数据挖掘与R语言
第10讲:简单线性回归
2026年04月29日
弗朗西斯·高尔顿(Francis Galton)
Francis Galton(1822—1911)
- 英国统计学家、博学家,达尔文的表弟
- 对人类遗传学痴迷,尤其着迷于"高个子的父母亲,子女会有多高?"
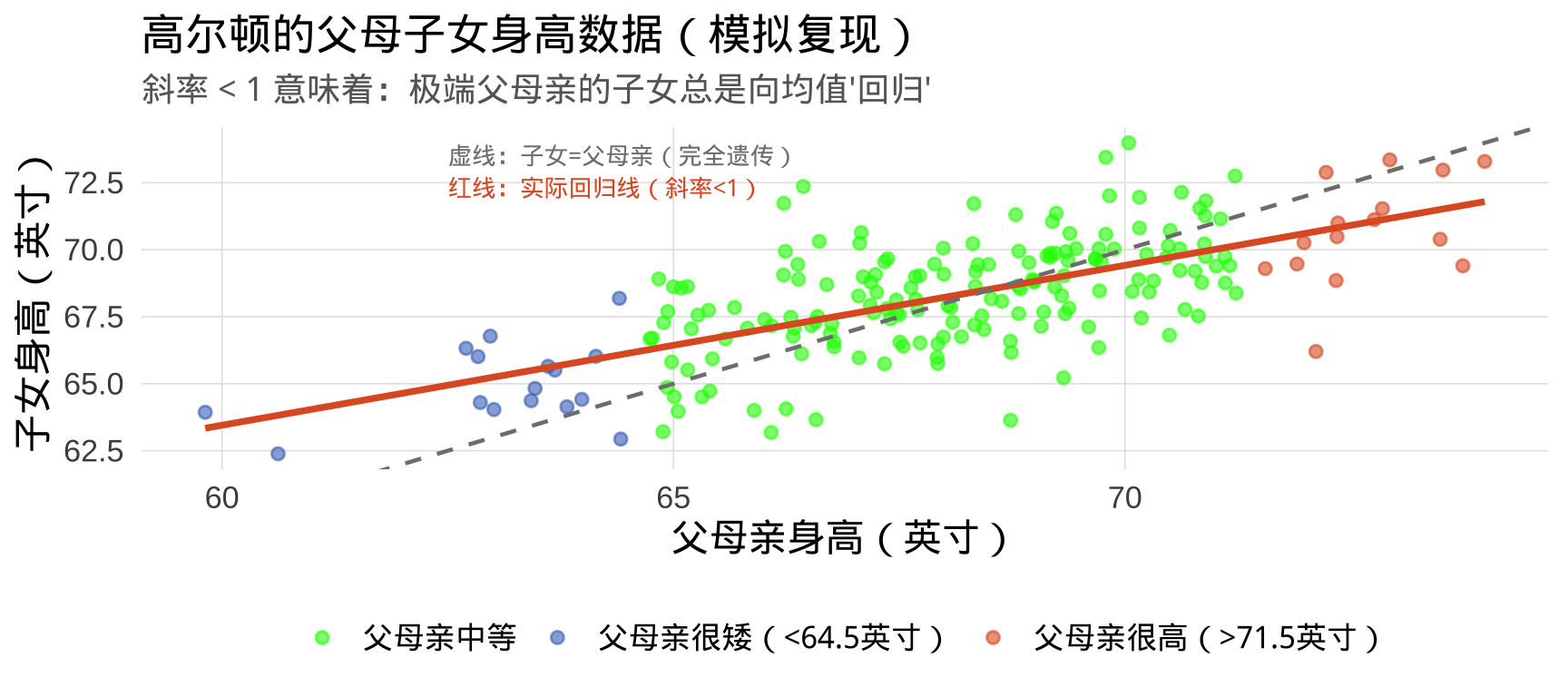
