数据挖掘与R语言
第12讲:对数回归与分类自变量
2026年05月08日
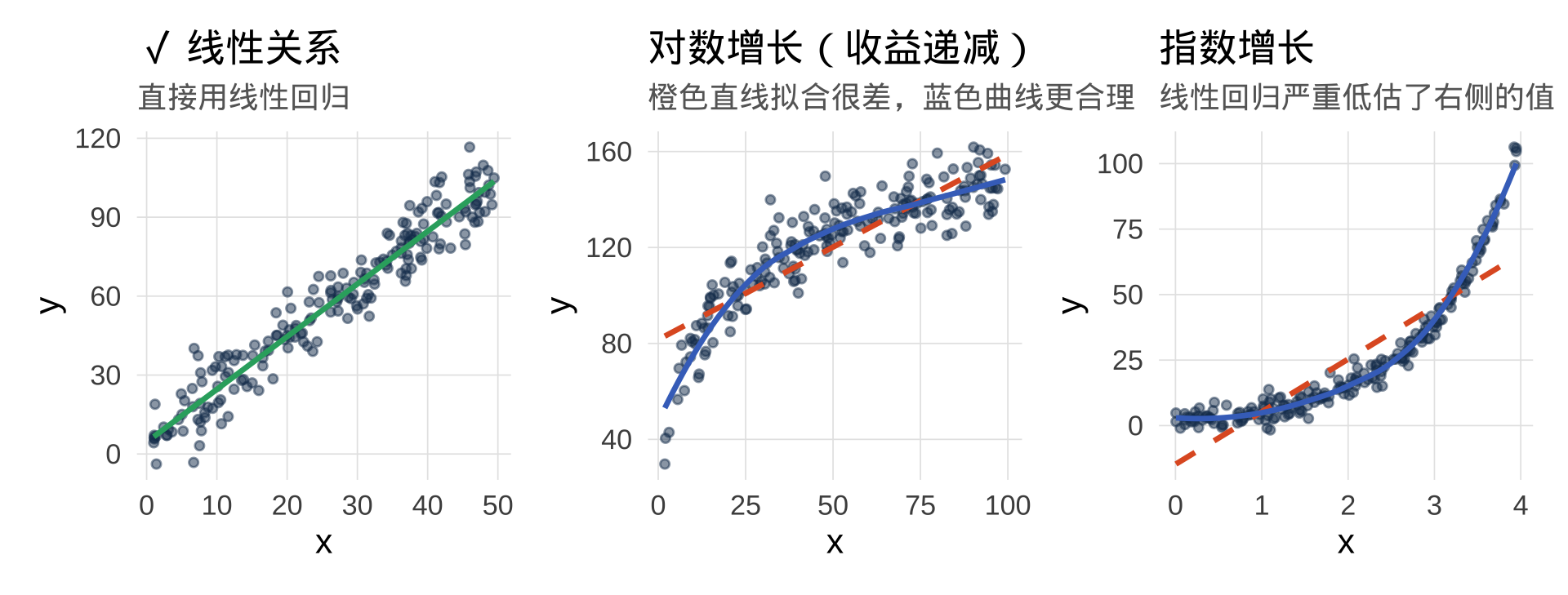
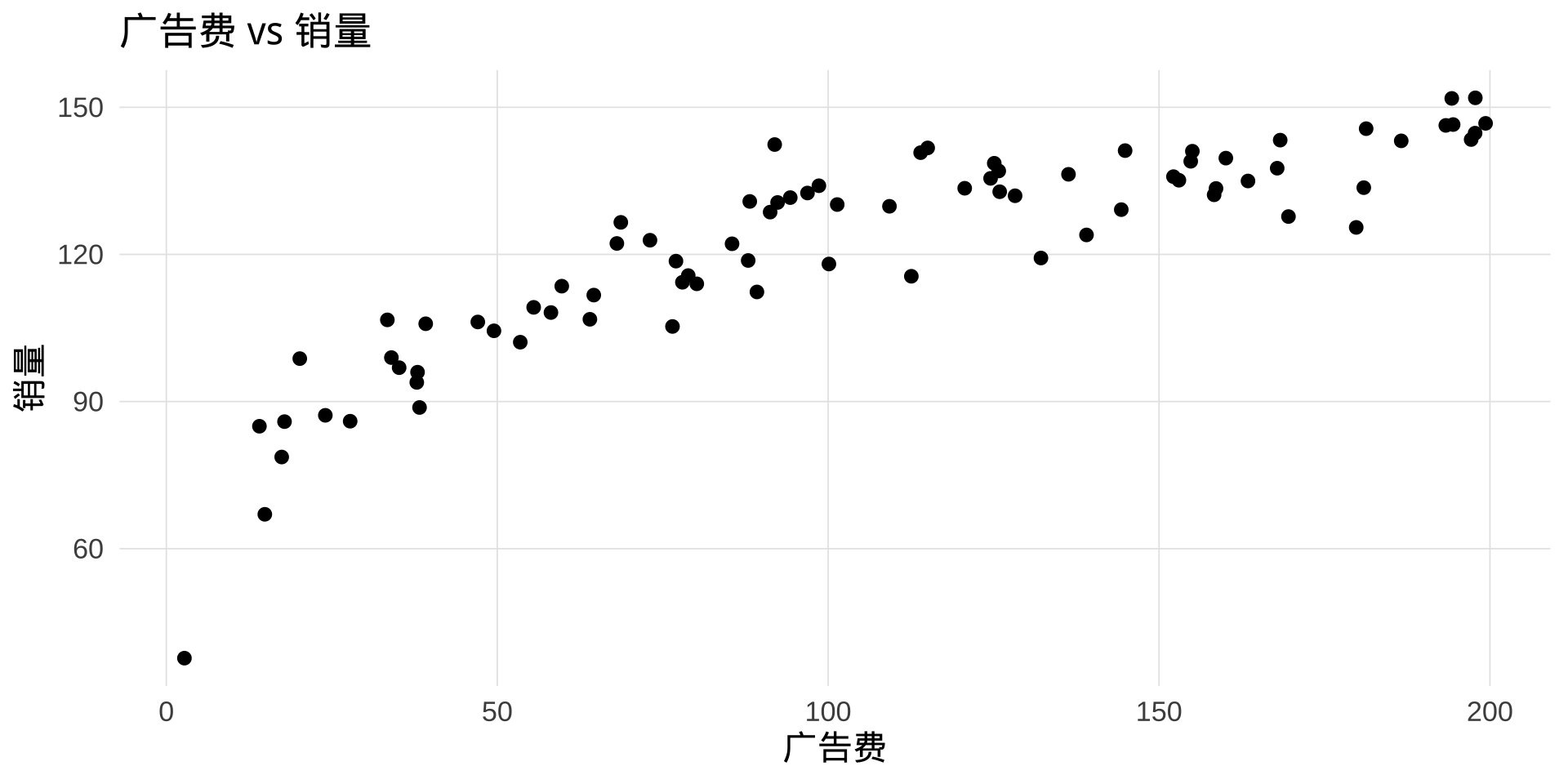
问题背景:广告费与销量
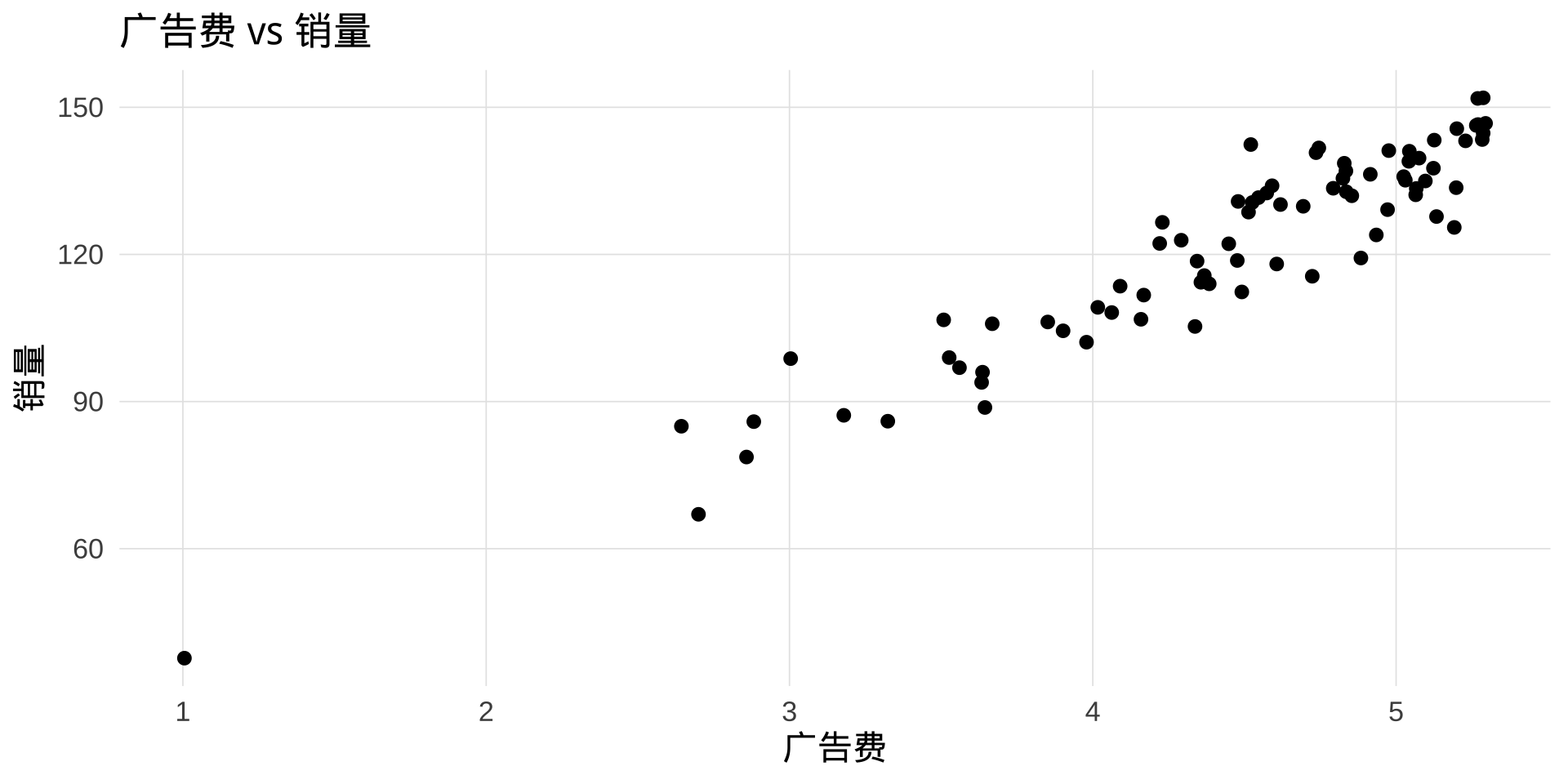
