gpa admitted
1 2.3 0
2 3.0 1
3 2.5 0
4 2.9 1
5 3.7 1
6 3.6 1
7 3.2 1
8 3.4 1数据挖掘与R语言
第13讲:逻辑回归——原理与初步实操
2026年05月13日
上讲回顾
- 对数变换:解决 \(y\) 与 \(x\) 非线性关系;level-log / log-level / log-log 三种形式
- 虚拟变量:将分类自变量引入回归;系数 = 该类别相对参照组的均值差
-
\(k\) 类别用 \(k-1\) 个虚拟变量:R 的
factor()自动处理 - 模型比较:用 Adjusted \(R^2\) 和 AIC
- 以上所有模型,因变量 \(y\) 都是连续型数值。如果 \(y\) 只能取 0 或 1,怎么办? 这是今天的起点
本讲内容
- Part 1:问题的起点 ——线性概率模型的三个缺陷
- Part 2:数学推导 ——从概率到 Odds,再到 Logit,最后回到概率
- Part 3:系数如何解读 ——不是概率变化,而是优势比
- Part 4:R 实操演示 ——用录取数据走完完整流程
- Part 5:你必须掌握什么 ——学习路线图与常见错误
Part 1:问题的起点
线性概率模型的三个缺陷
今天研究的问题
用 GPA 预测学生能否被录取(admitted = 1/0)
这是一个二值因变量(binary outcome)问题。我们的目标是:
\[\text{预测} \quad P(\text{admitted} = 1 \mid \text{gpa} = x)\]
如果直接用线性回归……
Call:
lm(formula = admitted ~ gpa, data = admissions)
Residuals:
Min 1Q Median 3Q Max
-1.1202 -0.1652 -0.0008 0.2379 1.0735
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.2673 0.0380 -33.3 <2e-16 ***
gpa 0.5969 0.0124 48.0 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.345 on 2098 degrees of freedom
Multiple R-squared: 0.524, Adjusted R-squared: 0.523
F-statistic: 2.31e+03 on 1 and 2098 DF, p-value: <2e-16线性回归的预测结果
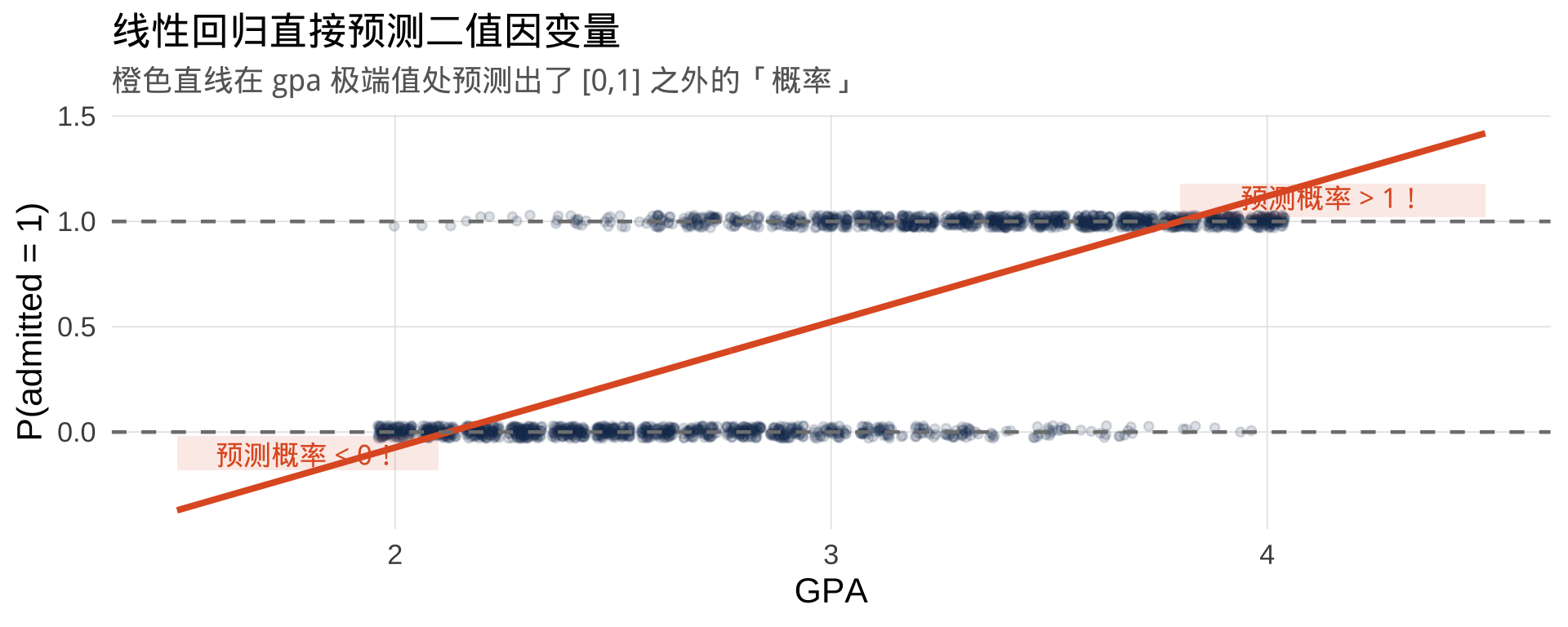
三个根本性缺陷
缺陷一:预测值超出 \([0, 1]\)
概率不可能是负数,也不可能大于 1。GPA 很低时预测为负,GPA 很高时预测超过 1。
. . .
