数据挖掘与R语言
第9讲:统计基础
2026年04月24日
偏态的直觉
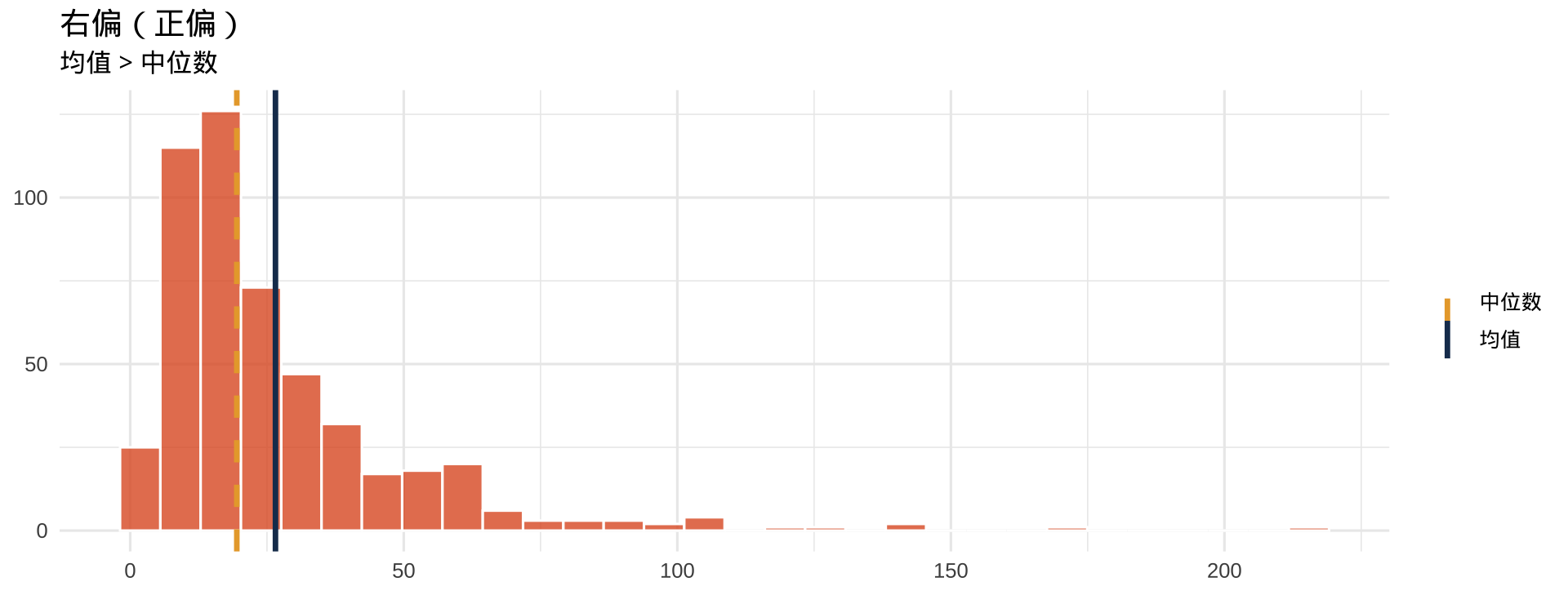
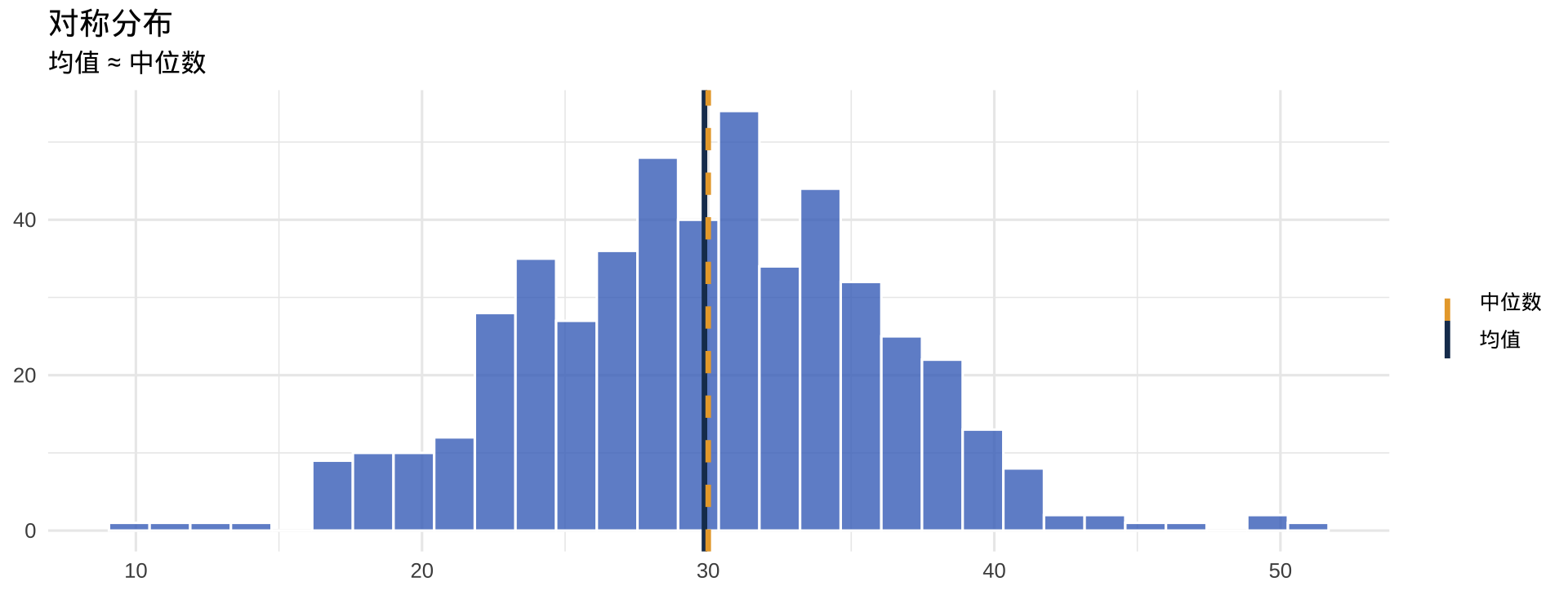
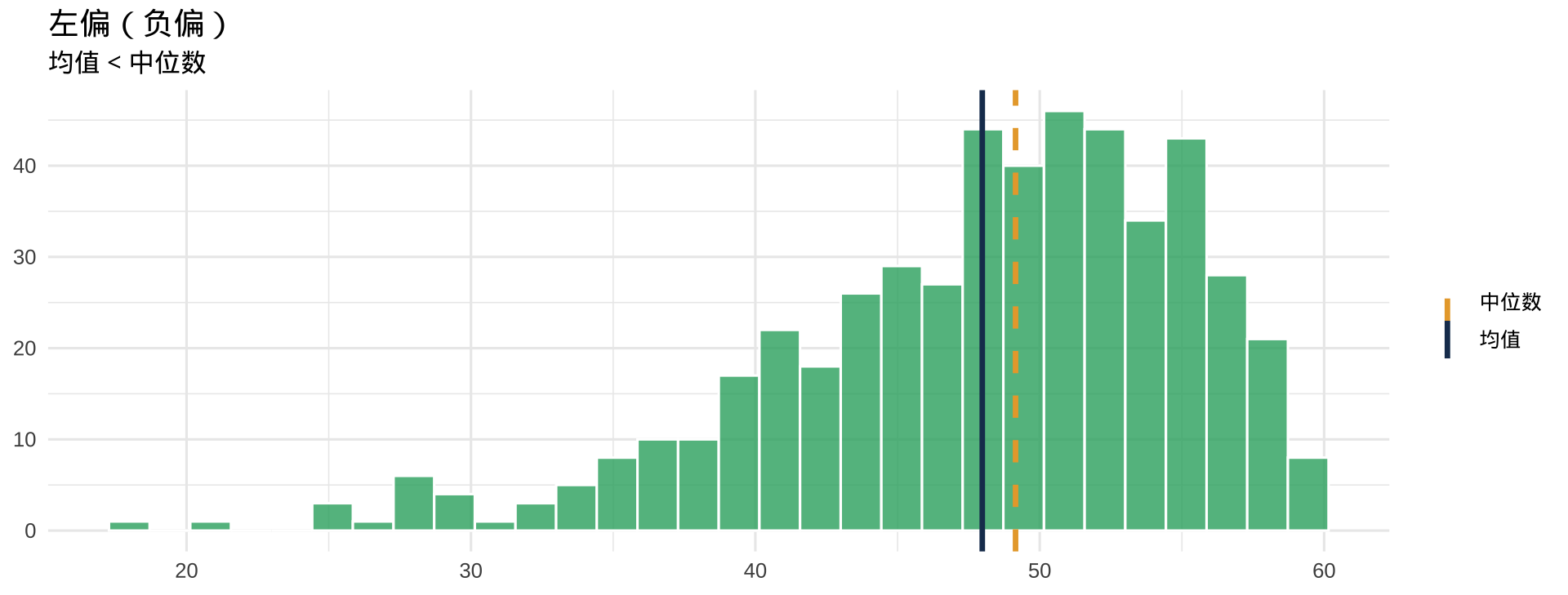
注记
蓝色实线 = 均值,橙色虚线 = 中位数。右偏时均值被极大值"拉走"。
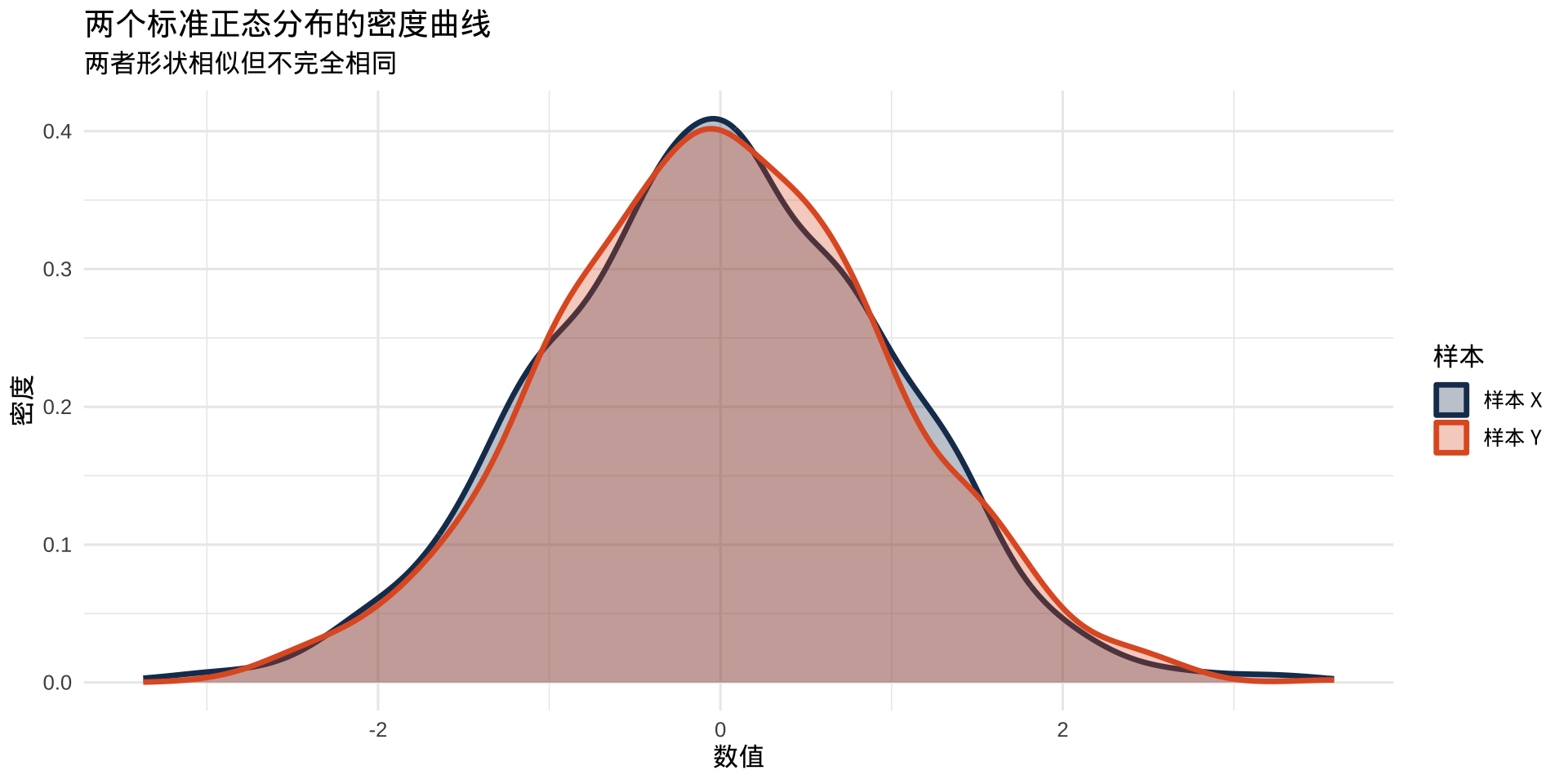