现实规律: 广告的边际效益是递减的——第一个 100 万效果显著,第二个 100 万效果没那么好。这是对数增长,不是线性增长。
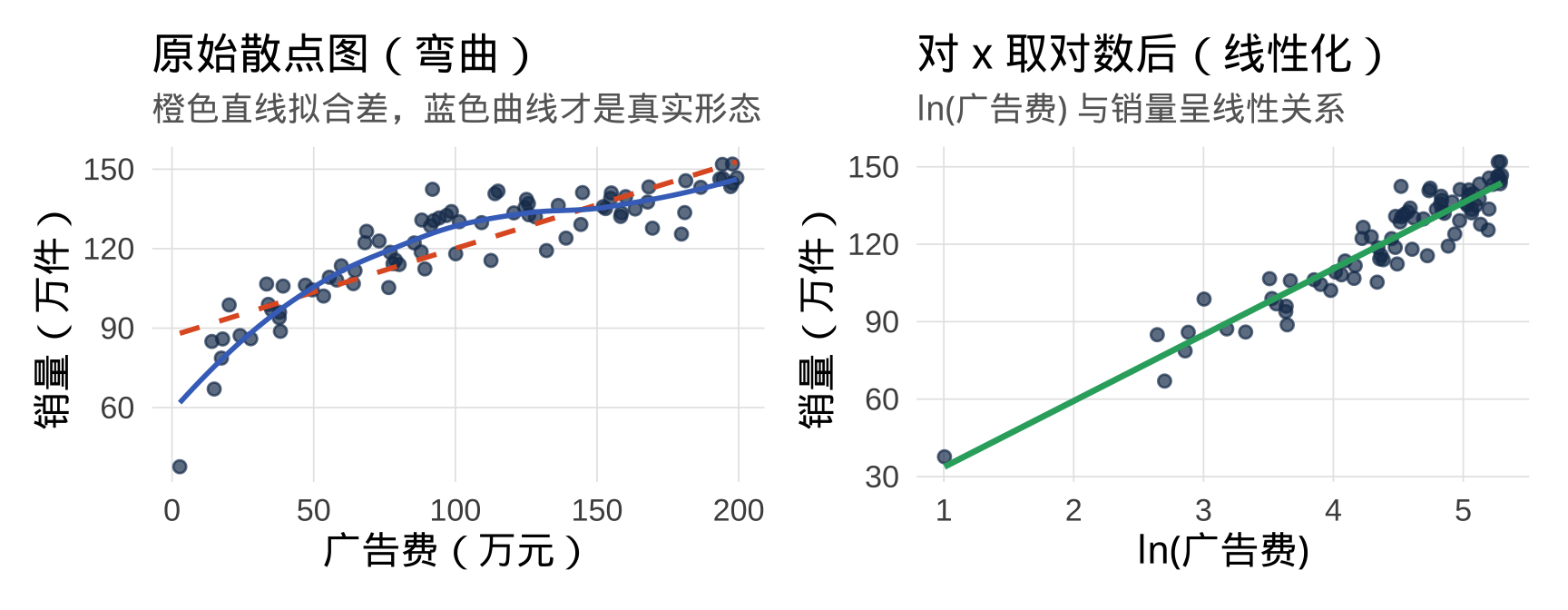
建立 level-log 模型
▶️ 查看代码
▶️ 查看代码
▶️ 查看代码
Call:
lm(formula = 销量 ~ log(广告费), data = ad_log)
Residuals:
Min 1Q Median 3Q Max
-15.517 -4.578 0.646 4.533 18.558
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 8.09 4.59 1.76 0.082 .
