数据挖掘与R语言
第11讲:多元线性回归
2026年05月06日
上讲回顾
- 回归方程:\(\hat{y} = \hat{\beta}_0 + \hat{\beta}_1 x\);截距是 \(x=0\) 时 \(y\) 的基准值;斜率是 \(x\) 每变化一个单位,\(y\) 预期变化多少
-
OLS:通过最小化残差平方和 \(\text{RSS} = \sum(y_i - \hat{y}_i)^2\) 找到最优直线;
lm()自动完成计算 -
读懂输出:
Estimate(系数大小)→Pr(>|t|)(显著性)→R-squared(解释力)→F-statistic(整体有效性) -
预测:
predict()做点预测;置信区间估计均值,预测区间估计单次实际值;不要在数据范围外随意外推 -
wt解释了mpg75.3% 的变异,剩余 24.7% 去哪了?这就是今天多元回归的起点
本讲内容
- Part 1:为什么需要多元回归? ——一个变量无法解释全部因素
- Part 2:模型方程与偏回归系数 ——\(y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_k x_k + \varepsilon\)
- Part 3:多重共线性 ——自变量之间高度相关时会发生什么?VIF 检验
- Part 4:模型选择 ——Adjusted \(R^2\)、AIC——怎么知道加哪个变量?
-
Part 5:R 实战 ——
lm(y ~ x1 + x2 + x3)语法,vif()函数,逐步回归 - Part 6:模型诊断? ——回归假设是否成立?
Part 1:为什么需要多元回归?
一个现象或结果往往并不是由一个单独的变量所决定
简单回归的局限:遗漏变量偏差
回顾第 10 讲的结论:
\[\widehat{\text{mpg}} = 37.3 - 5.34 \times \text{wt} \qquad R^2 = 0.753\]
问题:剩余 24.7% 去哪了?
可能的遗漏因素:
- 气缸数(
cyl) - 马力(
hp) - 变速箱类型(
am) - 发动机排量(
disp)
警告
遗漏变量偏差(Omitted Variable Bias)
当模型忽略了一个关键变量 \(z\) 时:
