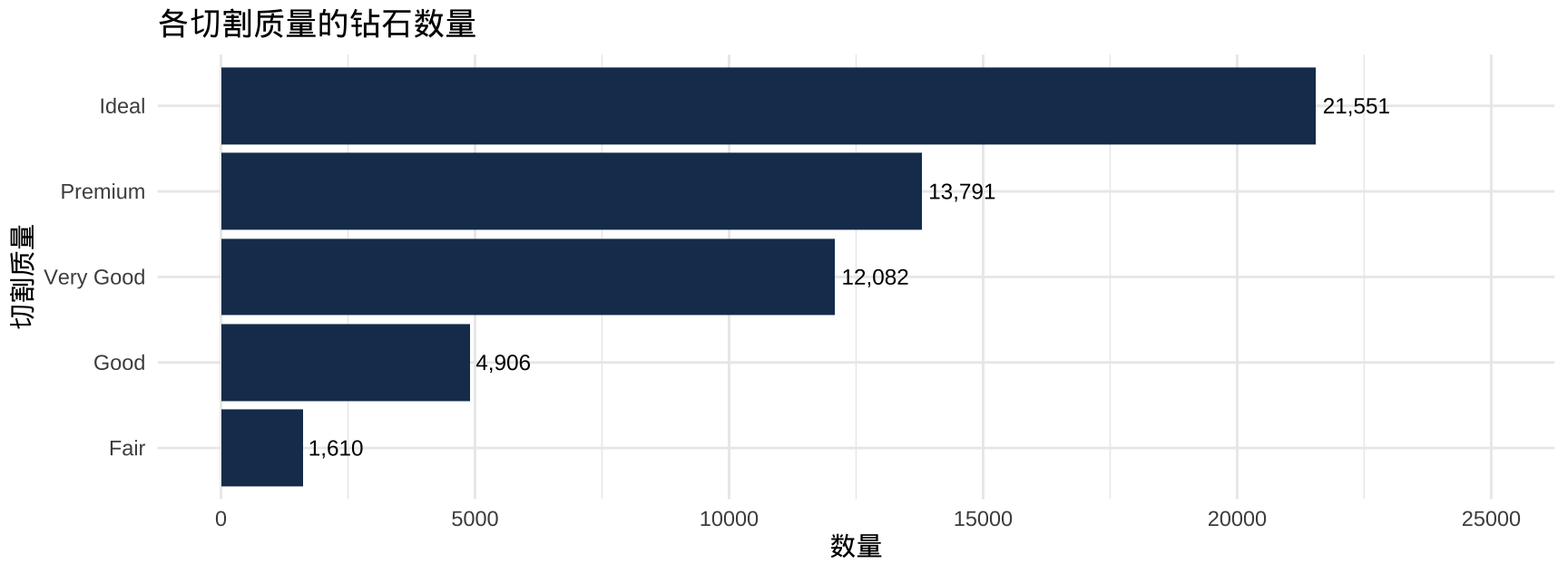
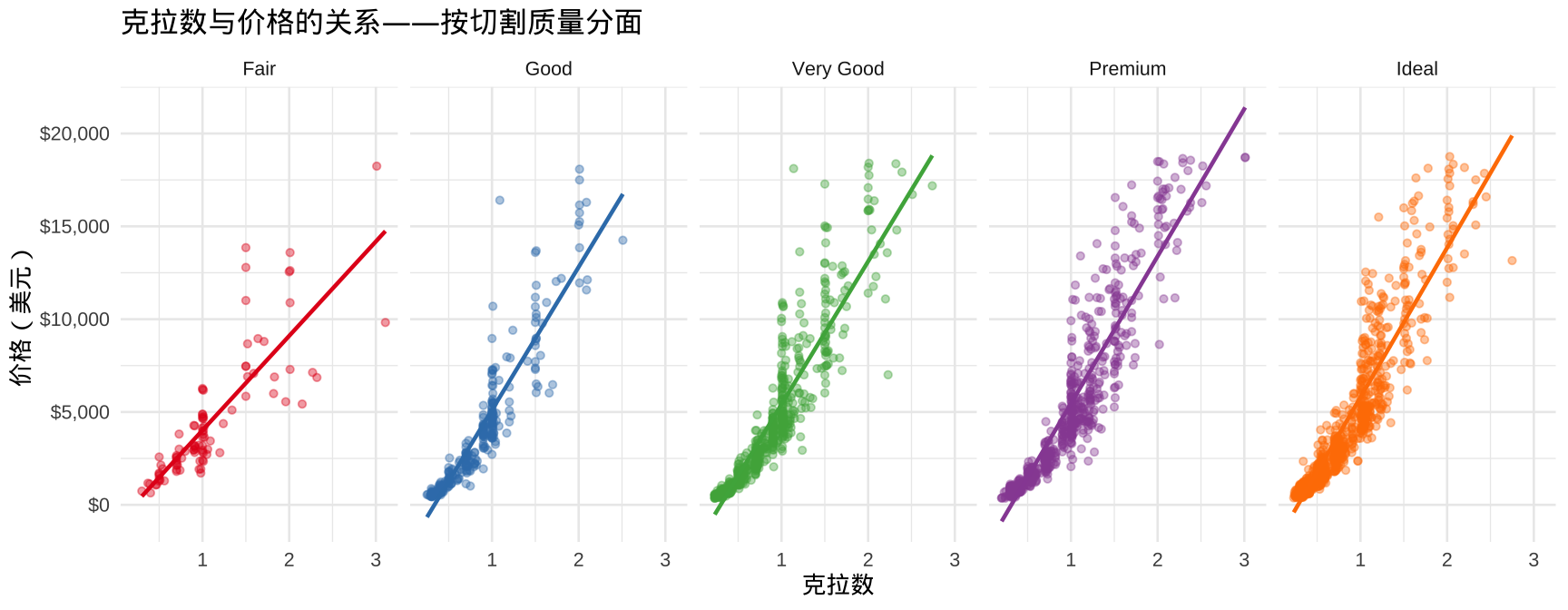
综合实战(续):多变量关系
▶️ 查看代码
# 克拉数 vs 价格,按切割质量分面
diamonds |>
sample_n(3000) |> # 随机取样,加快渲染
ggplot(aes(x = carat, y = price, color = cut)) +
geom_point(alpha = 0.4, size = 1.2) +
geom_smooth(method = "lm", se = FALSE,
linewidth = 0.8) +
scale_y_continuous(labels = scales::dollar) +
scale_color_brewer(palette = "Set1") +
facet_wrap(~ cut, nrow = 1) +
labs(title = "克拉数与价格的关系——按切割质量分面",
x = "克拉数", y = "价格(美元)",
color = "切割质量") +
theme_minimal(base_size = 10) +
theme(legend.position = "none")