log(广告费) 25.61 1.02 25.10 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7.13 on 78 degrees of freedom
Multiple R-squared: 0.89, Adjusted R-squared: 0.888
F-statistic: 630 on 1 and 78 DF, p-value: <2e-16问题背景:工作经验与工资
现实规律: 工资随经验的增长往往是指数型的——从 0 到 5 年涨幅小,从 20 到 25 年涨幅相对大。对 \(y\) 取对数后,关系趋于线性。
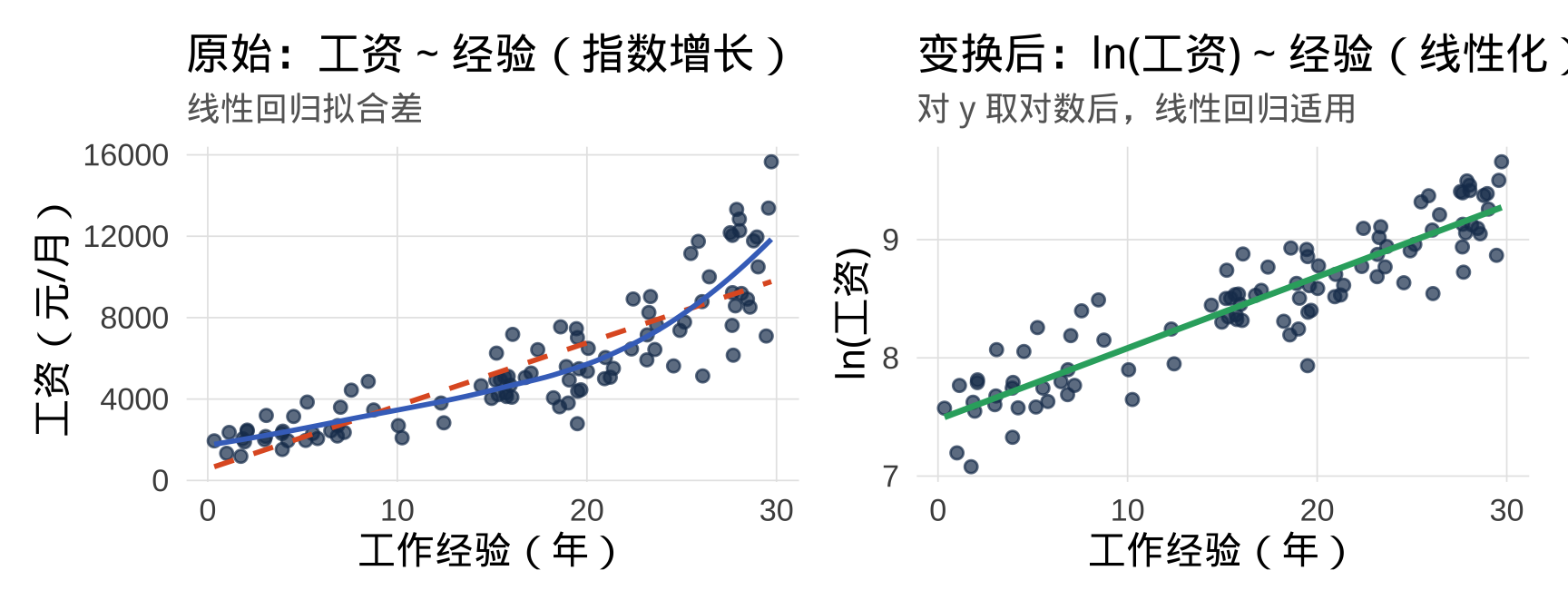