- 若 \(z\) 同时与 \(x\) 和 \(y\) 相关,会导致 \(\hat{\beta}_1\) 产生偏差(Bias),使估计结果不可信。
- 若 \(z\) 仅与 \(y\) 相关而与 \(x\) 无关,虽不产生偏差,但会降低估计的精度(Efficiency),增大标准误。
混淆因素的直觉
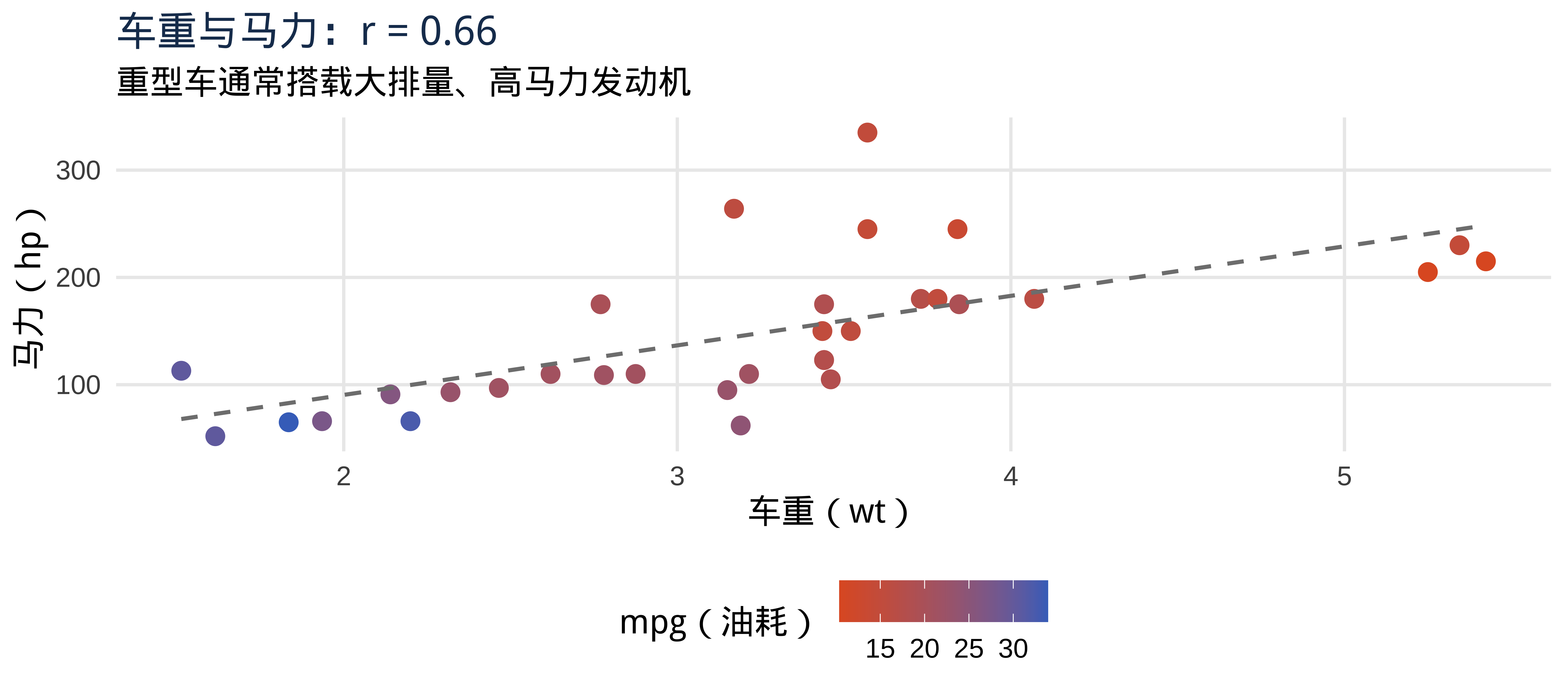
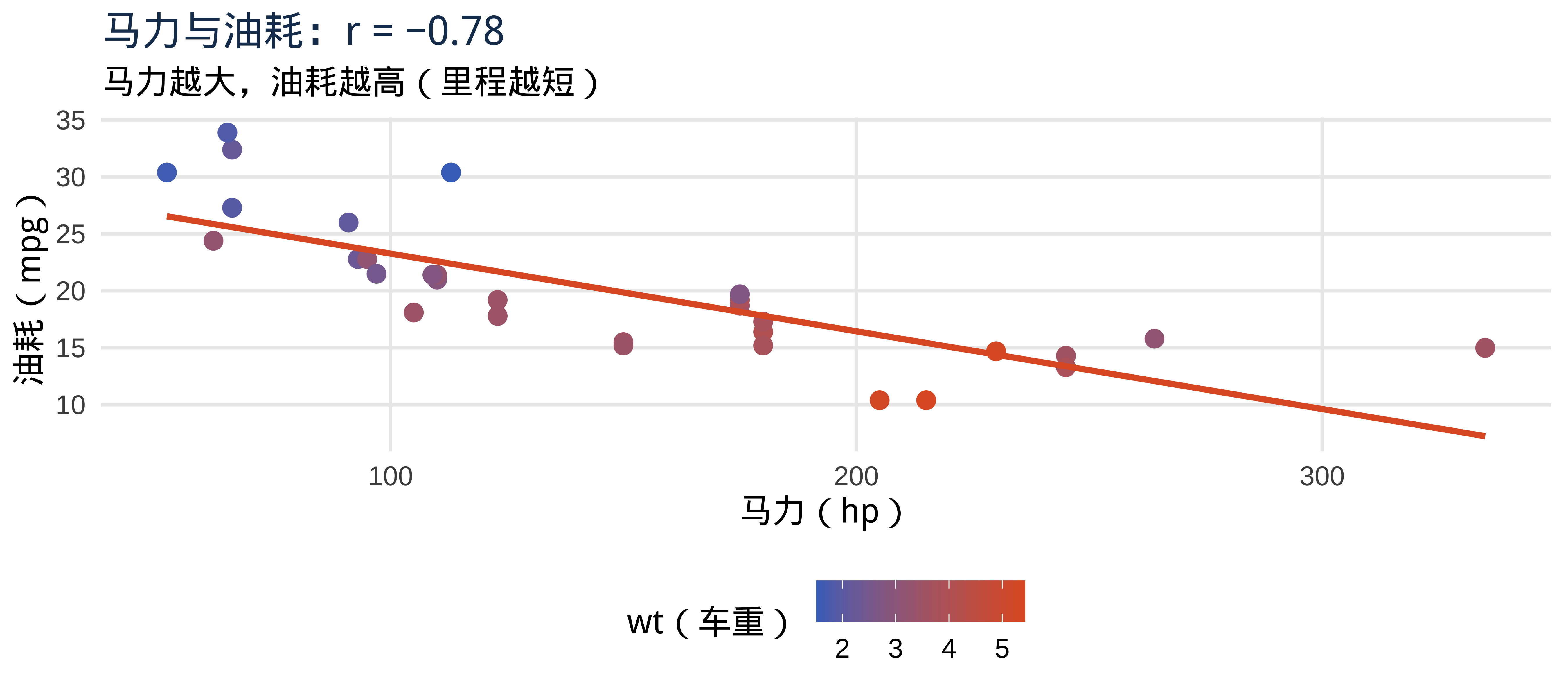
注记
问题的核心: 车重 wt 和马力 hp 高度相关(\(r = 0.66\))。简单回归中 wt 的系数 \(\hat{\beta}_1 = -5.34\),这个数字究竟有多少是车重本身的贡献,又有多少是马力"顺带"带入的?我们无法区分。
Part 2:模型方程与偏回归系数
从平面到超平面
多元线性回归方程
\[y = \underbrace{\beta_0}_{\text{截距}} + \underbrace{\beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_k x_k}_{\text{$k$ 个自变量}} + \underbrace{\varepsilon}_{\text{误差项}}\]
| 符号 | 名称 | 含义 | 汽车案例 |
|---|---|---|---|
| \(y\) | 因变量 | 要预测的量 | 油耗(mpg) |
| \(x_1, \ldots, x_k\) | 自变量(\(k\) 个) | 用来预测的变量 | 车重、马力、气缸数…… |
| \(\beta_0\) | 截距 | 所有 \(x = 0\) 时 \(y\) 的理论值 | (通常无直接业务意义) |
| \(\beta_1, \ldots, \beta_k\) | 偏回归系数 | 控制其他 \(x\) 后,某个 \(x\) 对 \(y\) 的净效应 | 控制马力后,车重每增加 1 的效应 |
| \(\varepsilon\) | 误差项 | 模型无法解释的随机波动 | 季节、驾驶习惯等 |
重要
偏回归系数是多元回归最核心的概念。 它回答的是:在其他变量保持不变的条件下(ceteris paribus),某个自变量每变化一个单位,因变量预期变化多少?