正态分布的形状
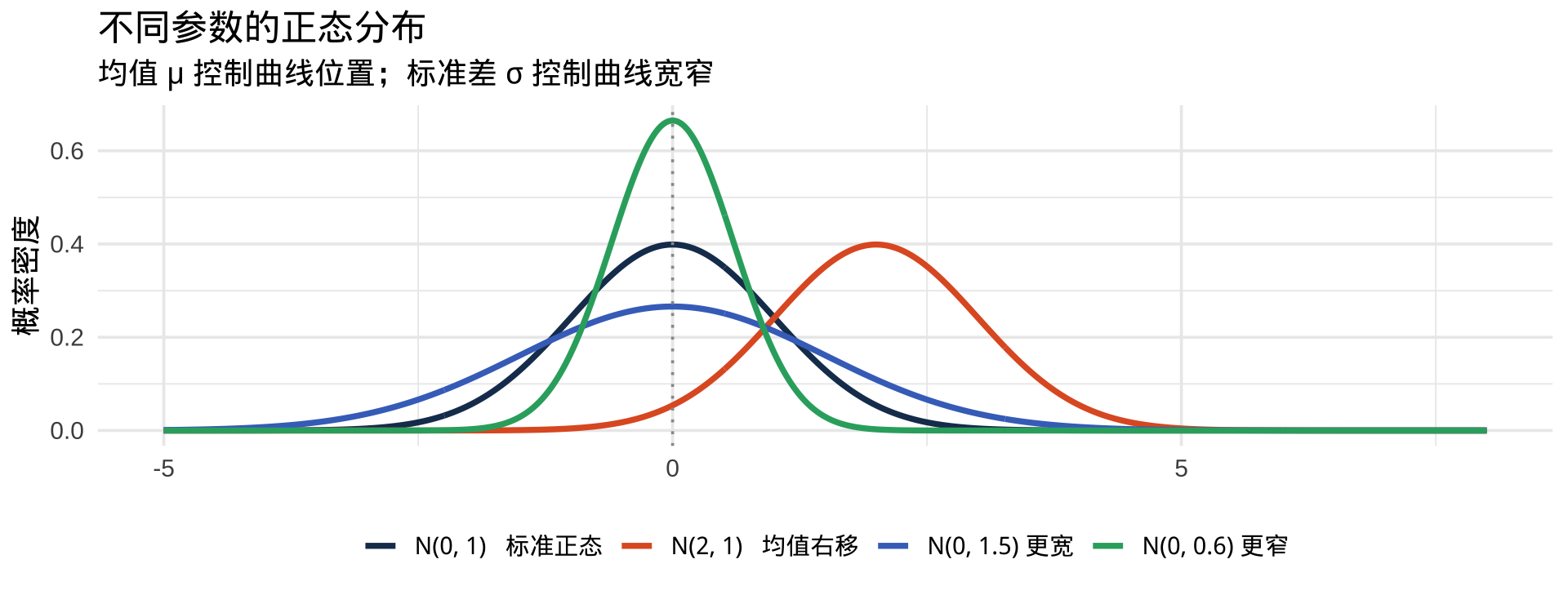
注记
所有正态分布的曲线形状相同,只是位置和宽度不同。改变 \(\mu\) 左右平移,改变 \(\sigma\) 胖瘦变化。
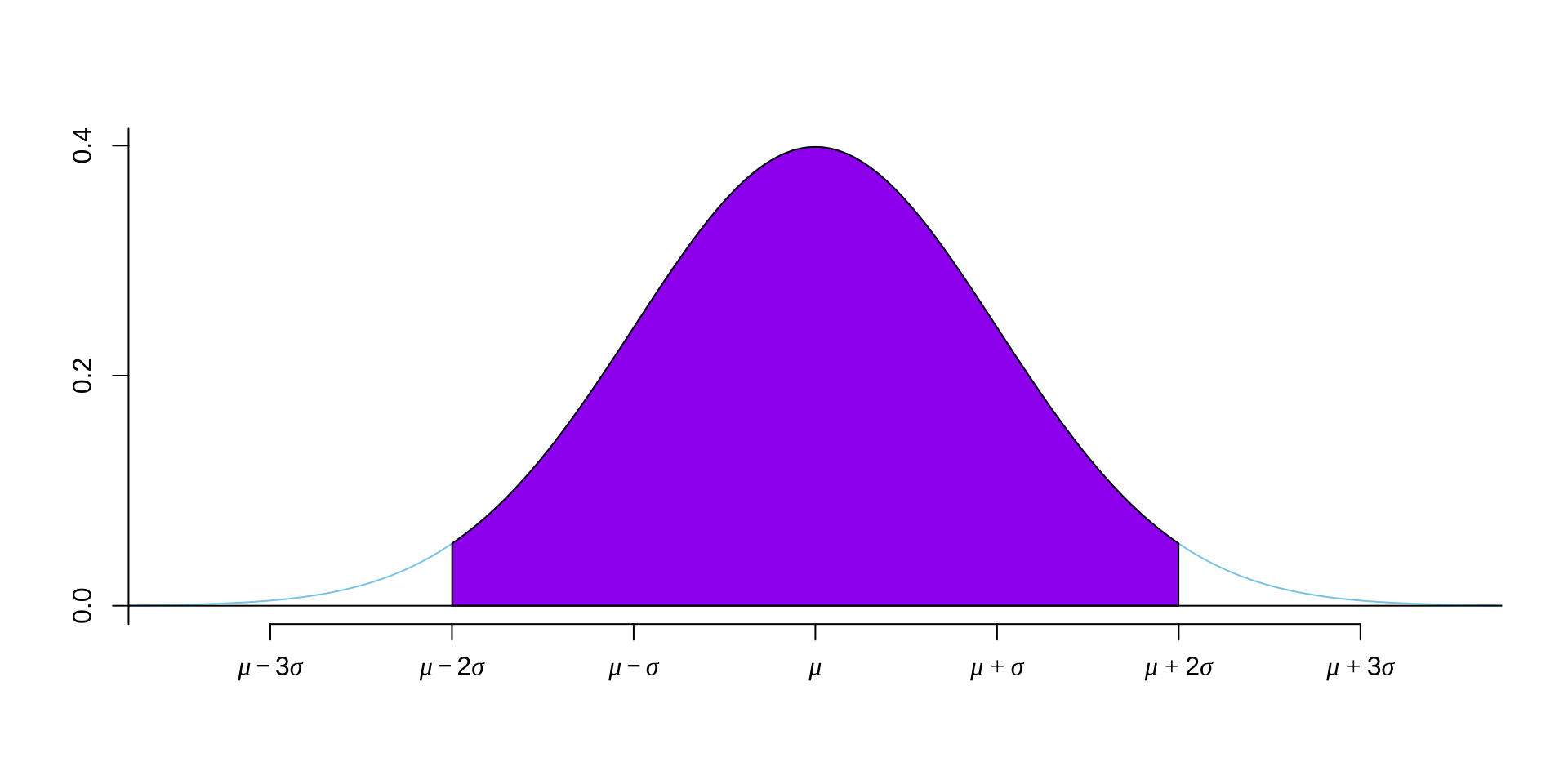
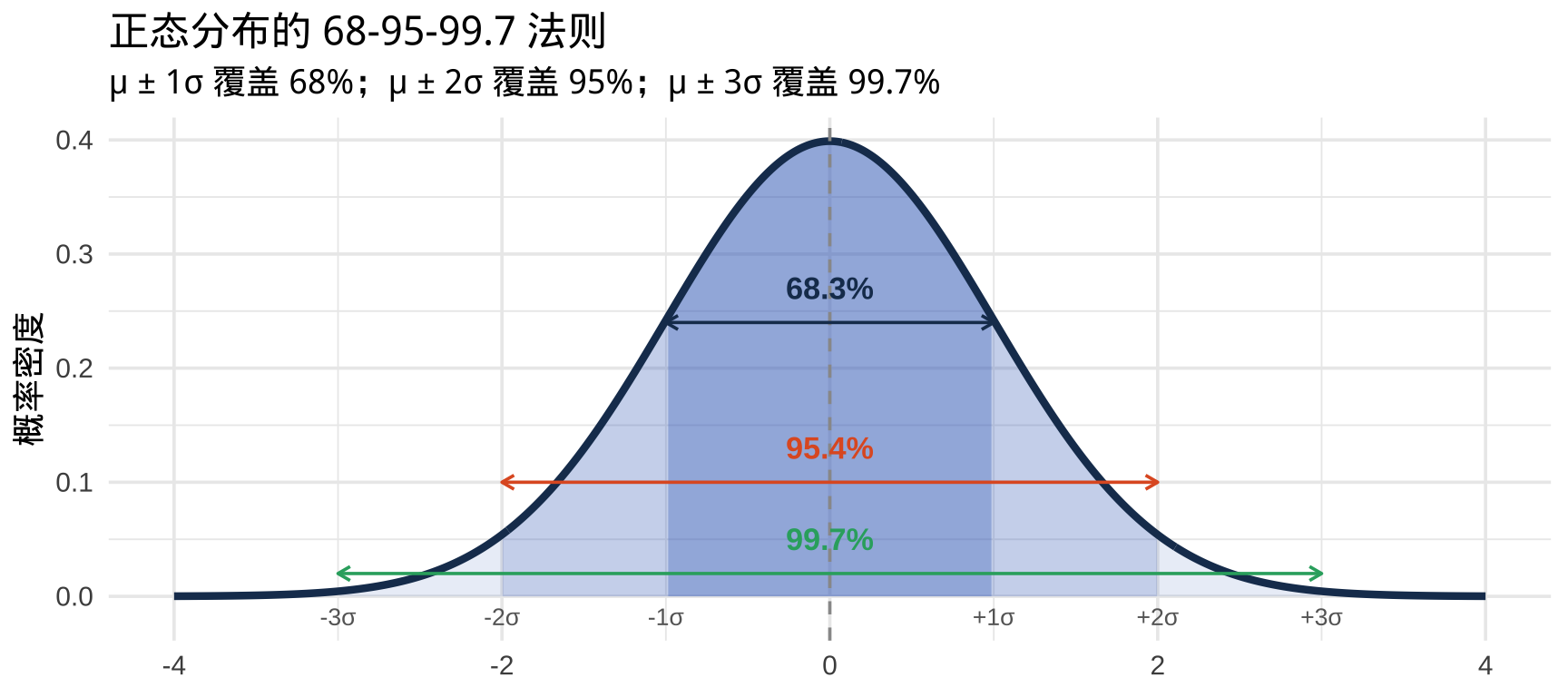
68-95-99.7 法则
[1] 0.00998
正态分布与线性回归