缺陷二:残差不满足正态性
\(Y\) 只取 0 或 1,残差只有两种值,绝无可能服从正态分布。
. . .
缺陷三:天然异方差
\[\text{Var}(Y_i) = P_i(1 - P_i)\]
方差随 \(P_i\) 变化,OLS 的等方差假设天然被违反。
重要
结论
线性回归在理论和假设上都不适合处理二值因变量。
我们需要一种新方法,满足:
- 预测值始终在 \((0,1)\) 内
- 捕捉 \(X\) 与 \(P\) 之间的S 形关系
- 不依赖正态残差假设
这就是逻辑回归的动机。
Part 2:数学推导
三步变换:概率 → Odds → Logit → 线性模型
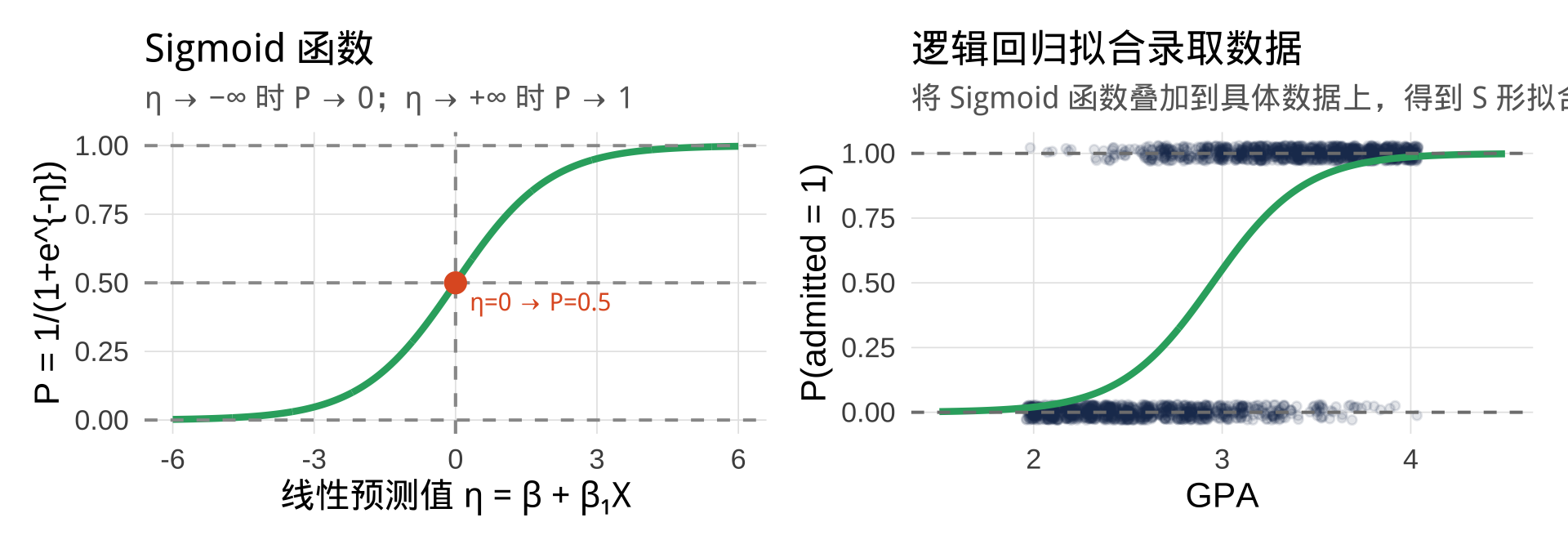
第一步:认识 S 形曲线