- 收集了205个家庭中928名成年子女 的父母子女身高数据
他的发现让他惊讶:
父母亲极高 → 子女通常会比父母亲矮一些
父母亲极矮 → 子女通常会比父母亲高一些
子女的身高总是倾向于向平均值靠拢。
注记
高尔顿的原文(1886):
"Regression towards Mediocrity in Hereditary Stature"

《遗传身高向均值的回归》
发表于 Journal of the Anthropological Institute
这是"回归"(Regression)这个词的第一次出现。
高尔顿的数据:父子身高
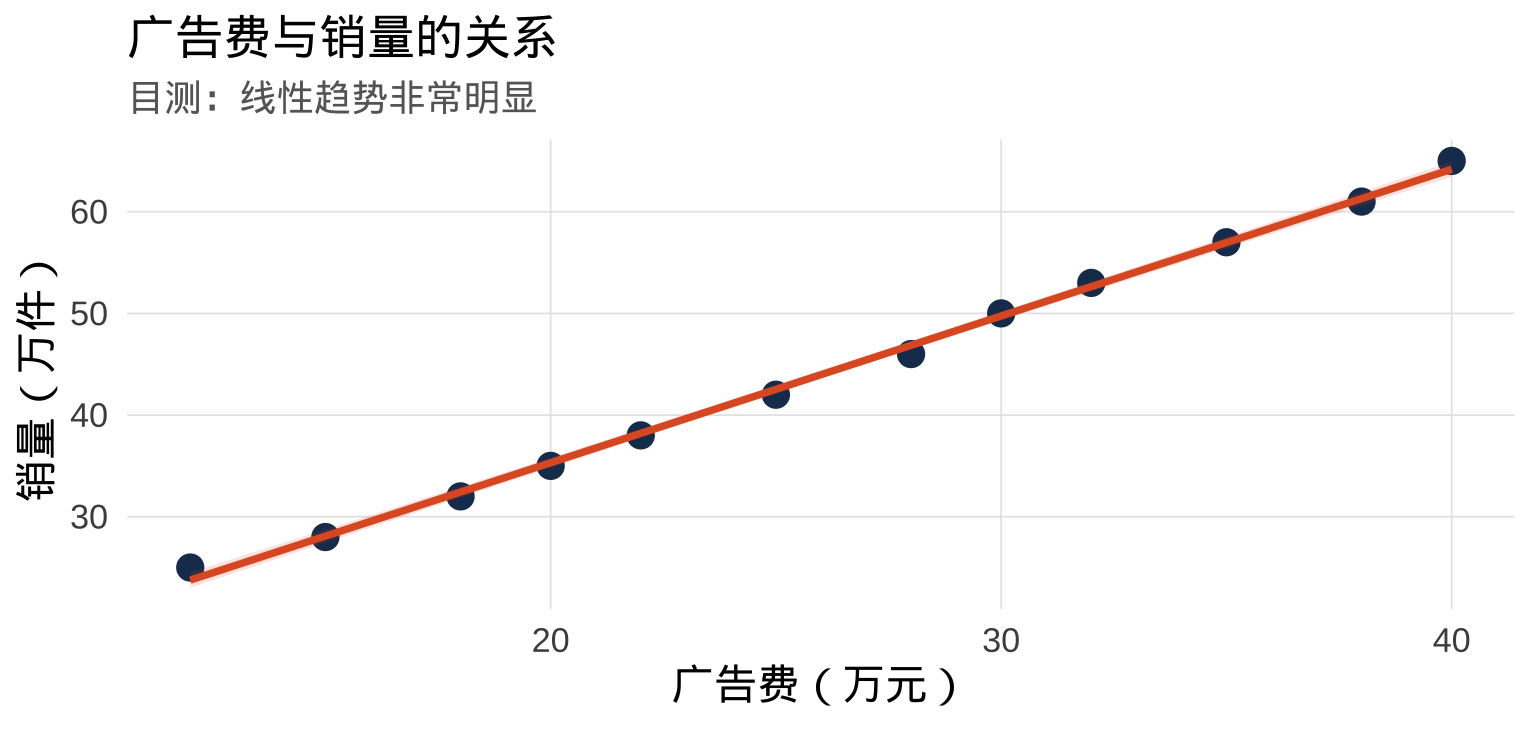
核心思想:用直线描述关系
看到散点图,我们想画一条直线来概括趋势:
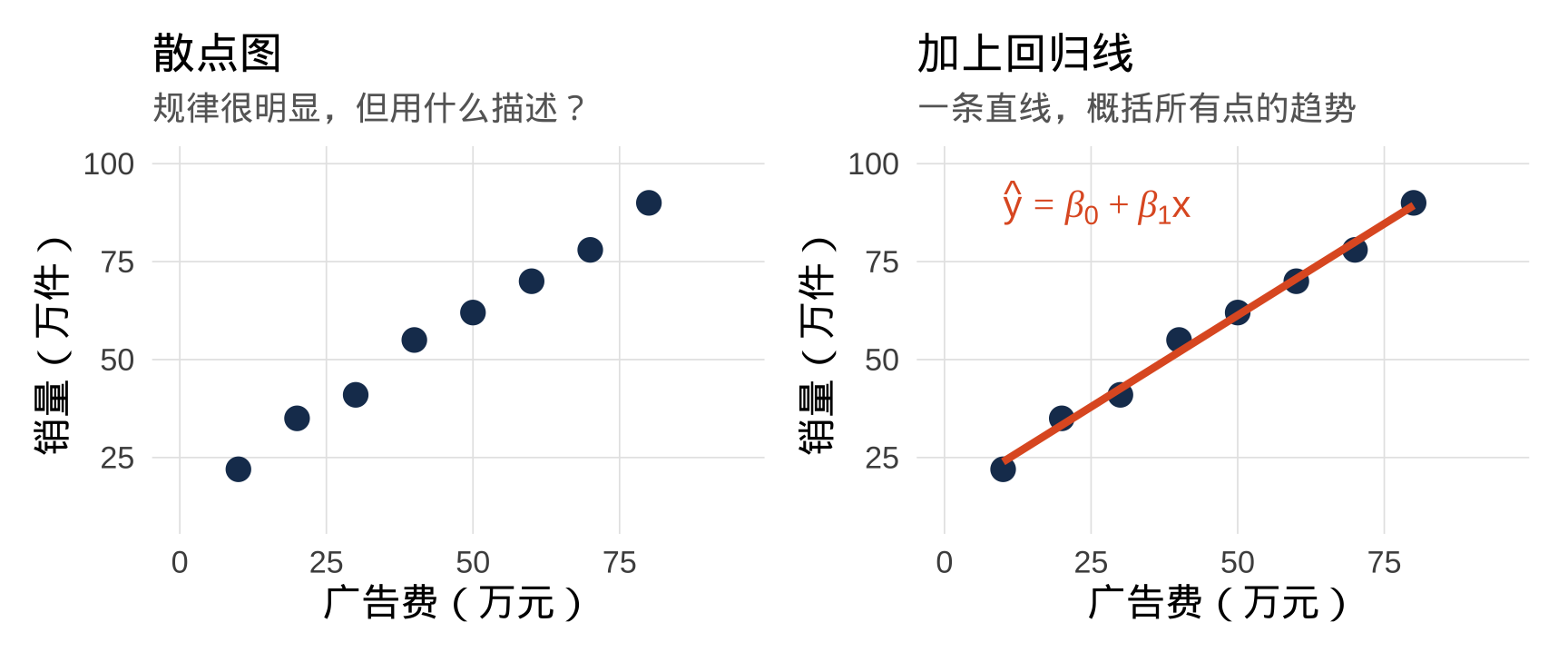