偏回归系数 vs 简单回归系数
简单回归(不控制马力)
\[\text{mpg} = \beta_0 + \beta_1 \cdot \text{wt}\]
\(\hat{\beta}_1 = \text{车重对油耗的「总效应」}\)
问题: 重型车通常马力更大,马力本身也影响油耗。
→ \(\hat{\beta}_1\) 混入了马力的影响,无法区分两者的贡献。
多元回归(控制马力)
\[\text{mpg} = \beta_0 + \beta_1 \cdot \text{wt} + \beta_2 \cdot \text{hp}\]
\(\hat{\beta}_1 = \text{在马力相同的情况下,车重的净效应}\)
\(\hat{\beta}_2 = \text{在车重相同的情况下,马力的净效应}\)
→ 两个系数各司其职,干净地分离各自的净效应。
提示
生活类比: 你想研究"读书时长"对"考试成绩"的影响,但聪明的学生既读书多,成绩也好。如果不控制"智力水平",读书时长的系数就会被高估。多元回归就是同时控制智力水平,再来看读书时长的净效应。
用可视化理解偏回归系数
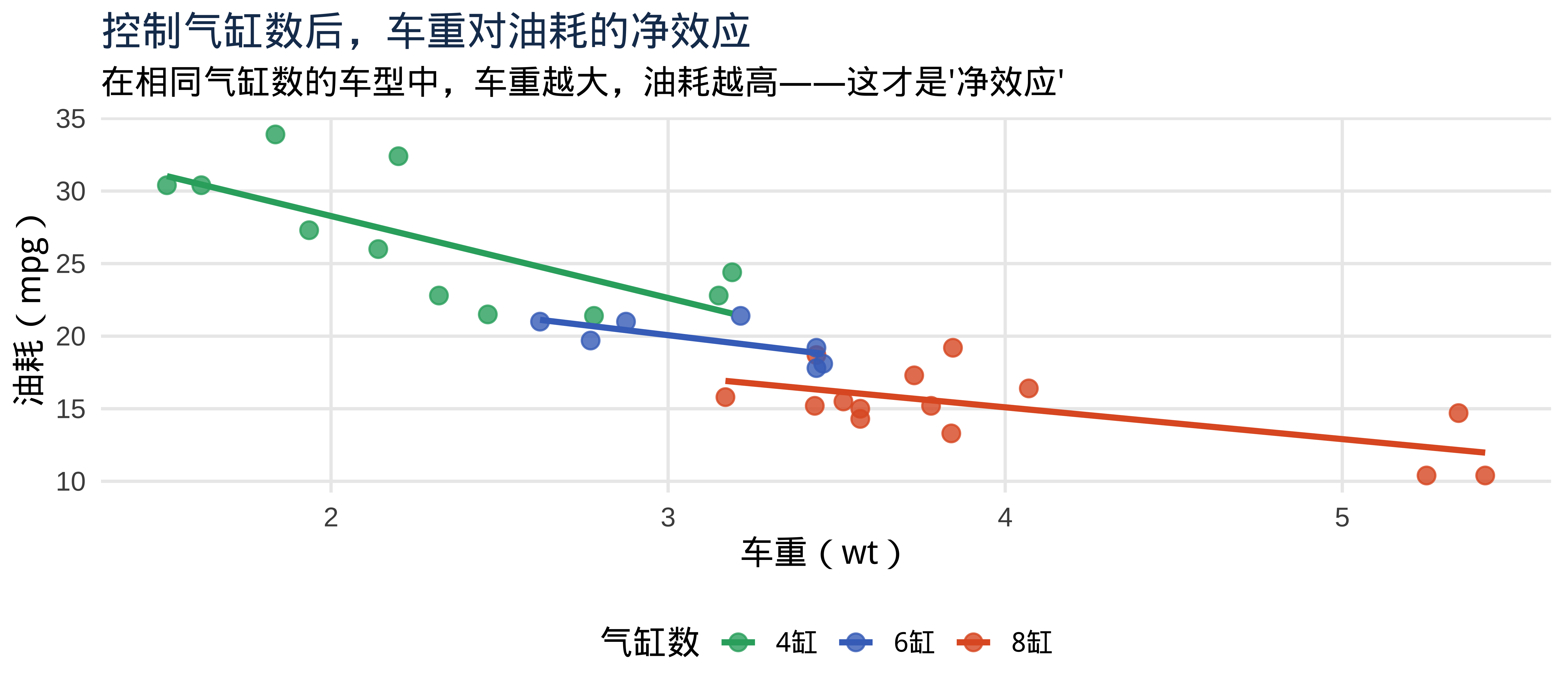
注记
每条彩色线的斜率,就近似于偏回归系数 \(\hat{\beta}_\text{wt}\)——在气缸数相同的情况下,车重每增加 1 单位,油耗下降多少。这就是多元回归在做的事。
Part 3:多重共线性
自变量之间高度相关时会发生什么?