观察数据散点图,\(P(\text{admitted}=1)\) 随 GPA 增长的真实形态并非直线,而是一条 S 形曲线:
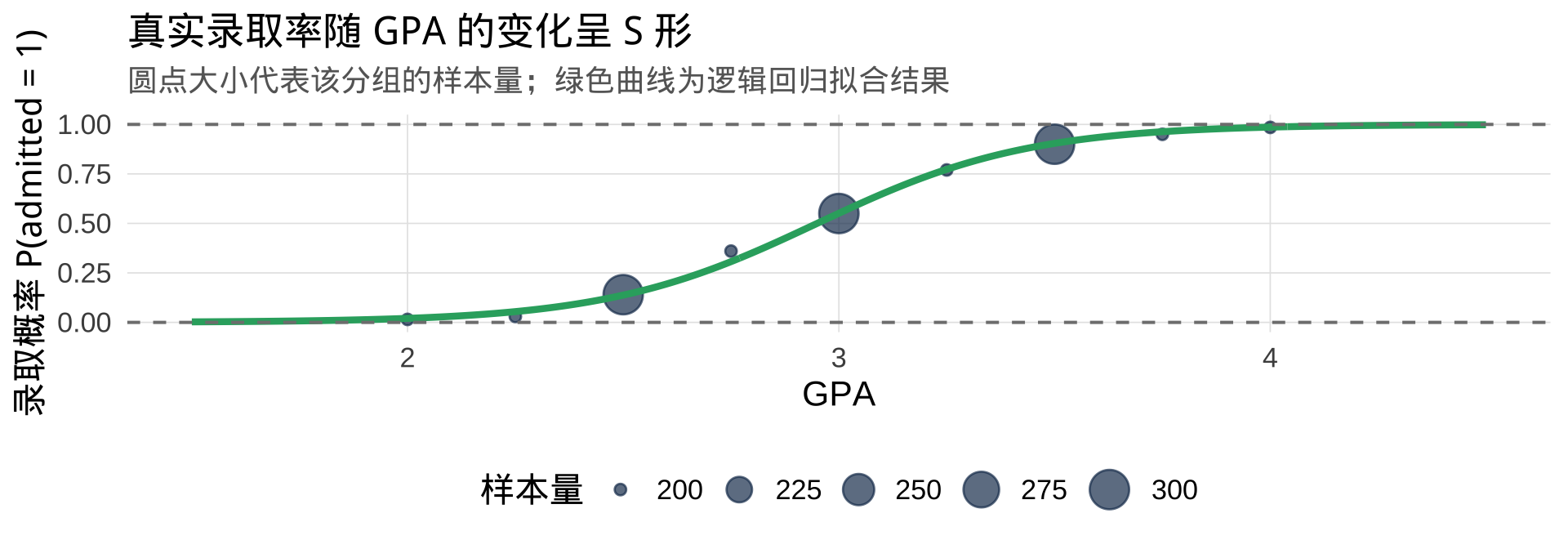
我们需要找一个函数,能把「任意实数」映射成「S 形曲线」。
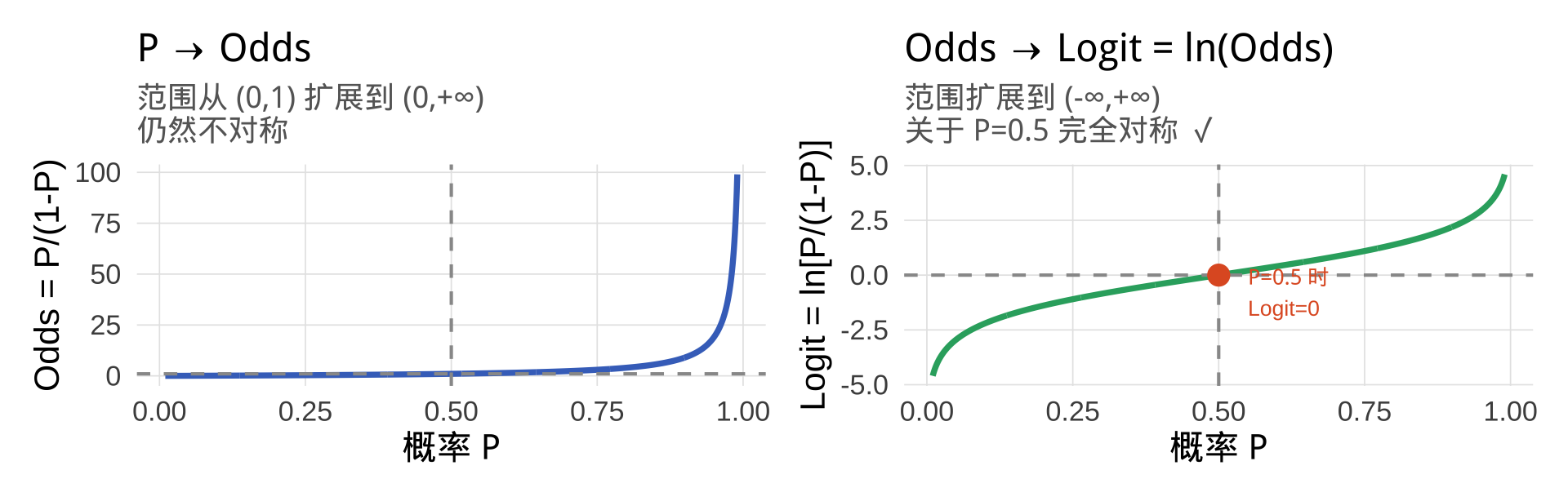
第二步:概率的困境
问题: 概率 \(P \in (0, 1)\),取值范围有限,无法直接作为线性模型的因变量。
\[P \in (0,\ 1) \quad \longrightarrow \quad \text{不能直接放进} \;\beta_0 + \beta_1 X\]
思路: 能否通过某种变换,把 \((0, 1)\) 上的 \(P\),变换成取值范围为 \((-\infty, +\infty)\) 的新变量?