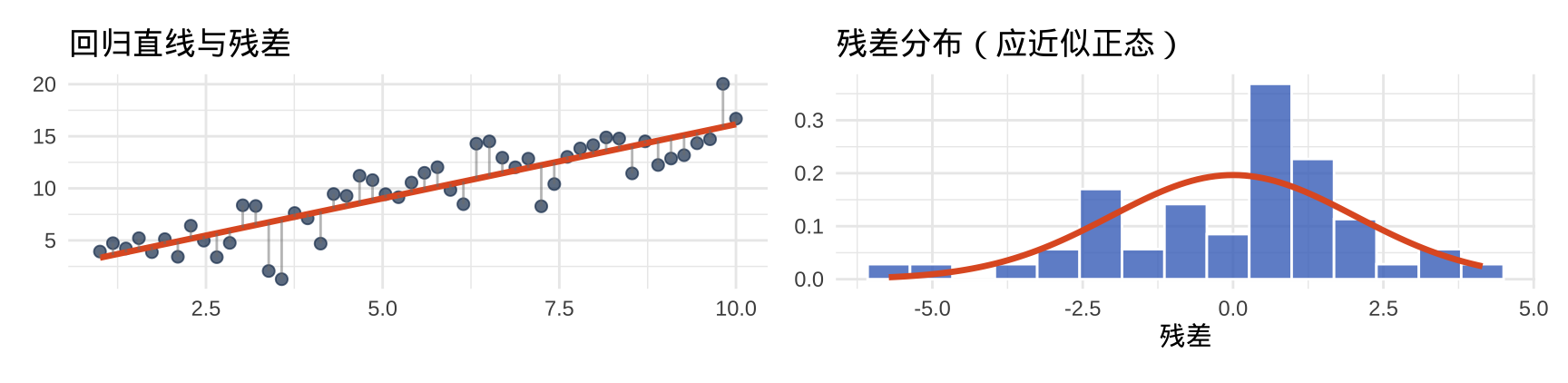
为什么线性回归假设残差服从正态分布?
回归模型:\(y_i = \beta_0 + \beta_1 x_i + \varepsilon_i\),其中 \(\varepsilon_i \sim \mathcal{N}(0, \sigma^2)\)
这个假设意味着:
- 残差以 0 为中心——模型无系统性偏差
- 小残差比大残差出现概率更高(钟形曲线)