这条直线的方程就是简单线性回归方程:
\[\hat{y} = \hat{\beta}_0 + \hat{\beta}_1 x\]
斜率的直觉
\(\hat{\beta}_1 > 0\)(正斜率)
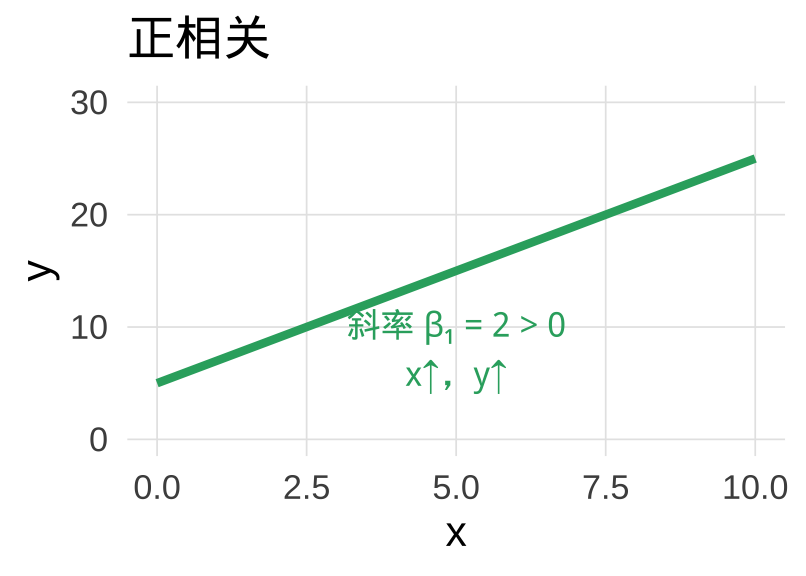
广告费多 → 销量多
\(\hat{\beta}_1 < 0\)(负斜率)