分两步走:
\[\underbrace{P}_{\in\,(0,\,1)} \xrightarrow{\text{第一步}} \underbrace{\dfrac{P}{1-P}}_{\in\,(0,\,+\infty)} \xrightarrow{\text{第二步}} \underbrace{\ln\!\left(\dfrac{P}{1-P}\right)}_{\in\,(-\infty,\,+\infty)}\]
第三步:优势比/胜率(Odds)
优势比(Odds):事件发生的概率 vs 不发生的概率之比
\[\text{Odds} = \frac{P}{1 - P}\]
直觉举例:
| 录取概率 \(P\) | 不录取概率 \(1-P\) | Odds | 解读 |
|---|---|---|---|
| 0.25 | 0.75 | 0.33 | 录取可能性是不录取的 0.33 倍 |
| 0.50 | 0.50 | 1.00 | 录取与不录取可能性相同 |
| 0.75 | 0.25 | 3.00 | 录取可能性是不录取的 3 倍 |
| 0.90 | 0.10 | 9.00 | 录取可能性是不录取的 9 倍 |
注记
Odds 把 \((0, 1)\) 扩展到了 \((0, +\infty)\),但仍然不对称——还需要再做一次变换。
第四步:对数优势比(Logit)
对 Odds 取自然对数,得到 Logit(对数优势比):
\[\text{logit}(P) = \ln\!\left(\frac{P}{1 - P}\right)\]
第五步:建立线性模型
经过两次变换,Logit 的取值范围终于是 \((-\infty, +\infty)\),可以放进线性模型!
\[\ln\!\left(\frac{P}{1-P}\right) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_k X_k\]
这就是逻辑回归模型(Logit 模型)的完整形式。
提示
逻辑回归不是对概率建线性模型,而是对概率的 Logit 变换建线性模型。
右边是普通的线性组合;左边不是 \(P\),而是 \(\ln[P/(1-P)]\)。
等等——我们最终想要的是概率 \(P\),不是 Logit。如何从 Logit 反推回概率?