- OLS 估计量具有最优性质(BLUE 定理:Best Linear Unbiased Estimator)
- 我们才能使用 \(t\) 分布和 \(F\) 分布进行假设检验
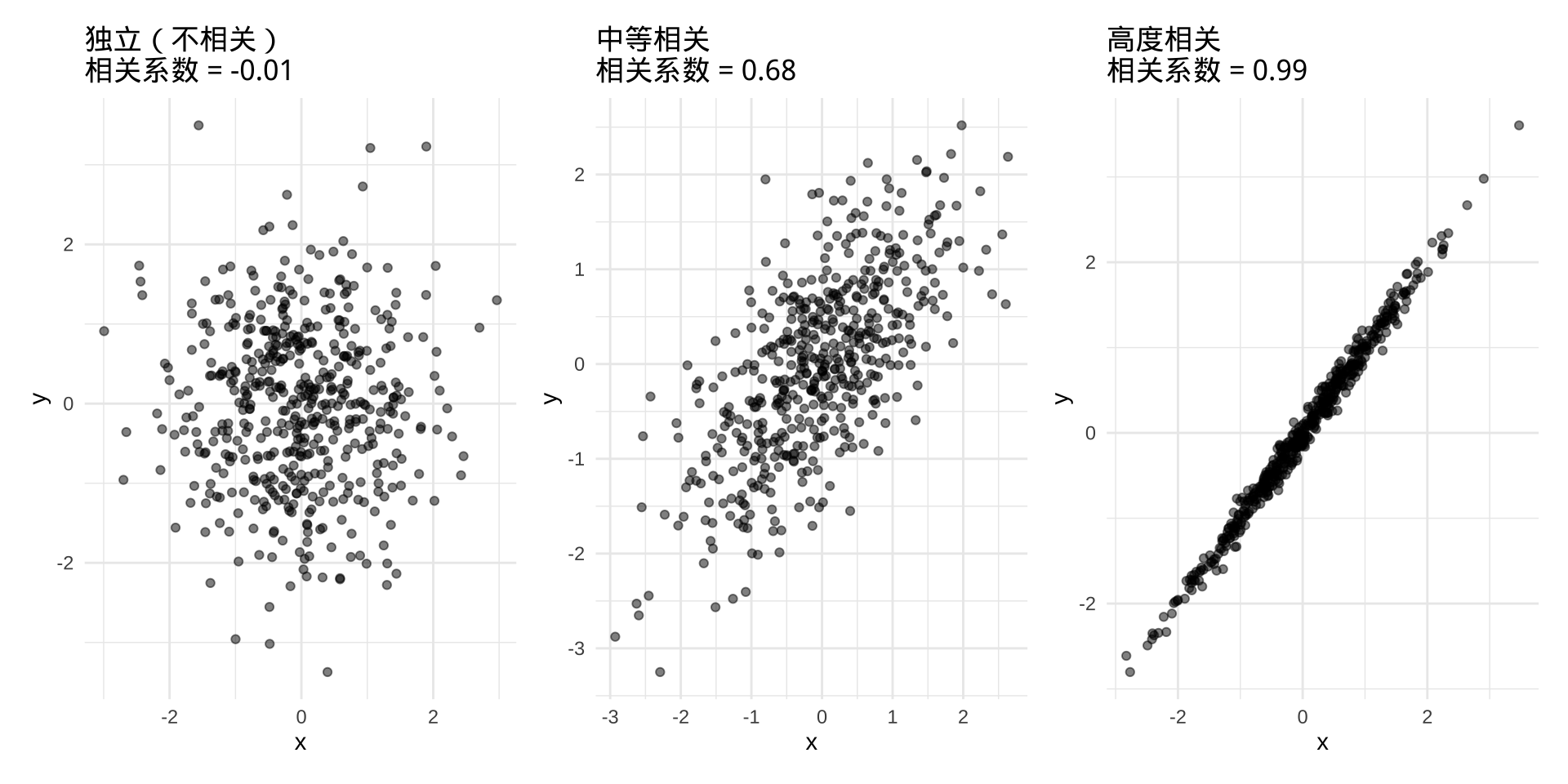
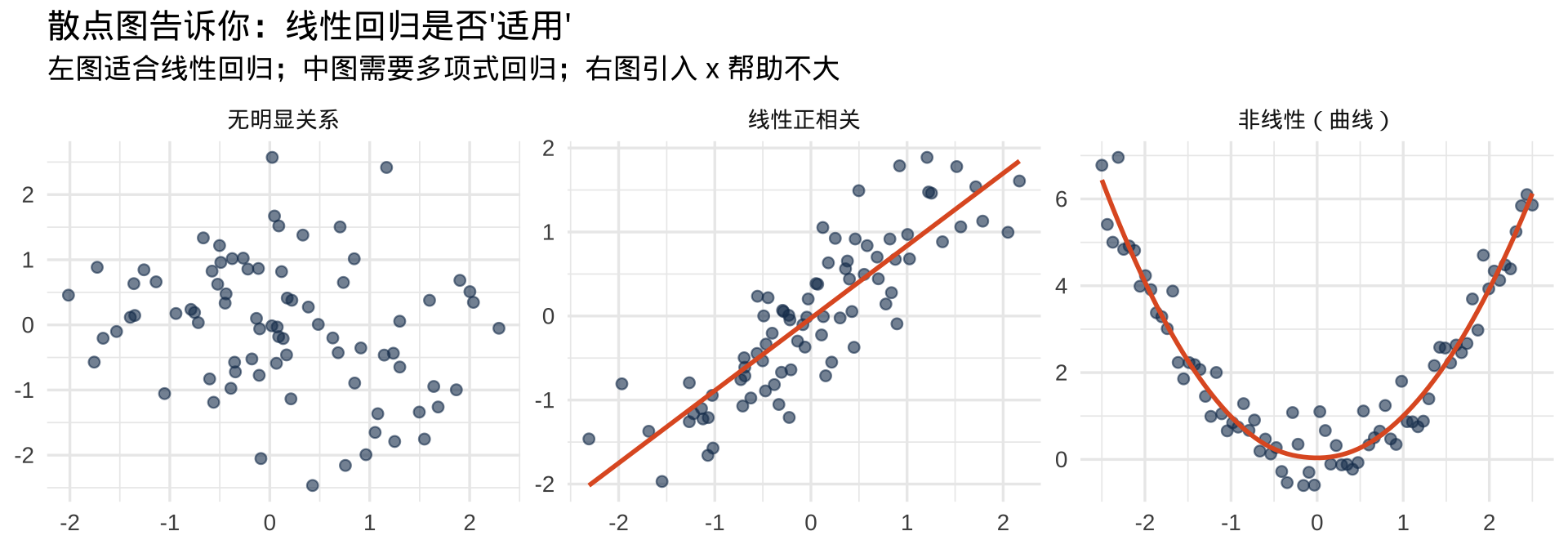
散点图:数据挖掘的第一步
在计算任何系数之前,先看图。
警告
Anscombe 四重奏的教训(第7讲):统计量相同,散点图可能完全不同。图永远先于数字。