什么是多重共线性?
多重共线性(Multicollinearity):当两个或多个自变量之间高度相关,模型就难以分辨各自的独立效应。
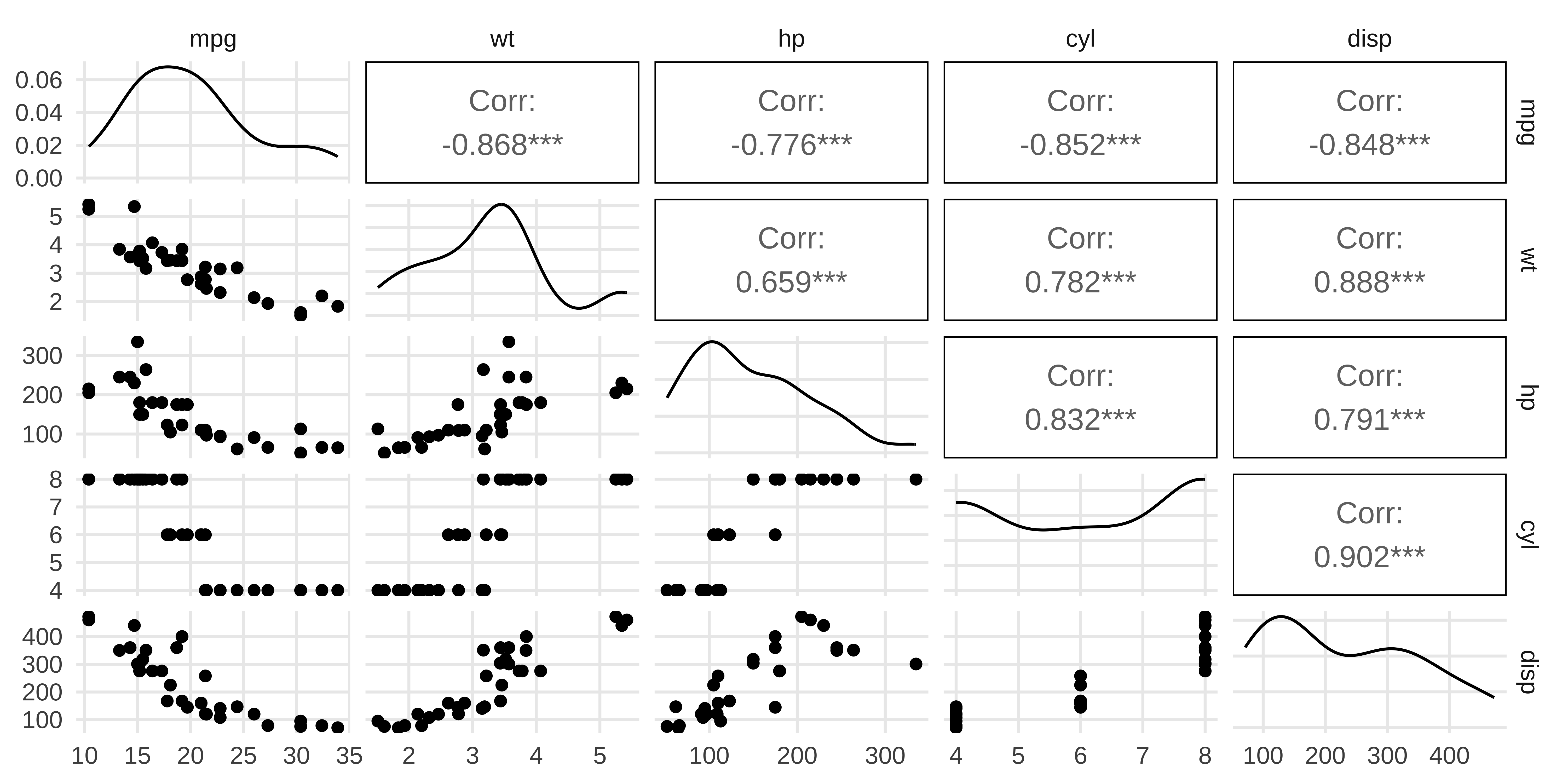
多重共线性的后果
症状:
- 系数估计值不稳定(标准误变大)
- \(p\) 值失真:本来显著的变量变得「不显著」
- 系数符号可能出错(正变负)
- 整体 \(R^2\) 可能仍然很高,但各系数不可信
- 增删一个观测值,系数就大幅波动
重要
为什么会这样?