第六步:从 Logit 反推概率(Sigmoid 函数)
设 \(\eta = \beta_0 + \beta_1 X_1 + \cdots + \beta_k X_k\),逐步求解:
\[\ln\!\left(\frac{P}{1-P}\right) = \eta\]
两边取指数:
\[\frac{P}{1-P} = e^\eta\]
整理:
\[P = \frac{e^\eta}{1 + e^\eta} = \frac{1}{1 + e^{-\eta}}\]
提示
这就是 Sigmoid 函数(也叫逻辑函数):
\[P = \sigma(\eta) = \frac{1}{1 + e^{-\eta}}\]
无论 \(\eta\) 取什么实数值,\(P\) 永远在 \((0, 1)\) 内——这正是我们想要的。
完整推导路线图
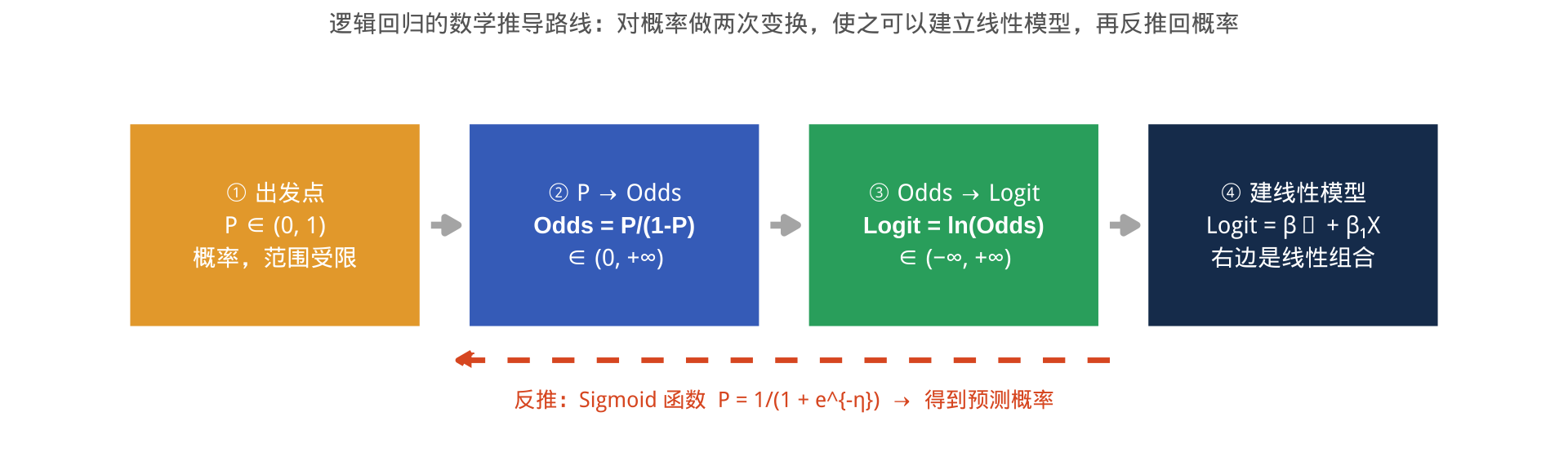
总结一句话: 逻辑回归在 Logit 尺度上是线性的;在概率尺度上是 S 形的。两种尺度之间通过 Sigmoid / Logit 互相转换。
为什么是 S 形?
Part 3:系数如何解读
不是概率变化,而是优势比
系数的直接含义
逻辑回归模型:
\[\ln\!\left(\frac{P}{1-P}\right) = \beta_0 + \beta_1 X\]
当 \(X\) 增加 1 个单位(\(X \to X+1\)):
\[\ln\!\left(\frac{P'}{1-P'}\right) = \beta_0 + \beta_1 (X+1)\]
两式相减:
\[\ln\!\left(\frac{P'}{1-P'}\right) - \ln\!\left(\frac{P}{1-P}\right) = \beta_1\]
即:
\[\ln\!\left(\frac{\text{Odds}'}{\text{Odds}}\right) = \beta_1 \quad \Longrightarrow \quad \frac{\text{Odds}'}{\text{Odds}} = e^{\beta_1}\]
优势比(Odds Ratio, OR)
提示
逻辑回归系数的标准解读:
\(X_j\) 增加 1 个单位,优势比(Odds Ratio)变为原来的 \(e^{\hat\beta_j}\) 倍
等价说法:对数优势比变化了 \(\hat\beta_j\)。
| \(\hat\beta_j\) | \(e^{\hat\beta_j}\) | 解读 |
|---|---|---|
| \(> 0\) | \(> 1\) | \(X_j\) 增加,事件发生风险升高 |
| \(= 0\) | \(= 1\) | \(X_j\) 与事件无关 |
| \(< 0\) | \(< 1\) | \(X_j\) 增加,事件发生风险降低 |
警告
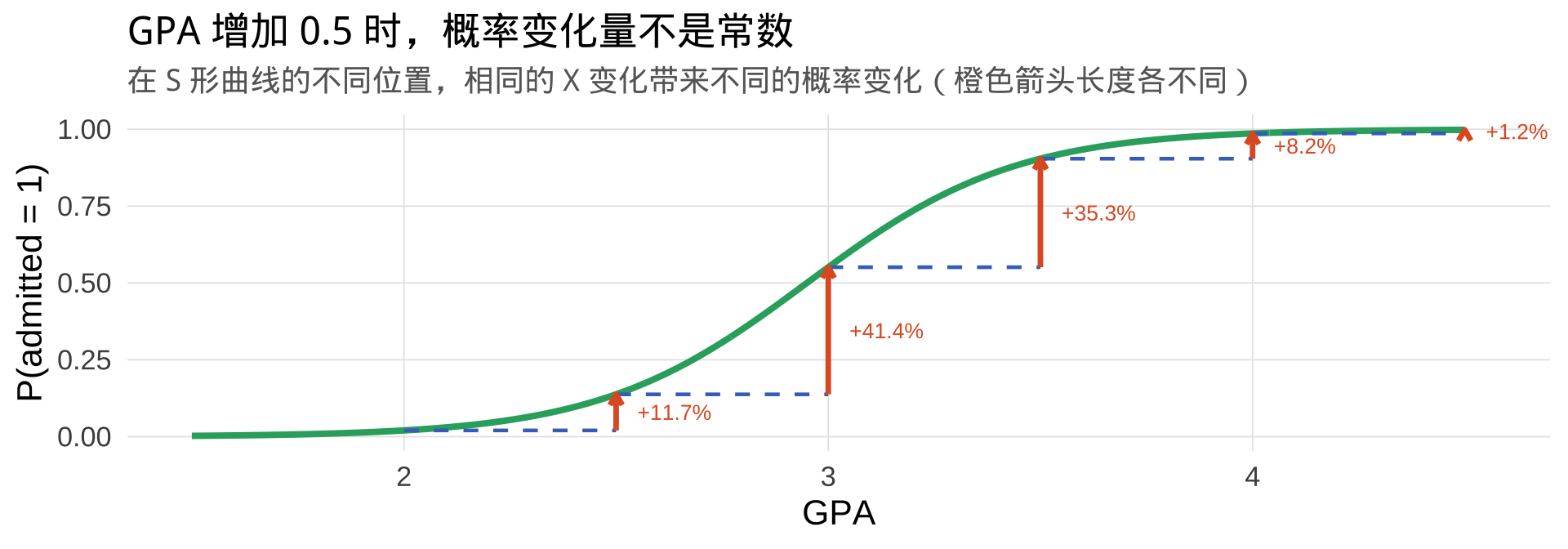
常见错误: 把系数解读为「\(X\) 增加 1,概率增加 \(\hat\beta\)」——这是错的。
概率的变化量是非线性的,取决于当前 \(X\) 的值。系数只对 Logit(对数优势比) 有线性解释。
为什么不能直接说「概率增加多少」?
注记
结论: Logit 系数是常数,但它对应的概率变化量因位置而异。这正是 Logit 模型设计的核心——在 Logit 尺度上保持线性,不在概率尺度上。
Part 4:R 实操演示
录取数据完整流程
步骤一:读入数据
'data.frame': 2100 obs. of 2 variables:
$ gpa : num 2.3 3 2.5 2.9 3.7 3.6 3.2 3.4 2.1 2.3 ...
$ admitted: int 0 1 0 1 1 1 1 1 0 0 ...步骤二:清洗数据
| Unique | Missing Pct. | Mean | SD | Min | Median | Max | Histogram | |
|---|---|---|---|---|---|---|---|---|
| gpa | 21 | 0 | 3.0 | 0.6 | 2.0 | 3.0 | 4.0 |  |
| admitted | 2 | 0 | 0.5 | 0.5 | 0.0 | 1.0 | 1.0 |  |
步骤三:拆分训练集与测试集
▶️ 查看代码
Rows: 1,680
Columns: 2
$ gpa <dbl> 3.1, 2.7, 4.0, 2.6, 3.1, 3.5, 2.8, 3.6, 4.0, 2.1, 4.0, 2.7, 2…
$ admitted <int> 0, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0…Rows: 420
Columns: 2
$ gpa <dbl> 2.5, 3.7, 3.9, 2.8, 2.2, 2.3, 2.9, 2.9, 2.3, 3.4, 2.6, 2.2, 3…
$ admitted <int> 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 1…步骤四:训练逻辑回归模型
▶️ 查看代码
Call:
glm(formula = admitted ~ gpa, family = binomial, data = train)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -11.738 0.537 -21.8 <2e-16 ***
gpa 3.992 0.181 22.1 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 2322.8 on 1679 degrees of freedom
Residual deviance: 1254.1 on 1678 degrees of freedom
AIC: 1258
Number of Fisher Scoring iterations: 5解读输出
回归概率
步骤五:在测试集上预测
▶️ 查看代码
1 2 3 4 5 6 7 8 9 10
0.14686 0.95393 0.97873 0.36310 0.04941 0.07191 0.45939 0.45939 0.07191 0.86212 步骤六:验证——混淆矩阵
预测值
真实值 0 1
0 180 32
1 25 183| 预测:未录取(0) | 预测:录取(1) | |
|---|---|---|
| 实际:未录取(0) | TN = 180 ✅ | FP = 32 ❌ |
| 实际:录取(1) | FN = 25 ❌ | TP = 183 ✅ |
步骤七:用 caret 包做完整评估
▶️ 查看代码
Confusion Matrix and Statistics
Reference
Prediction 0 1
0 180 25
1 32 183
Accuracy : 0.864
95% CI : (0.828, 0.896)
No Information Rate : 0.505