还原预测值:反对数变换
重要
注意: log-level 模型预测的是 \(\ln(y)\),不是 \(y\) 本身。需要做反变换才能得到原始尺度的预测值。
▶️ 查看代码
ln(工资) 的预测值: 8.08 工资的预测值(元/月): 3236 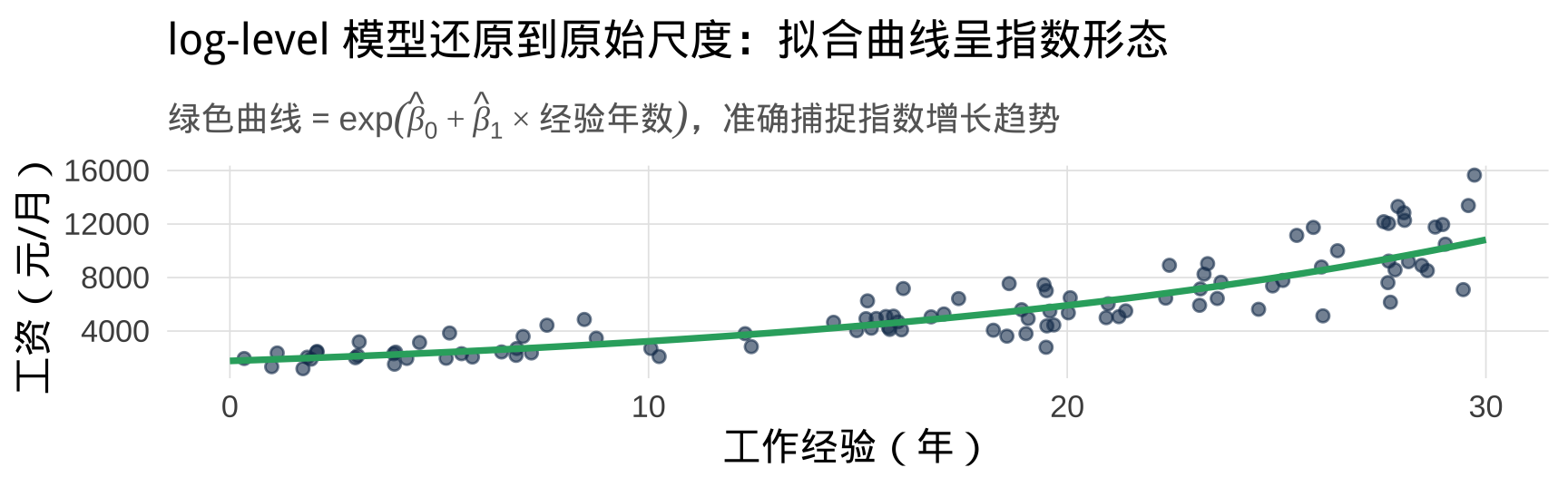
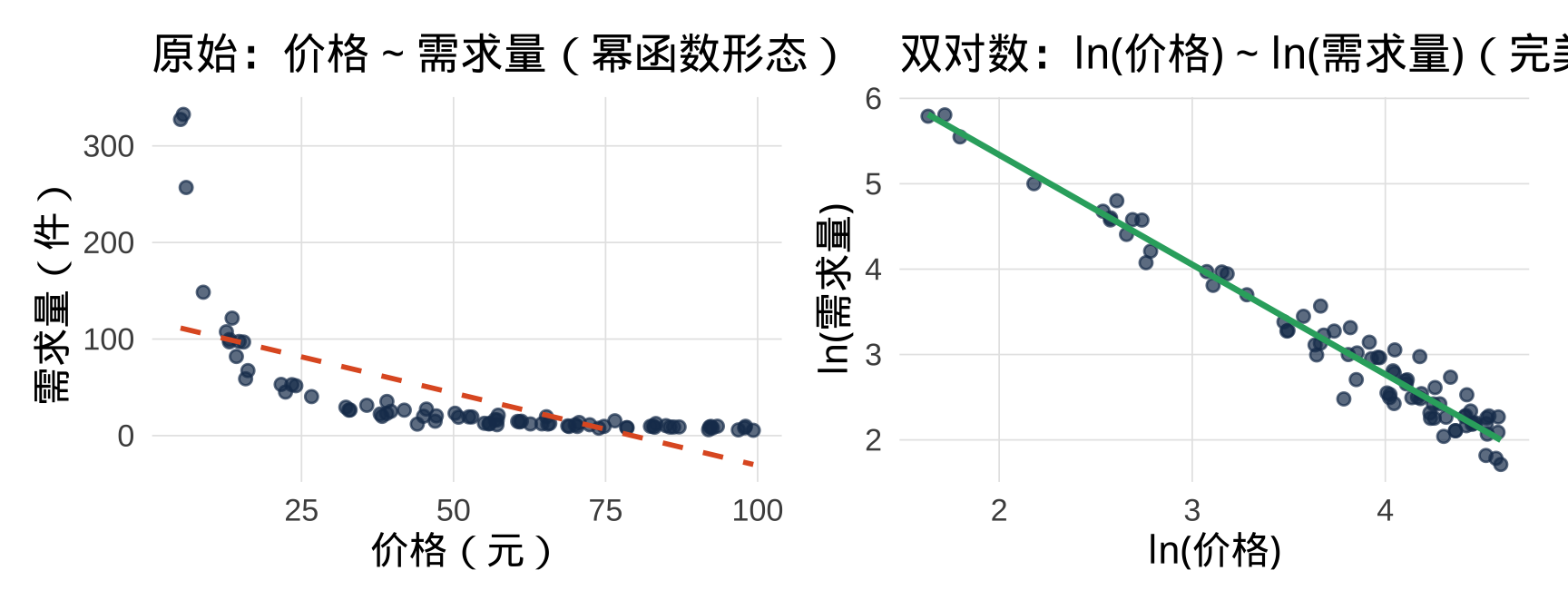
问题背景:价格与需求量
经济学核心概念: 价格弹性——价格上涨 1%,需求量下降几个百分点?log-log 模型的斜率直接就是弹性系数。
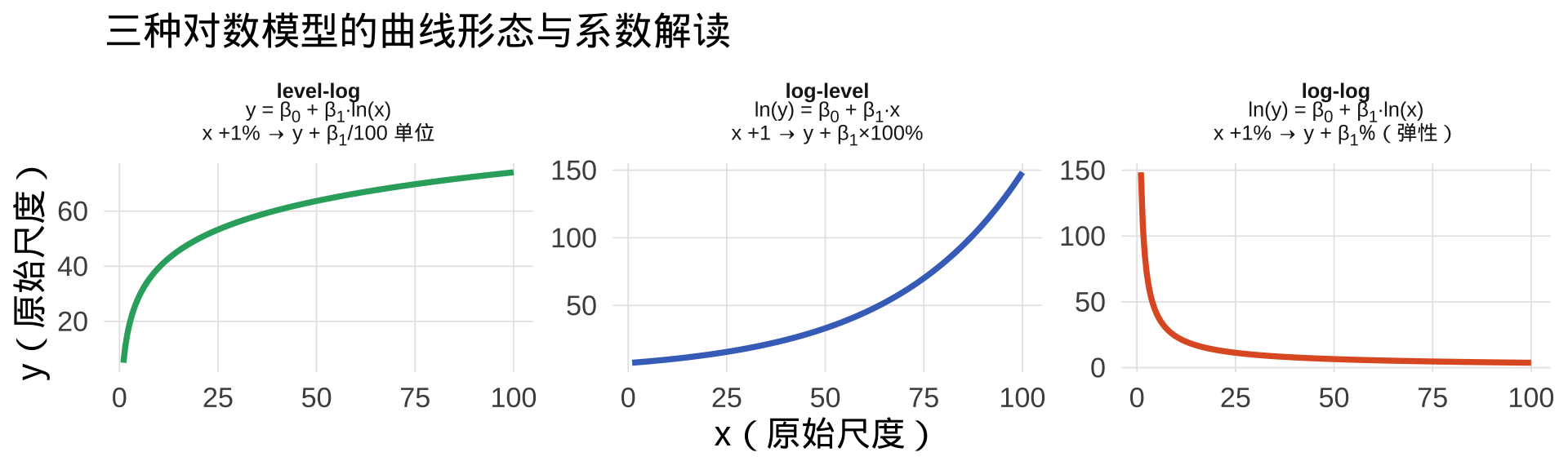