共线性预警
如果两个自变量之间高度相关……
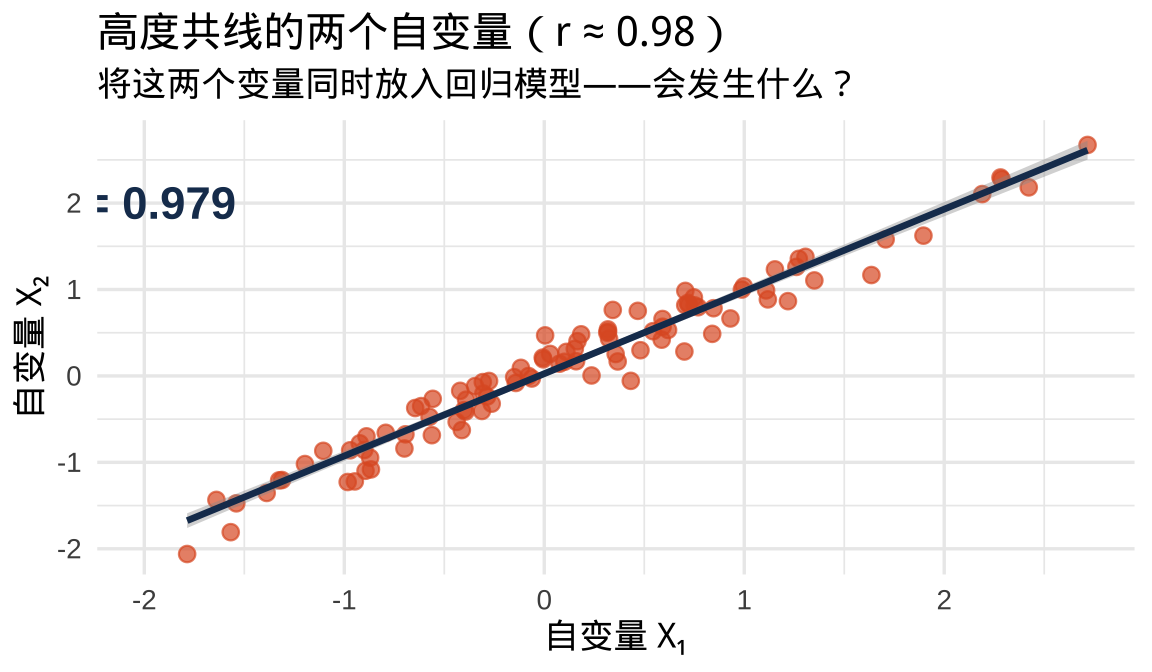
模型"分不清"到底是 \(X_1\) 还是 \(X_2\) 在起作用——系数估计变得不稳定、不可信。
下讲元回归时,我们会详细处理这个问题(VIF 检验)。
为什么需要统计推断?
我们研究的是总体,但只能观测样本。
核心问题: 样本得到的回归系数 \(\hat{\beta}\),能代表真实的总体系数 \(\beta\) 吗?