P-Value [Acc > NIR] : <2e-16
Kappa : 0.729
Mcnemar's Test P-Value : 0.427
Sensitivity : 0.880
Specificity : 0.849
Pos Pred Value : 0.851
Neg Pred Value : 0.878
Prevalence : 0.495
Detection Rate : 0.436
Detection Prevalence : 0.512
Balanced Accuracy : 0.864
'Positive' Class : 1
指标说明
-
Sensitivity (灵敏度 / 真阳性率/ 召回率)
含义: 在所有实际为 Yes 的样本中,模型正确预测出 Yes 的比例。
解读: 模型对正例的抓取能力很强,88% 的流失用户都被你找出来了。
-
Specificity (特异度 / 真阴性率): 0.849
含义: 在所有实际为 No 的样本中,模型正确预测出 No 的比例。
解读: 模型排除干扰的能力不错,84.9% 的被拒学生没有被误判。
-
Pos Pred Value (阳性预测值 / 精确率/ Precision): 0.851
含义: 在模型预测为 Yes 的所有样本中,真正是 Yes 的比例。
解读: 当模型告诉你这个人会录取时,他真的录取的概率是 85.1%。
-
Neg Pred Value (阴性预测值): 0.878
含义: 在模型预测为 No 的所有样本中,真正是 No 的比例。
解读: 当模型说这个人不会录取时,他确实被拒的概率是 87.8%。
-
Prevalence (患病率 / 流行率): 0.495
含义: 样本集中实际为 Yes 的样本占总样本的比例。
解读: 数据非常平衡(约 49.5% 是正例),这对于训练模型是非常理想的状态。
-
Detection Rate (检测率): 0.436
- 含义: 真正例(True Positives)占总样本的比例。
-
Detection Prevalence (检测流行率): 0.512
- 含义: 模型预测为 Yes 的样本占总样本的比例。
Balanced Accuracy (平衡准确率): 0.864计算:
\[(Sensitivity + Specificity) / 2\]
- 含义: 它是灵敏度和特异度的平均值。
- 解读: 当数据分布不均时,常规准确率(Accuracy)会失效,而平衡准确率能更客观地反映模型在两类表现上的平均水平。0.864 是一个相当优秀的得分。
完整流程回顾
Part 5:你必须掌握什么?
学习路线图与常见错误
必须掌握
重要
以下内容是本讲核心,下次课前务必消化:
为什么不用线性回归:预测值超出 \([0,1]\);残差不正态;天然异方差——三个根本性缺陷
三步变换的逻辑:\(P \xrightarrow{\div(1-P)} \text{Odds} \xrightarrow{\ln} \text{Logit} \xrightarrow{=\beta_0+\beta_1 X} \text{线性模型}\);反推用 Sigmoid
系数解读:\(\hat\beta_j\) 是 \(X_j\) 增加 1 时对数优势比的变化;\(e^{\hat\beta_j}\) 是优势比(OR);OR > 1 风险升高,OR < 1 风险降低
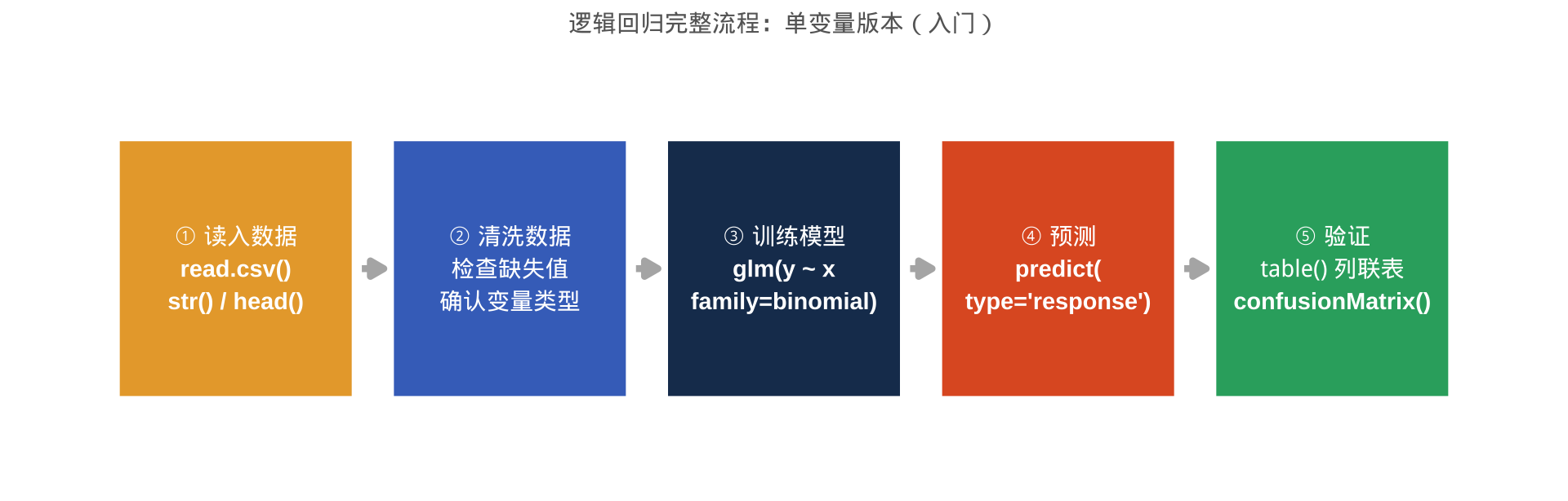
R 操作五步:
read.csv()→ 清洗 →glm(family=binomial)→predict(type="response")→confusionMatrix()截断处理:
ifelse(pred_prob > 0.5, 1, 0);0.5 是默认值,不是唯一正确答案
理解即可
注记
以下内容理解含义即可:
最大似然估计(MLE):逻辑回归的参数估计方法;直觉是「找到使现有数据出现概率最大的参数」;R 自动完成
Wald 检验:
summary()中的z value和Pr(>|z|)就是对每个系数的显著性检验;含义与线性回归的 \(t\) 检验类似为什么截断点不一定是 0.5:在医疗诊断中,「漏诊」的代价远大于「误诊」,可能需要把截断点降低到 0.3——下讲详细讨论
常见错误
警告
请对照检查:
| 错误 | 正确做法 |
|---|---|
| 把系数说成「概率变化」 | 系数是对数优势比变化;说概率变化必须通过 Sigmoid 函数计算 |
忘记写 family = binomial
|
不写则变成线性回归,对二值 \(Y\) 完全错误 |
用 type = "link" 要概率 |
默认输出 Logit(对数优势比);要概率必须 type = "response"
|
confusionMatrix() 不指定 positive
|
不指定则以字母序第一个为正类,结果可能解读颠倒 |
本讲小结
问题:二值因变量不能用线性回归——预测值超出范围、残差假设不成立
解决:对概率做两次变换(→ Odds → Logit),使之变成 \((-\infty, +\infty)\) 上的线性模型;用 Sigmoid 反推回概率
模型:\(\ln[P/(1-P)] = \beta_0 + \beta_1 X\);系数解读为对数优势比变化;\(e^{\hat\beta}\) 为优势比
R 流程:
glm(y ~ x, family = binomial)→predict(type = "response")→ifelse(p > 0.5, 1, 0)→confusionMatrix()
课后练习
基础练习(必做)
使用 wooldridge 包中的 mroz 数据集(已婚女性劳动参与调查):
因变量: inlf(是否参与劳动力市场,1 = 参与,0 = 不参与)
自变量(选这两个):
-
nwifeinc:家庭非劳动收入(连续型,单位:千美元)——连续型自变量 -
kidslt6:6 岁以下子女数量,取值为 0/1/2/3 等整数,用factor()转换——分类型自变量
按以下步骤完成:
读入数据,用
str()查看数据结构,用table(mroz$inlf)查看因变量分布清洗数据:确认无缺失值;将
kidslt6用factor()转换为因子型(0为参照组)按 8:2 拆分训练集与测试集(
set.seed(42)),建立全变量逻辑回归,查看summary()在测试集上预测概率,以 0.5 截断,输出预测值
用
table()查看混淆矩阵;用caret::confusionMatrix()计算准确率和灵敏度
思考题
下讲预告
第13讲(下):逻辑回归——多变量建模与变量筛选
- 加入多个自变量(连续型 + 分类型)
- 使用
step()进行逐步回归筛选变量 - 用客户流失数据(C50 包)完整演练
提示
今天掌握了逻辑回归的原理和单变量流程;下讲在此基础上加入多个自变量,并学习如何用 AIC 自动筛选出最重要的变量。
谢谢!
第13讲(上):逻辑回归原理与初步实操
「所有模型都是错的,但有些是有用的。」
—— 乔治·博克斯(George Box)
数据挖掘与R语言 | 第13讲:逻辑回归原理