三种对数模型对比总结
解读虚拟变量系数
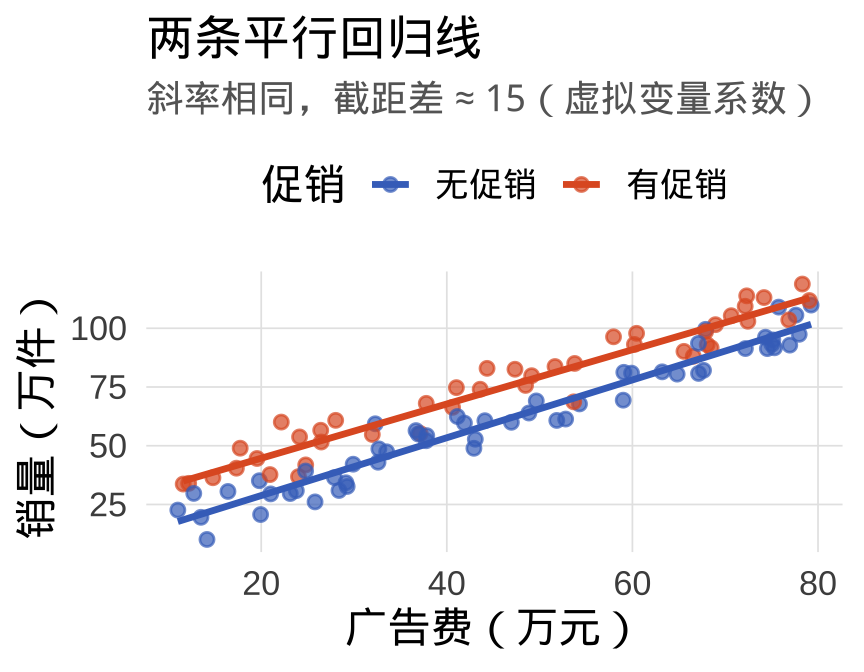
根据输出,回归方程为:
\[\widehat{\text{销量}} = \hat{\beta}_0 + 1.21 \times \text{广告费} + 14.9 \times D_{\text{有促销}}\]
\(\hat{\beta}_{\text{有促销}} = 14.9\) 的含义:
在广告费相同的情况下,有促销活动的月份比无促销月份销量平均高 14.9 万件(\(p < 0.001\),极其显著)。
这是促销对销量的净效应——已控制广告费的影响。
注记