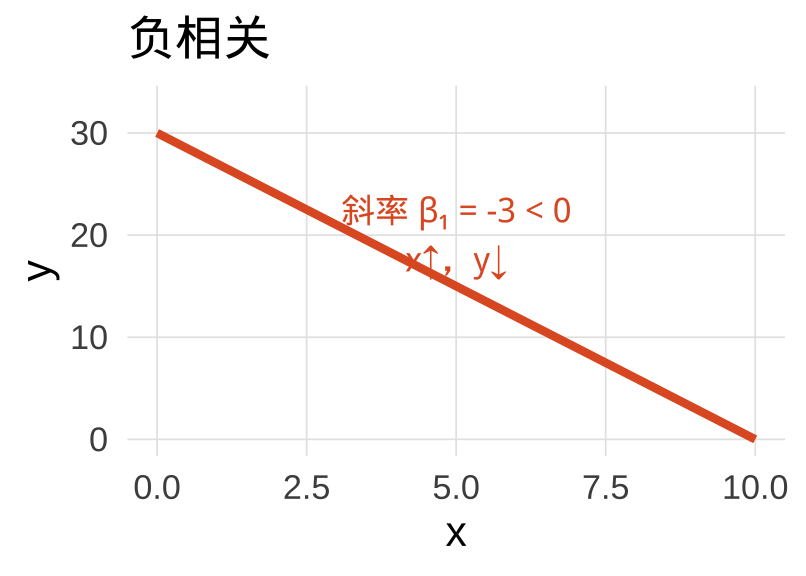
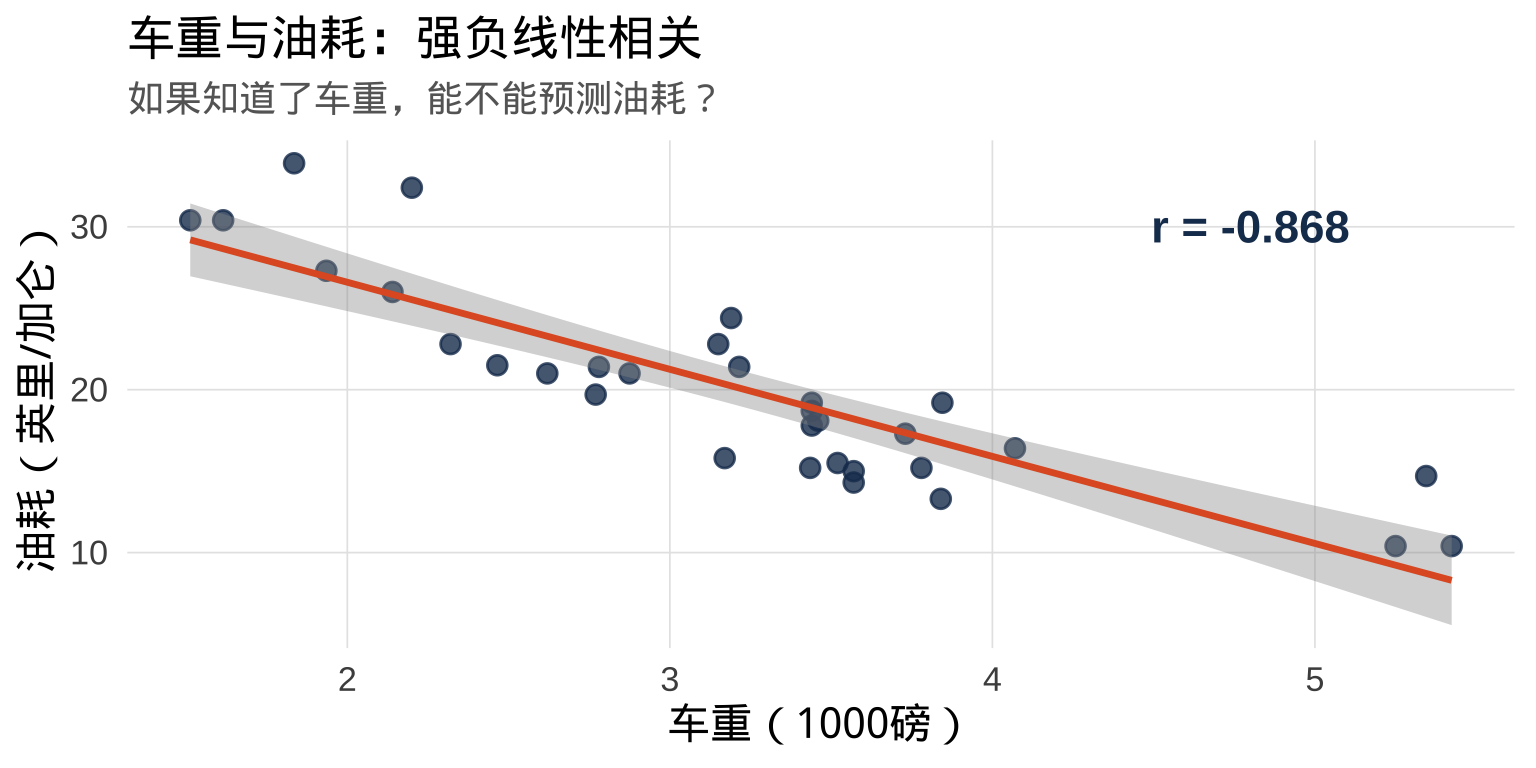
车越重 → 油耗越高(每加仑的行驶里程越短)
问题:哪条线最好?
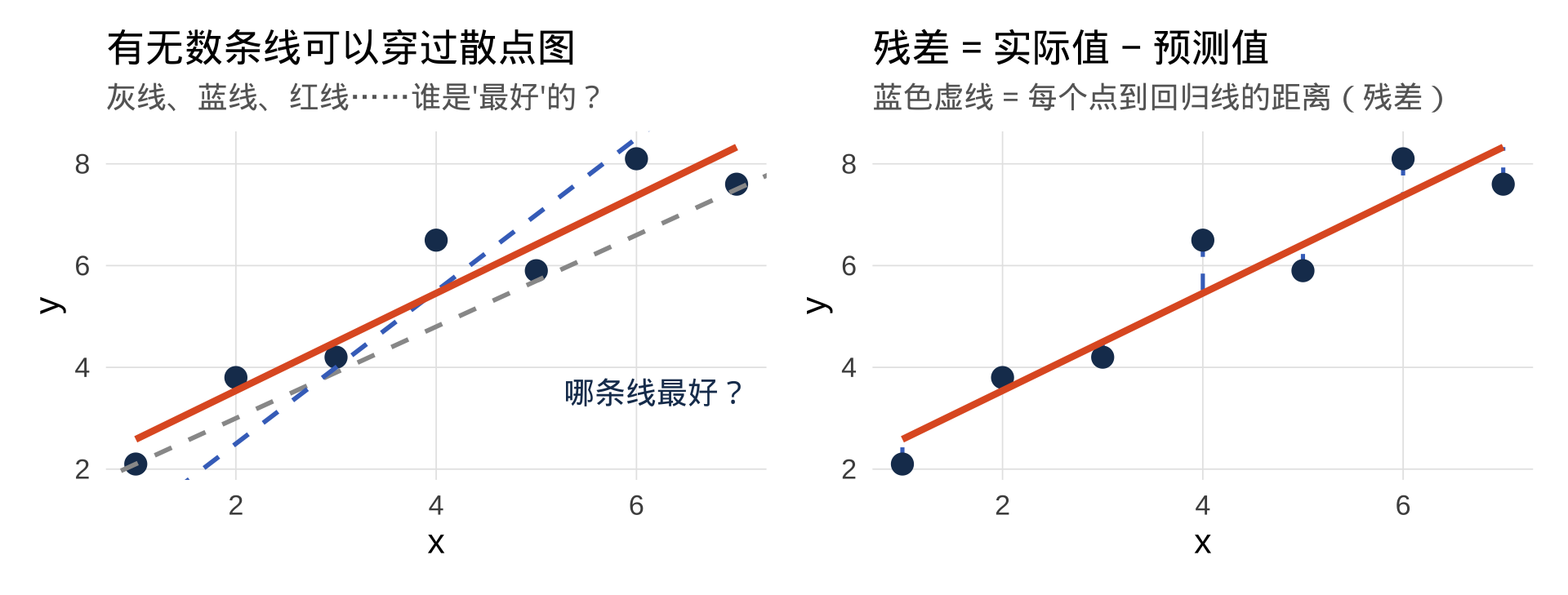
答案:让所有点到直线的距离之和最小的那条线!