中心极限定理(CLT) 给出理论保证:
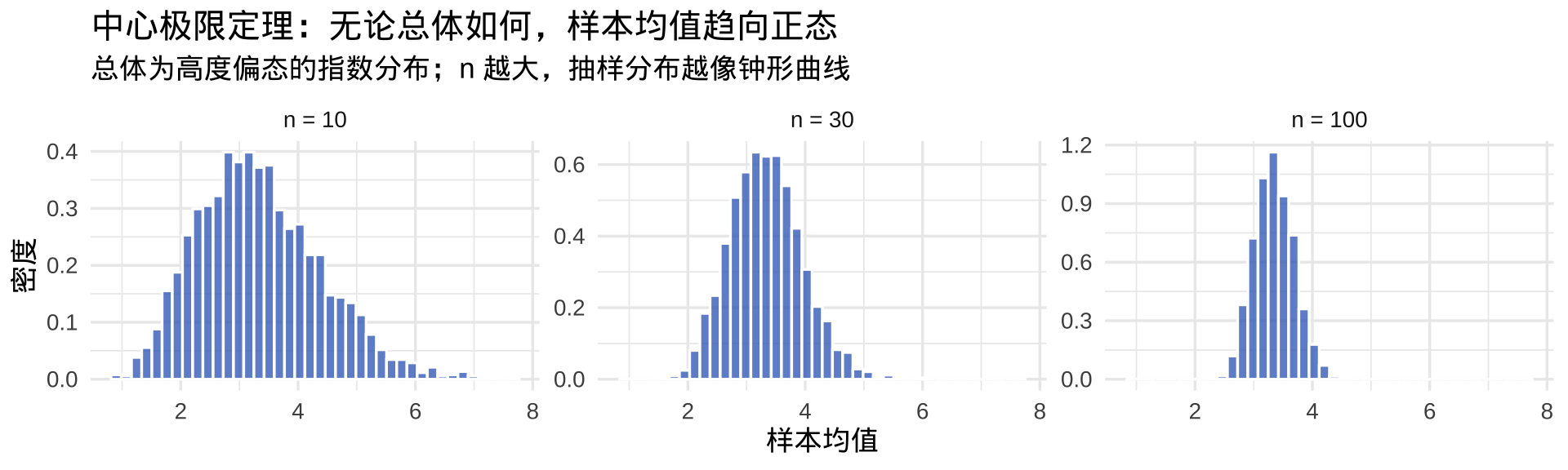
意义: 这正是我们能对回归系数做 \(t\) 检验的理论根基。
P 值图解
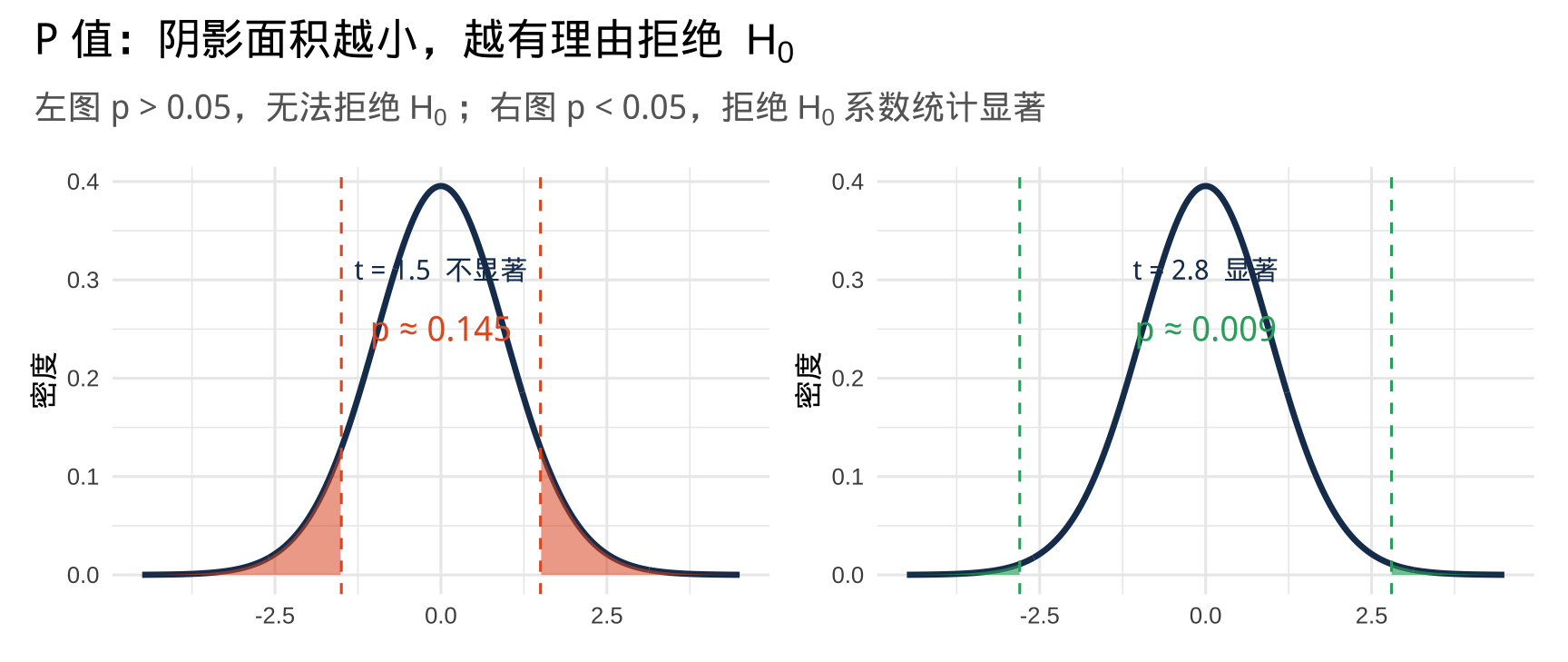
警告
P 值 = "假设 \(H_0\) 为真,观测到当前或更极端结果的概率"——不是 \(H_0\) 为真的概率!
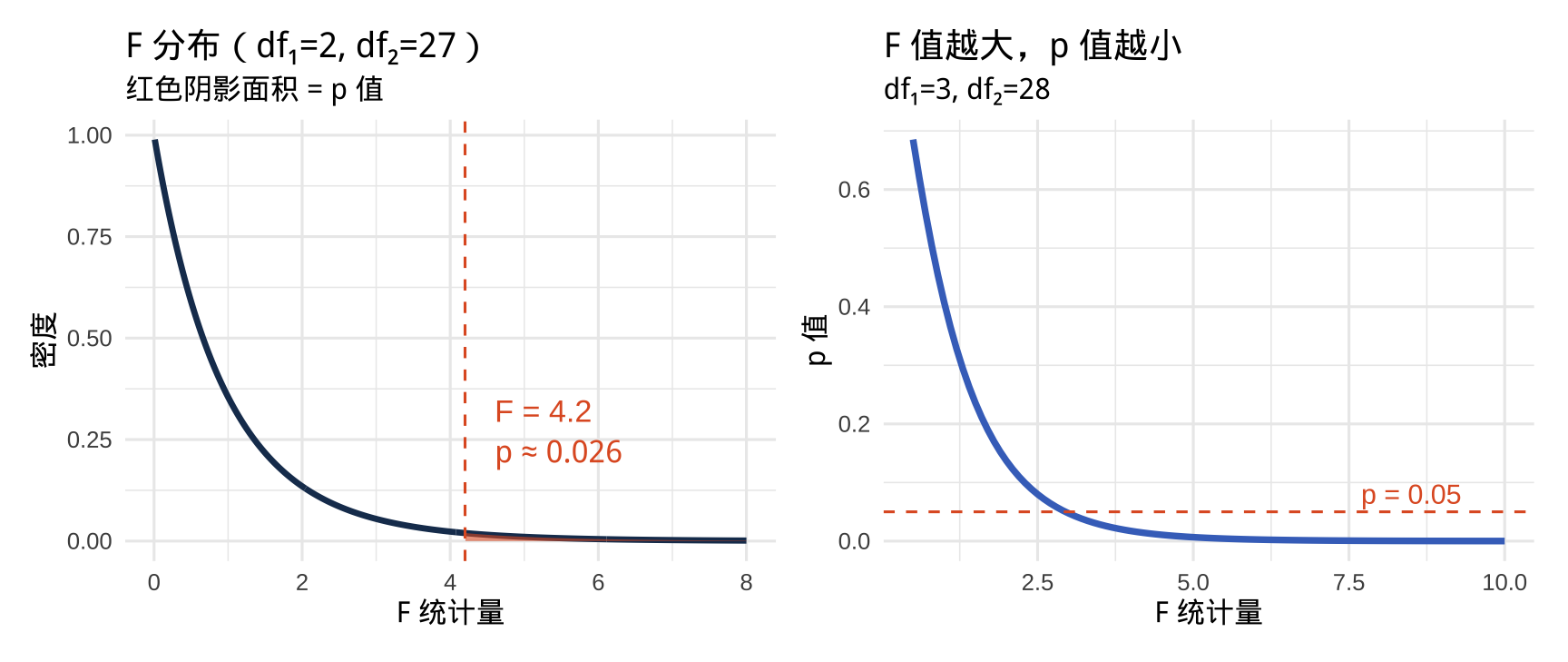
\(F\) 分布图解
第二步:直方图叠加正态曲线
▶️ 查看代码
p_mpg <- ggplot(mtcars, aes(x = mpg)) +
geom_histogram(aes(y = after_stat(density)), bins = 12,
fill = "#4472C4", color = "white", alpha = 0.85) +
stat_function(fun = dnorm,
args = list(mean = mean(mtcars$mpg), sd = sd(mtcars$mpg)),
color = "#e05c2a", linewidth = 1.2) +
geom_vline(xintercept = mean(mtcars$mpg), color = "#1a3a5c", linewidth = 1) +
geom_vline(xintercept = median(mtcars$mpg), color = "#e8a838", linewidth = 1, linetype = "dashed") +