想象两个几乎完全相关的变量 \(x_1 \approx x_2\)。
模型能解释 \(y\) 的变异,但无法分清楚:
是 \(x_1\) 功劳更大,还是 \(x_2\) 功劳更大?
就像两个人同时推了一扇门,你无法知道谁出力更多。
但多重共线性不是错误(Error),而是缺陷(Deficiency)。数据包含的信息重叠了,导致模型“左右为难”。
VIF 检验:诊断多重共线性
方差膨胀因子(Variance Inflation Factor,VIF):
\[\text{VIF}_j = \frac{1}{1 - R^2_j}\]
其中 \(R^2_j\) 是用其他所有自变量预测 \(x_j\) 的决定系数。
| VIF 值 | 含义 | 处理建议 |
|---|---|---|
| \(= 1\) | 无共线性 | 无需处理 |
| \(1 \sim 5\) | 轻度共线性 | 可接受,继续观察 |
| \(5 \sim 10\) | 中度共线性 | 需要警惕 |
| \(> 10\) | 严重共线性 | 必须处理 |
如何处理多重共线性?
-
删除一个高共线性变量:检查业务逻辑,删除信息重复的变量(如
cyl和disp都衡量发动机大小,保留一个)
- 遗漏变量偏差:如果遗漏的变量确实是因变量 \(y\) 的重要解释变量,直接删除可能会引起遗漏变量问题
- 合并变量:将高度相关的变量合并为一个综合指标(如"发动机规模指数")
主成分分析(PCA):将多个相关变量降维为互不相关的主成分,再进行回归
问题:丧失了经济学解释性。
- 岭回归(Ridge Regression):在目标函数中加入惩罚项,缩小不稳定的系数估计值
- 岭回归虽然能稳定系数,但它是有偏估计。
- 增加样本量: 多重共线性本质上是样本数据信息不足的问题(变量之间重叠太多)。如果能增加样本量,往往能缩小系数的方差,从而缓解共线性带来的不稳定性。
注记
实际操作中最常用的方案是第 ①:结合业务判断删除冗余变量,再重新检验 VIF。不要机械地套公式,要先问「这两个变量在业务上是否测量了同一件事?」
Part 4:模型选择
加哪个变量?怎么比较模型?
为什么不能用 \(R^2\) 来比较模型?
警告
陷阱: 向模型中加入任何变量(哪怕是完全随机的噪声),\(R^2\) 只增不减!
▶️ 查看代码
set.seed(42)
mtcars_noise <- mtcars |>
mutate(
random1 = rnorm(n()), # 完全随机噪声
random2 = rnorm(n())
)
m_base <- lm(mpg ~ wt, data = mtcars_noise)
m_noise1 <- lm(mpg ~ wt + random1, data = mtcars_noise)
m_noise2 <- lm(mpg ~ wt + random1 + random2, data = mtcars_noise)
# 比较 R² 和 Adjusted R²
modelsummary(list(m_base, m_noise1, m_noise2),
stars = T)| (1) | (2) | (3) | |
|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |||
| (Intercept) | 37.285*** | 36.858*** | 36.847*** |
| (1.878) | (1.971) | (2.003) | |
| wt | -5.344*** | -5.200*** | -5.202*** |
| (0.559) | (0.594) | (0.603) | |
| random1 | -0.365 | -0.373 | |
| (0.476) | (0.484) | ||
| random2 | -0.169 | ||
| (0.536) | |||
| Num.Obs. | 32 | 32 | 32 |
| R2 | 0.753 | 0.758 | 0.759 |
| R2 Adj. | 0.745 | 0.741 | 0.733 |
| AIC | 166.0 | 167.4 | 169.3 |
| BIC | 170.4 | 173.3 | 176.6 |
| Log.Lik. | -80.015 | -79.694 | -79.638 |
| F | 91.375 | 45.352 | 29.328 |
| RMSE | 2.95 | 2.92 | 2.91 |
提示
观察: 加入噪声变量后,\(R^2\) 略微上升,但 Adjusted \(R^2\) 下降了。这正是 Adjusted \(R^2\) 存在的意义。
Adjusted \(R^2\):惩罚多余变量
\[\text{Adjusted } R^2 = 1 - \frac{\text{SS}_\text{Res} / (n - k - 1)}{\text{SS}_\text{Total} / (n - 1)}\]
其中 \(k\) 是自变量的个数,\(n\) 是样本量。
与 \(R^2\) 的区别:
- \(R^2\):加任何变量只增不减
- Adjusted \(R^2\):加入无用变量时会下降
使用场景:
- 比较含不同数量自变量的模型时,必须用 Adjusted \(R^2\)
- 不要用 \(R^2\)
注记
实用规则:
- 加入新变量后,Adjusted \(R^2\) 上升 → 变量有贡献,保留
- 加入新变量后,Adjusted \(R^2\) 下降 → 变量无贡献,可考虑去掉
注意:Adjusted \(R^2\) 不是越大越好,还要结合业务逻辑和 VIF。
AIC:更严格的模型选择准则
赤池信息量准则(Akaike Information Criterion,AIC):