用一张图记住所有输出
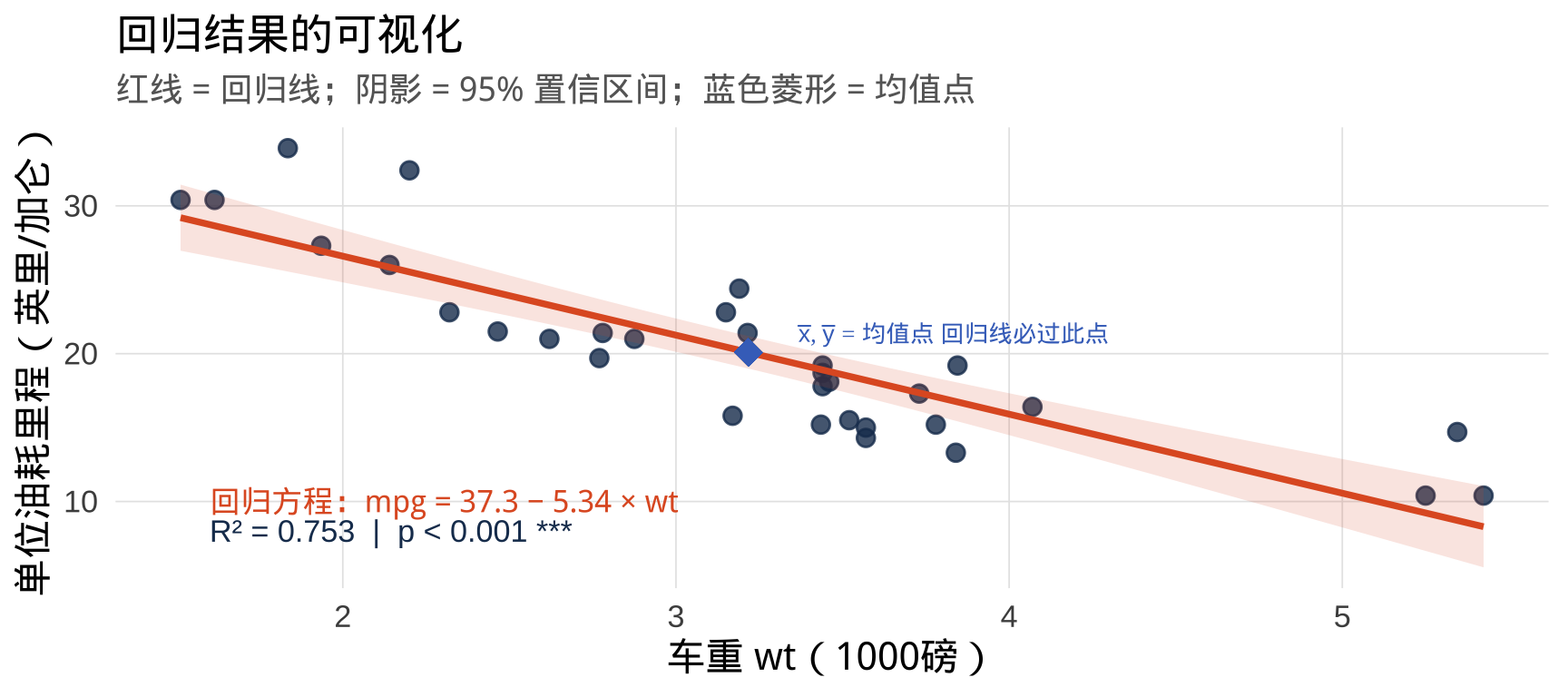
第一步:先画图,再建模
▶️ 查看代码
提示
原则:永远先画散点图,再建模型。 如果散点图呈现非线性(如 U 形、指数型),直接套线性回归就会出错。
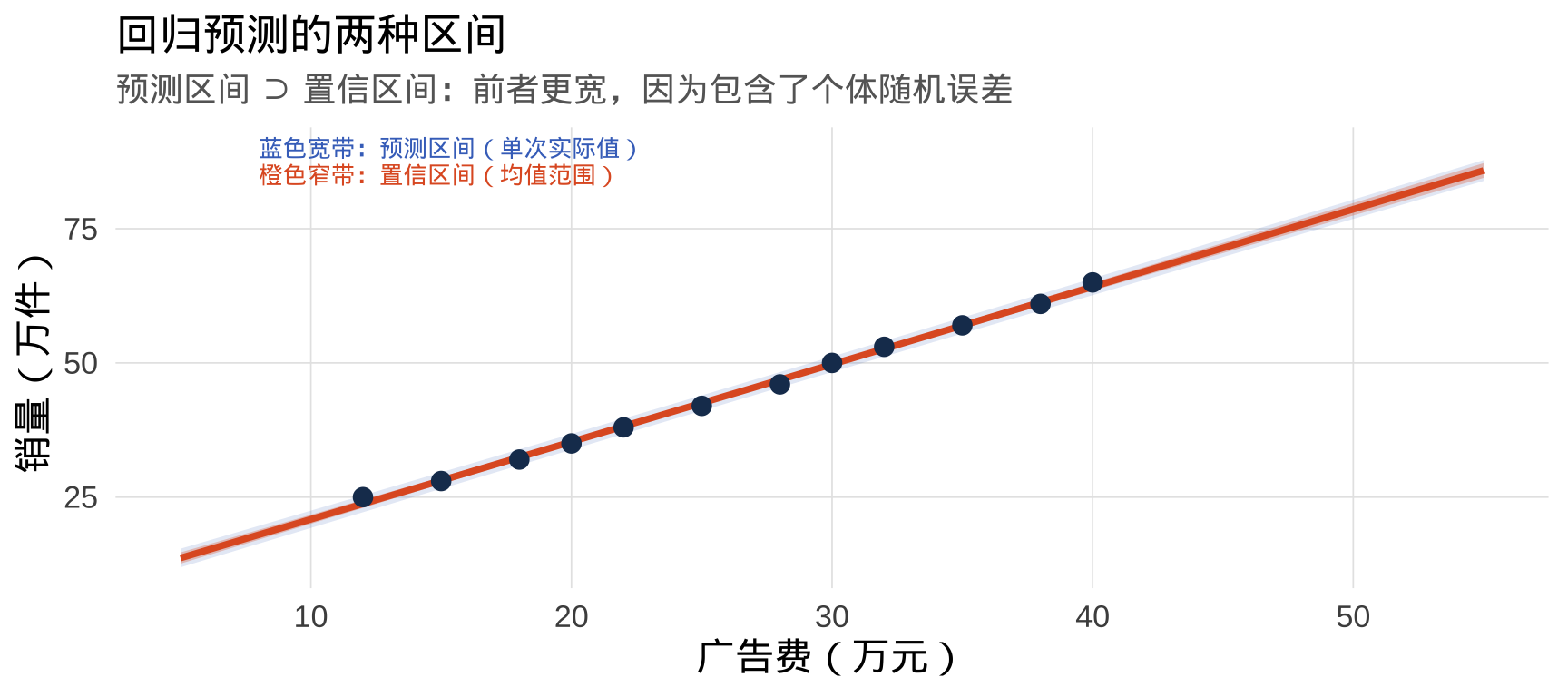
可视化两种区间
▶️ 查看代码
# 生成预测数据
pred_range <- data.frame(广告费 = seq(5, 55, length.out = 100))
conf_int <- predict(ad_model, newdata = pred_range, interval = "confidence")
pred_int <- predict(ad_model, newdata = pred_range, interval = "prediction")
plot_df <- bind_cols(pred_range,
as.data.frame(conf_int) |> rename(fit=fit, conf_lwr=lwr, conf_upr=upr),
as.data.frame(pred_int) |> select(pred_lwr=lwr, pred_upr=upr))
ggplot(plot_df, aes(x = 广告费)) +
geom_ribbon(aes(ymin = pred_lwr, ymax = pred_upr),
fill = "#4472C4", alpha = 0.15) +
geom_ribbon(aes(ymin = conf_lwr, ymax = conf_upr),
fill = "#e05c2a", alpha = 0.3) +
geom_line(aes(y = fit), color = "#e05c2a", linewidth = 1.3) +
geom_point(data = ad_data, aes(x = 广告费, y = 销量),
size = 3, color = "#1a3a5c") +
annotate("text", x = 8, y = 90,
label = "蓝色宽带:预测区间(单次实际值)", color = "#4472C4",
hjust = 0, size = 3.5) +
annotate("text", x = 8, y = 85,
label = "橙色窄带:置信区间(均值范围)", color = "#e05c2a",
hjust = 0, size = 3.5) +
labs(
title = "回归预测的两种区间",
subtitle = "预测区间 ⊃ 置信区间:前者更宽,因为包含了个体随机误差",
x = "广告费(万元)", y = "销量(万件)"
)
外推预测的风险
重要
不要在数据范围之外随意外推!