labs(title = "mpg 分布", subtitle = "红线=正态拟合曲线", x = "mpg", y = "密度")
p_hp <- ggplot(mtcars, aes(x = hp)) +
geom_histogram(aes(y = after_stat(density)), bins = 12,
fill = "#e05c2a", color = "white", alpha = 0.85) +
stat_function(fun = dnorm,
args = list(mean = mean(mtcars$hp), sd = sd(mtcars$hp)),
color = "#1a3a5c", linewidth = 1.2) +
geom_vline(xintercept = mean(mtcars$hp), color = "#1a3a5c", linewidth = 1) +
geom_vline(xintercept = median(mtcars$hp), color = "#e8a838", linewidth = 1, linetype = "dashed") +
labs(title = "hp 分布", subtitle = "蓝线=正态拟合曲线", x = "hp", y = "密度")
p_mpg + p_hp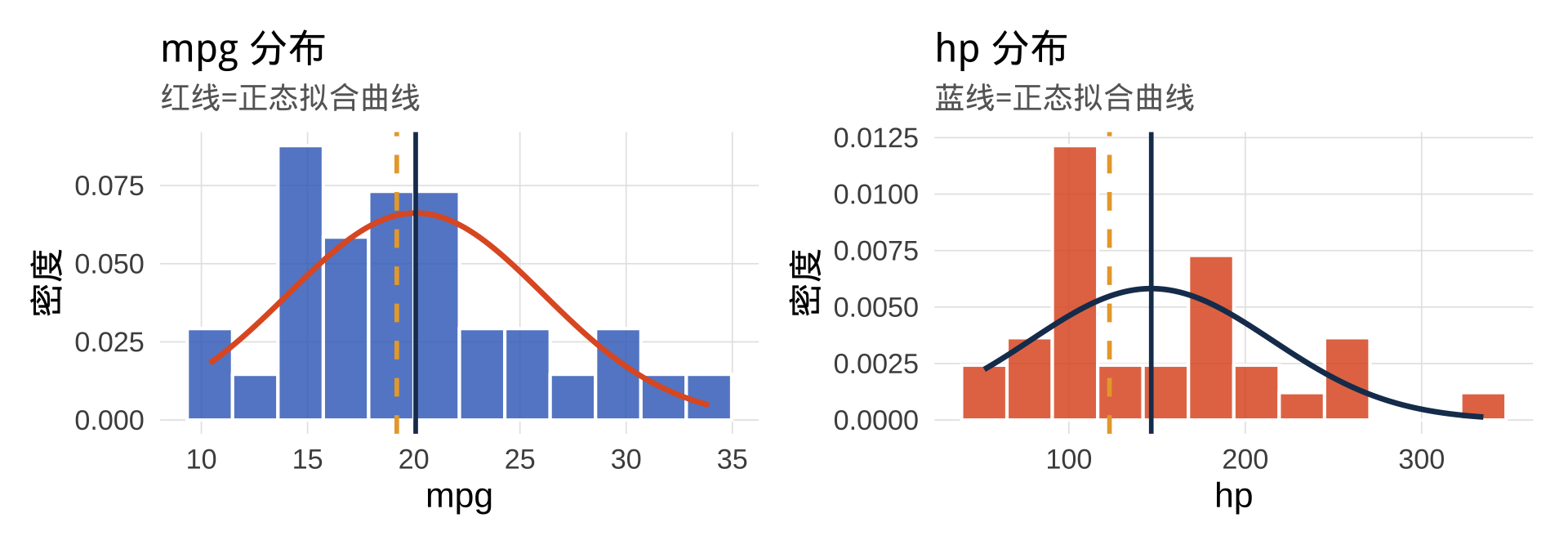