两条平行线的直觉: 虚拟变量模型假设两组斜率相同,只有截距不同。橙色线(有促销)整体比蓝色线(无促销)高约 15 个单位——这就是虚拟变量系数的几何意义。
解读三类虚拟变量系数
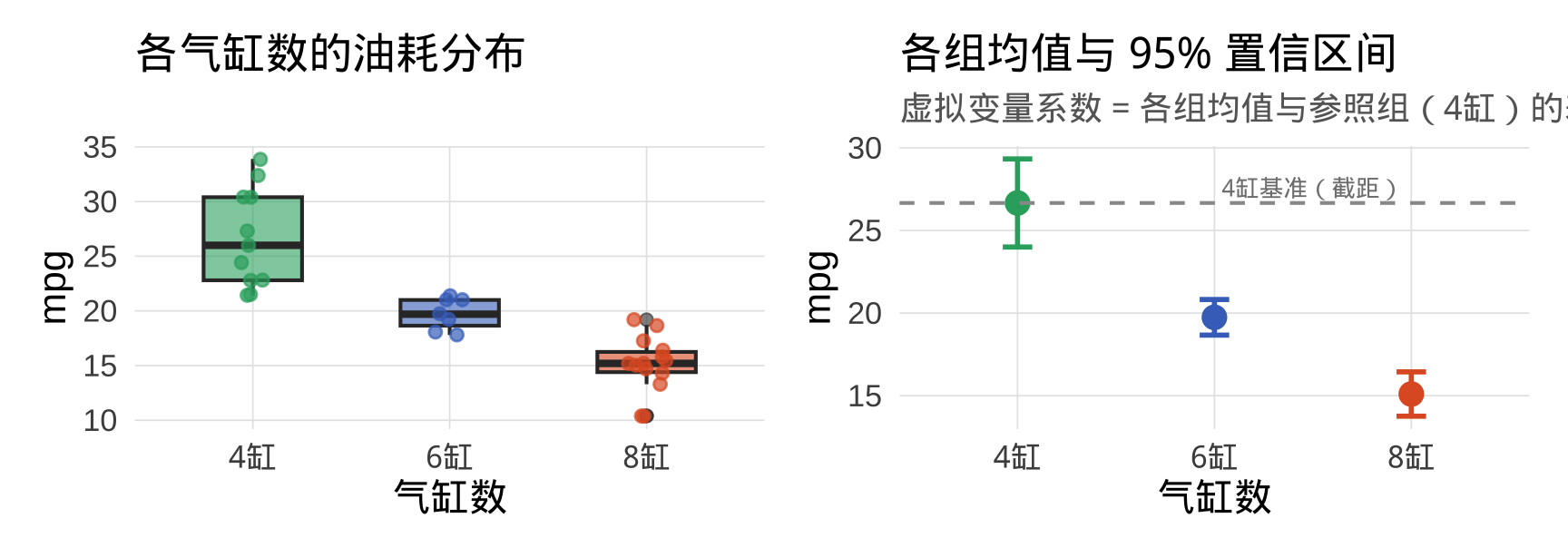
根据输出:
\[\widehat{\text{mpg}} = 26.66 - 6.92 \times D_{\text{6缸}} - 11.56 \times D_{\text{8缸}}\]
| 系数 | 数值 | 含义 |
|---|---|---|
| 截距 \(= 26.66\) | — | 4 缸车的平均油耗(英里/加仑) |