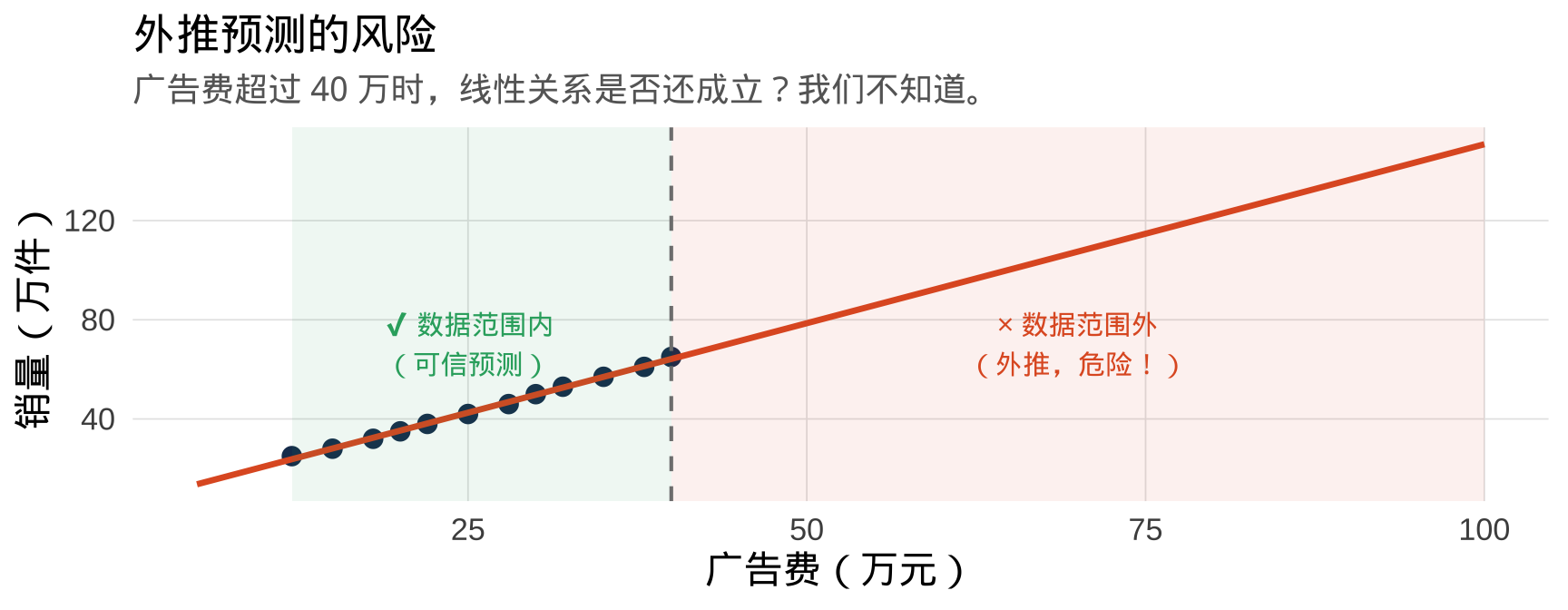
我们的数据只覆盖广告费 12—40 万元的范围。预测广告费 = 200 万元时的销量,完全是在猜测——市场可能早就饱和了。
知识结构回顾