\[\text{AIC} = 2k - 2\ln(\hat{L})\]
其中 \(k\) 是参数个数(含截距),\(\hat{L}\) 是模型的最大似然值。
注记
- AIC 越小越好
- AIC 同时奖励拟合度(\(-2\ln\hat{L}\) 越小说明拟合越好),并惩罚模型复杂度(\(2k\) 随参数增多而增大)
- 两个模型 AIC 差值 \(> 2\),认为有实质性差异;\(< 2\),认为无明显区别
逐步回归:自动化模型选择
step() 函数基于 AIC 自动进行变量筛选:
▶️ 查看代码
# 后向消除:从全变量模型开始,逐步删除变量
model_full <- lm(mpg ~ ., data = mtcars) # "." 表示所有变量
step(model_full, direction = "backward")
# 前向选择:从空模型开始,逐步加入变量
model_null <- lm(mpg ~ 1, data = mtcars)
step(model_null,
scope = list(lower = model_null, upper = model_full),
direction = "forward")
# 双向逐步(最常用)
step(model_full, direction = "both")重要
逐步回归的局限:
- 结果依赖于起点模型和变量进入顺序
- 自动选出的模型未必最合理,可能遗漏理论上必须控制的变量
- 是探索性工具,不能替代领域知识和理论指导
- 用于「我不知道该加哪些变量」的初步探索,最终模型还需业务验证
- 统计显著性 \(\neq\) 经济/社会学意义。自动筛选可能剔除掉理论上非常重要但样本量不足的变量。
Part 5:R 实战
lm() 多元语法 · vif() · 逐步回归
第一步:建立并比较多个模型
▶️ 查看代码
| (1) | (2) | (3) | |
|---|---|---|---|
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 | |||
| (Intercept) | 37.285*** | 37.227*** | 38.752*** |
| (1.878) | (1.599) | (1.787) | |
| wt | -5.344*** | -3.878*** | -3.167*** |
| (0.559) | (0.633) | (0.741) | |
| hp | -0.032** | -0.018 | |
| (0.009) | (0.012) | ||
| cyl | -0.942+ | ||
| (0.551) | |||
| Num.Obs. | 32 | 32 | 32 |
| R2 | 0.753 | 0.827 | 0.843 |
| R2 Adj. | 0.745 | 0.815 | 0.826 |
| AIC | 166.0 | 156.7 | 155.5 |
| BIC | 170.4 | 162.5 | 162.8 |
| Log.Lik. | -80.015 | -74.326 | -72.738 |
| F | 91.375 | 69.211 | 50.171 |
| RMSE | 2.95 | 2.47 | 2.35 |
第二步:精读 summary() 输出
Call:
lm(formula = mpg ~ wt + hp, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.941 -1.600 -0.182 1.050 5.854
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 37.22727 1.59879 23.28 < 2e-16 ***
wt -3.87783 0.63273 -6.13 1.1e-06 ***
hp -0.03177 0.00903 -3.52 0.0015 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.59 on 29 degrees of freedom
Multiple R-squared: 0.827, Adjusted R-squared: 0.815
F-statistic: 69.2 on 2 and 29 DF, p-value: 9.11e-12逐行解读:偏回归系数
根据上方输出,m2 的回归方程为:
\[\widehat{\text{mpg}} = 37.23 - 3.88 \times \text{wt} - 0.032 \times \text{hp}\]
\(\hat{\beta}_\text{wt} = -3.88\)(控制 hp 后)
在马力相同的情况下,车重每增加 1000 磅,每加仑里程预期下降 3.88 英里。
注意:简单回归(m1)中这个系数是 \(-5.34\),现在变成了 \(-3.88\)。
→ 说明 m1 中 wt 的效应被高估了,有一部分其实是马力的贡献。
\(\hat{\beta}_\text{hp} = -0.032\)(控制 wt 后)
在车重相同的情况下,马力每增加 1 匹,每加仑里程预期下降 0.032 英里。
Adjusted \(R^2\) 从 0.745(m1)提升到 0.826(m2),说明马力提供了额外的解释力。
提示
业务语言解读的模板:
「在控制了 [其他变量] 的前提下,[x 变量] 每增加 [1 个单位],[y 变量] 预期变化 [系数值] 个单位(\(p = \ldots\),[显著/不显著])。」
第三步:检验多重共线性
警告
disp 的 VIF 超过 10,说明存在严重多重共线性。在 m4 中,这个变量的系数估计不可信,不建议同时使用cyl 和 disp。
Part 6:模型诊断
回归假设是否成立?