第四步:散点图矩阵
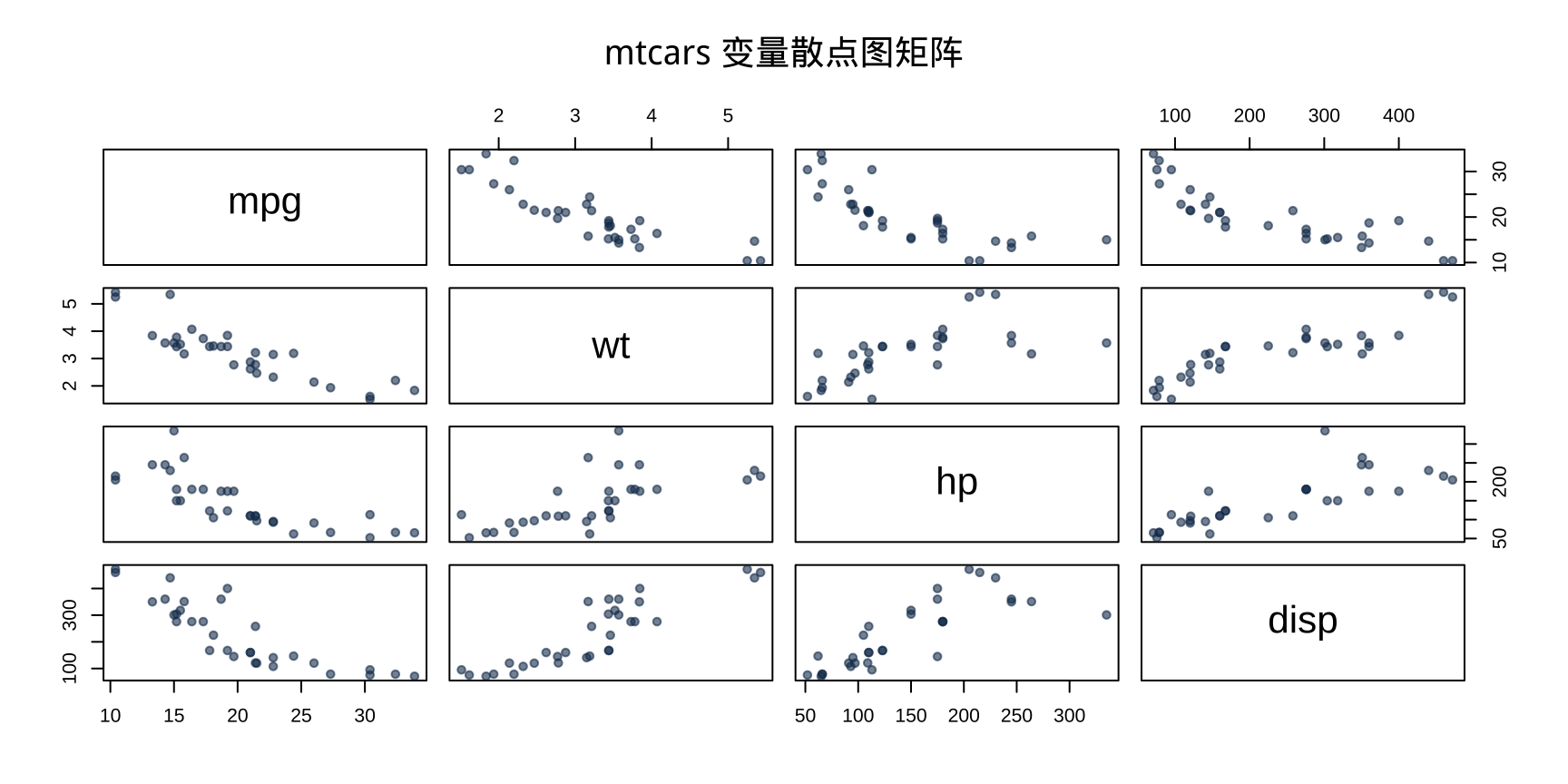
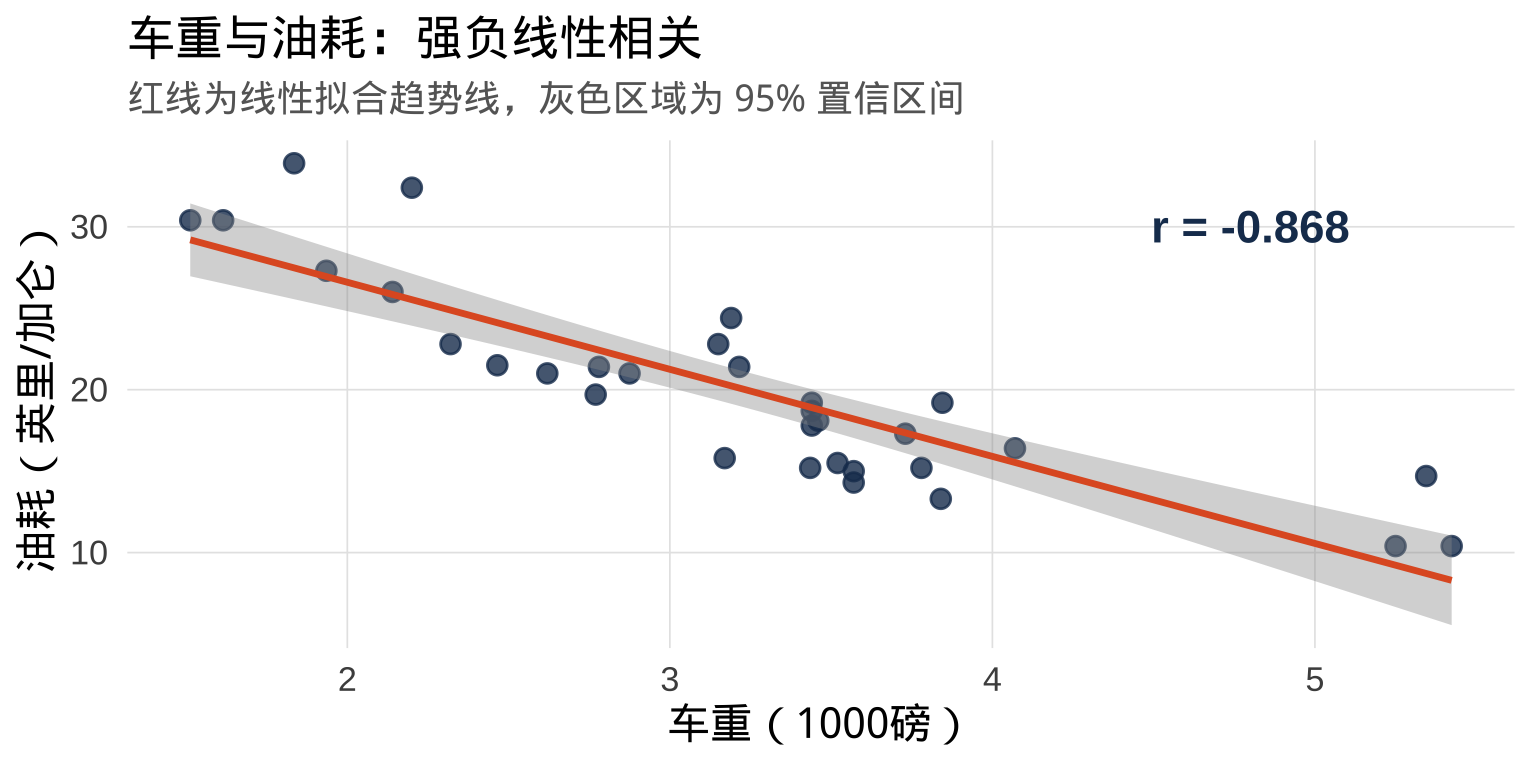
第五步:核心散点图 + 相关系数
▶️ 查看代码
r_val <- cor(mtcars$wt, mtcars$mpg) |> round(3)
ggplot(mtcars, aes(x = wt, y = mpg)) +
geom_point(size = 3, color = "#1a3a5c", alpha = 0.8) +
geom_smooth(method = "lm", se = TRUE, color = "#e05c2a", linewidth = 1.2) +
annotate("text", x = 4.8, y = 30,
label = paste0("r = ", r_val),
size = 6, color = "#1a3a5c", fontface = "bold") +
labs(
title = "车重与油耗:强负线性相关",
subtitle = "红线为线性拟合趋势线,灰色区域为 95% 置信区间",
x = "车重(1000磅)", y = "油耗(英里/加仑)"
)
第七步:正态性检验
▶️ 查看代码
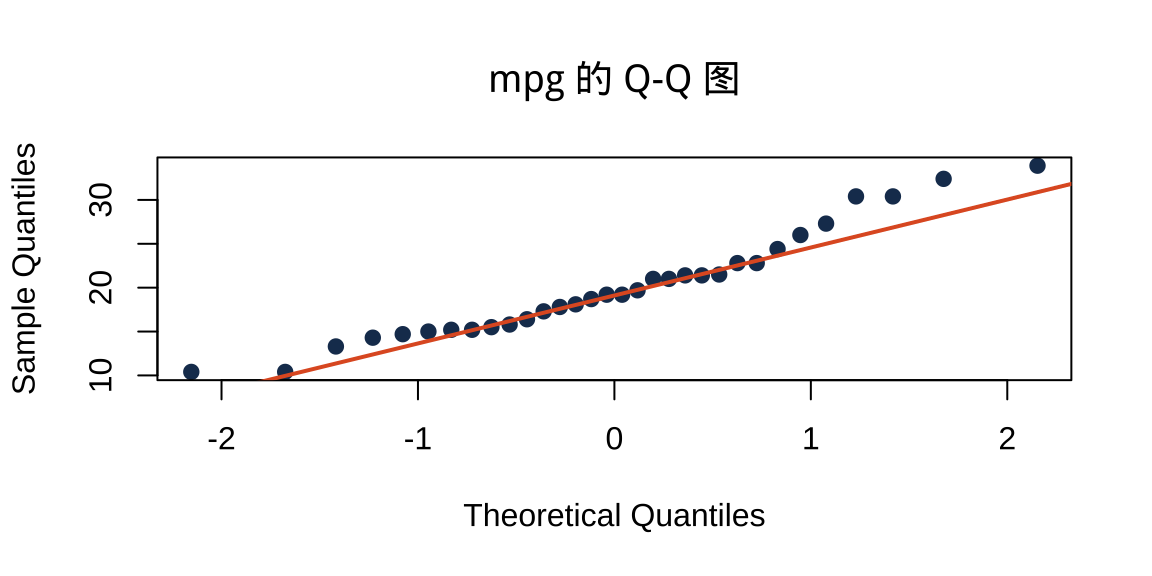
提示
p > 0.05 → 不拒绝正态假设,mpg 可视为近似正态。下讲拟合回归后,同样的检验将用于残差。