| \(\hat{\beta}_{\text{6缸}} = -6.92\) | \(p < 0.001\) | 6 缸车比 4 缸平均低 6.92 英里/加仑 |
| \(\hat{\beta}_{\text{8缸}} = -11.56\) | \(p < 0.001\) | 8 缸车比 4 缸平均低 11.56 英里/加仑 |
可视化五类虚拟变量系数
注记
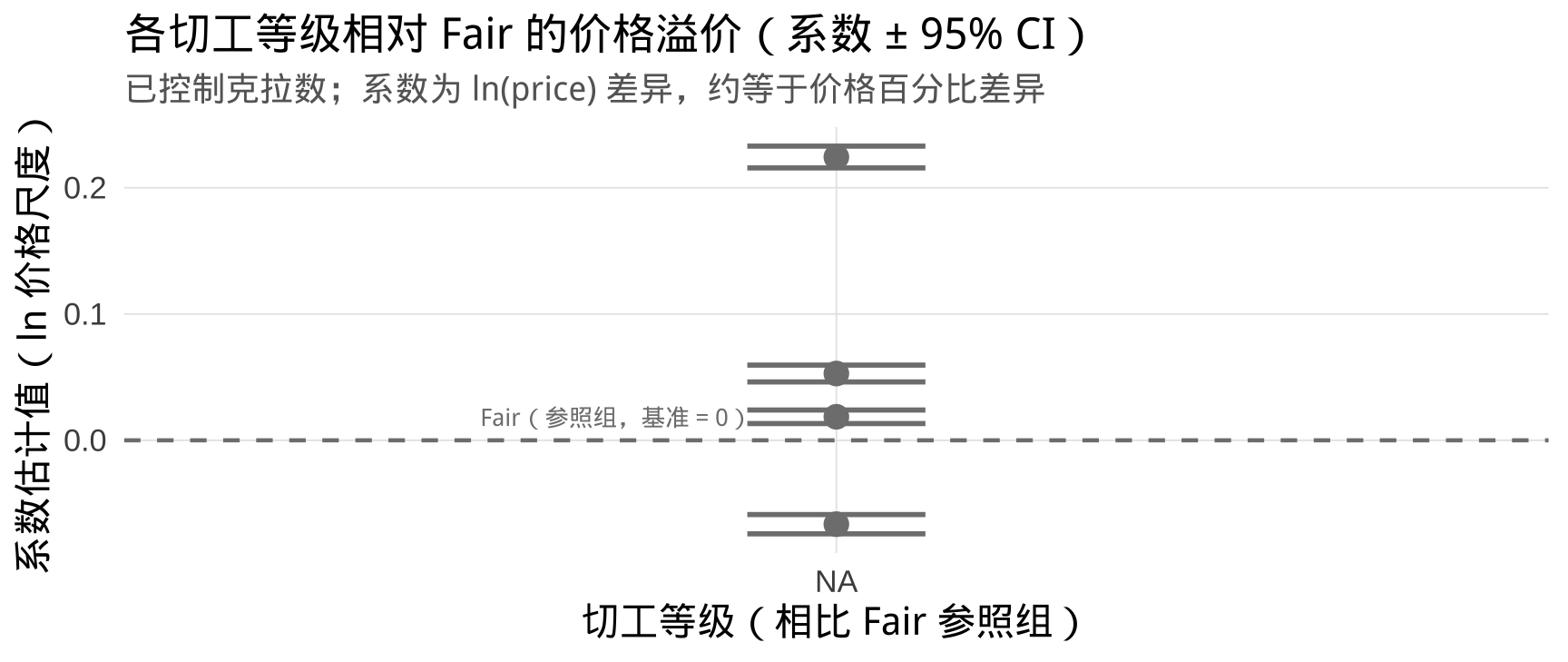
有趣的发现: 控制克拉数后,Ideal(最高切工)相比 Fair 的价格溢价约为 12%。但 Premium 与 Very Good 之间差异很小——消费者愿意为「顶级切工」额外支付的溢价,远小于为「克拉数」支付的溢价。
知识结构回顾