四张图,一行代码
OLS 的结论成立,依赖四个核心假设。违反任何一个,系数估计或推断就可能失效。
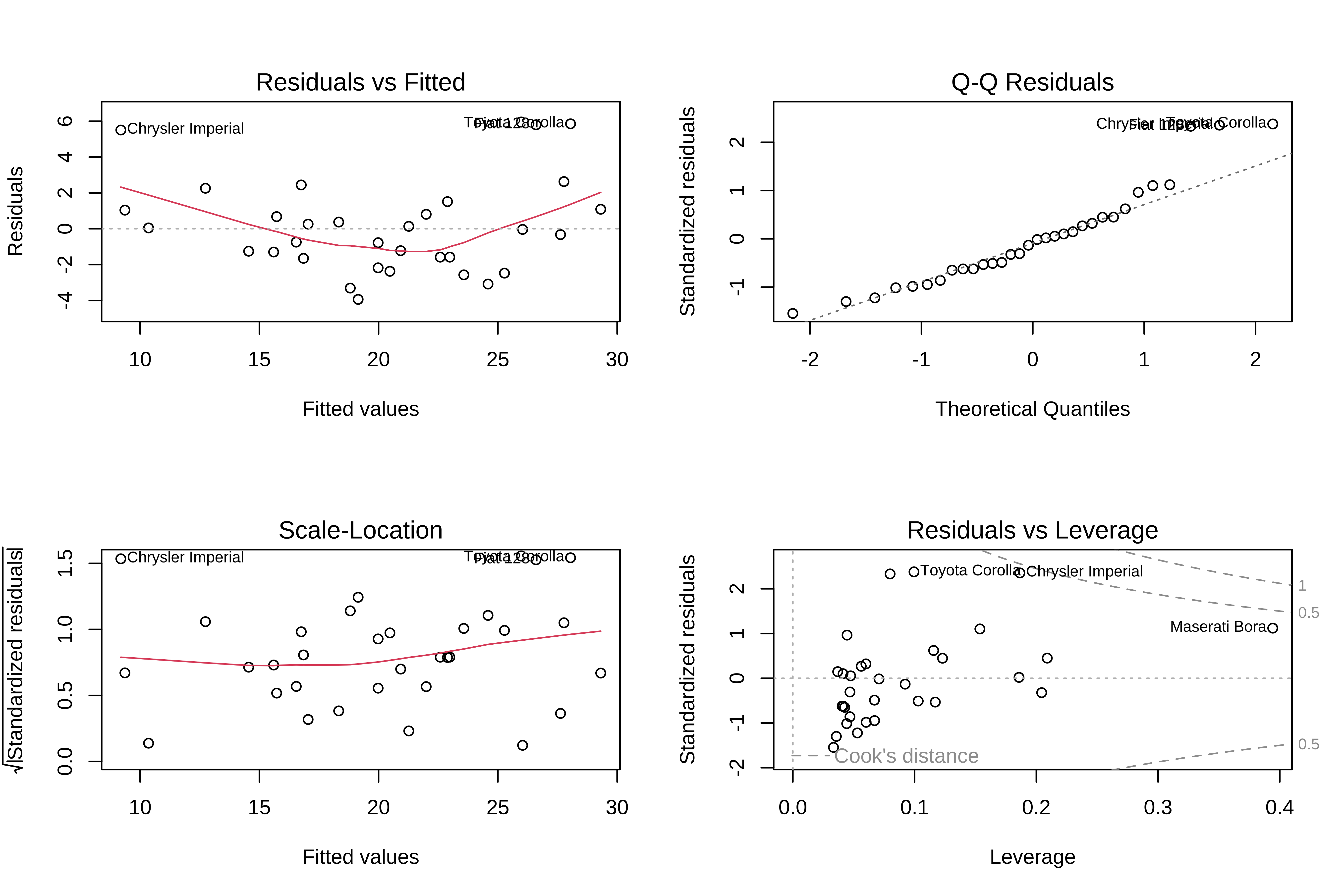
| 图名 | 横轴 | 纵轴 | 看什么 |
|---|---|---|---|
| Residuals vs Fitted | 拟合值 | 残差 | 是否有非线性结构?残差应随机散布在 0 附近 |
| Q-Q Plot | 理论分位数 | 残差分位数 | 残差是否近似正态?点应落在对角线上 |
| Scale-Location | 拟合值 | \(\sqrt{|\text{标准化残差}|}\) | 方差是否齐次?红线应水平 |
| Residuals vs Leverage | 杠杆值 | 标准化残差 | 是否有强影响点?库克距离 \(> 0.5\) 需关注 |
常见问题与对策
非线性(Residuals vs Fitted 出现弧形)
→ 尝试对变量取对数或加入二次项
异方差(Scale-Location 红线倾斜)
→ 对因变量取对数;或使用稳健标准误 lm_robust()
非正态残差(Q-Q 图尾部偏离)
→ 样本量大时影响较小(中心极限定理);严重时考虑变量变换
强影响点(库克距离过大)
→ 核查数据录入是否有误;报告时说明去除后结论是否稳健
注记
诊断不是为了追求「完美」,而是确认结论的可信度边界。发现问题后,先检查数据质量,再考虑模型变换,最后报告局限性。
Part 7:你必须掌握什么?
学习路线图
必须掌握(核心概念)
重要
以下内容是本课程的基础,期末考试必考,实际工作必用:
偏回归系数的含义:能用中文解释「在控制其他变量的前提下,\(x_j\) 每增加 1 个单位,\(y\) 预期变化 \(\hat{\beta}_j\)」——这是多元回归最核心的能力
多元回归方程的结构:\(y = \beta_0 + \beta_1 x_1 + \cdots + \beta_k x_k + \varepsilon\),能写出方程并解释每个系数
多重共线性的概念与检测:知道 VIF 是什么,VIF \(> 10\) 意味着严重共线性
Adjusted \(R^2\) 的用途:与 \(R^2\) 的区别;比较含不同数量自变量的模型时,必须用 Adjusted \(R^2\)
R 语言操作:
lm(y ~ x1 + x2 + x3)、vif()
理解即可
注记
以下内容理解含义即可,不需要记公式、不需要手算:
OLS 在多元情况下的矩阵形式:\(\hat{\boldsymbol{\beta}} = (\mathbf{X}^\top \mathbf{X})^{-1} \mathbf{X}^\top \mathbf{y}\)——知道 R 在帮你算就好
AIC 的数学推导:知道「AIC 越小越好」,知道它同时考虑拟合度和复杂度
VIF 的计算公式:\(\text{VIF}_j = 1 / (1 - R^2_j)\)——用
vif()函数直接得到偏 \(F\) 检验:多元回归中检验「加入某变量后模型是否显著改善」的检验
常见错误清单
警告
以下是初学者最容易犯的错误,请对照检查:
| 错误 | 正确理解 |
|---|---|
| 「加变量越多,模型越好」 | 加无用变量使 Adjusted \(R^2\) 下降、系数估计不稳定;变量选择要靠 Adj.\(R^2\) 和 AIC |
| 「偏回归系数 = 简单回归系数」 | 多元回归的 \(\hat{\beta}_1\) 是「控制其他变量后」的净效应,数值上可以差异很大,甚至符号相反 |
| 「VIF \(> 5\) 就要立刻删掉变量」 | VIF 是警示信号,不是一刀切规则;如果变量理论上必须保留,VIF 略高也可接受 |
| 「逐步回归选出的就是最好的模型」 | 逐步回归是探索工具,最终模型还需领域知识验证;可能遗漏重要的业务控制变量 |
| 「\(R^2 = 0.85\) 说明模型很好」 | \(R^2\) 高不代表模型合理;还要看系数方向是否符合业务逻辑、VIF、残差图 |
知识结构回顾
本讲小结
为什么需要多元回归:简单回归忽略混淆变量会导致遗漏变量偏差;纳入多个 \(x\) 才能分离各自的净效应
偏回归系数:\(\hat{\beta}_j\) 是「其他变量不变」条件下 \(x_j\) 的净效应(ceteris paribus);多元回归的核心概念
多重共线性:自变量高度相关时,系数估计不稳定;用 VIF 诊断,VIF \(> 10\) 需处理
模型选择:比较模型用 Adjusted \(R^2\) 和 AIC,不要用 \(R^2\);
step()做逐步回归,但结果需业务验证
课后练习
基础练习(必做)
- 使用
mtcars数据集,建立用wt+hp+am预测mpg的多元回归模型。解释每个偏回归系数的业务含义,并与第 10 讲只用wt的简单回归比较 Adjusted \(R^2\)
Call:
lm(formula = mpg ~ wt + hp + drat, data = mtcars)
Residuals:
Min 1Q Median 3Q Max
-3.360 -1.837 -0.510 0.968 5.708
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 29.39493 6.15630 4.77 5.1e-05 ***
wt -3.22795 0.79640 -4.05 0.00036 ***
hp -0.03223 0.00892 -3.61 0.00118 **
drat 1.61505 1.22698 1.32 0.19876
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.56 on 28 degrees of freedom
Multiple R-squared: 0.837, Adjusted R-squared: 0.819
F-statistic: 47.9 on 3 and 28 DF, p-value: 3.77e-11 1
12.2 对上述模型运行
vif(),判断是否存在多重共线性。如果有,尝试删除 VIF 最高的变量并重新拟合,比较两个模型的系数变化用
step()对mtcars的全变量模型进行逐步回归,观察最终被保留的变量,并说明为什么你认为这个结果合理或不合理
进阶挑战(选做)
使用
diamonds数据集,建立用carat、cut、color、clarity预测log(price)的多元回归模型。观察 R 如何自动将因子变量(cut等)转换为哑变量,并解释哑变量系数的含义辛普森悖论思考题:在某些情况下,控制一个变量后,另一个变量的系数符号会发生反转。你能想到现实生活或工作中一个「不控制分组变量时结论相反」的案例吗?(提示:大学录取率与性别的关系)
下讲预告
第12讲:分类变量、对数变量
- 分类变量的回归与解释
- 对数变量的解释与应用
提示
今天的多元回归告诉你「系数是多少」。诊断告诉你「这个系数可不可信」。两者缺一不可,合在一起才是一个完整的回归分析。
谢谢!
第11讲:多元线性回归
「多元回归让我们能够同时看清多个因素的独立作用, 这是从描述走向解释的关键一步。」
数据挖掘与R语言 | 第11讲:多元线性回归