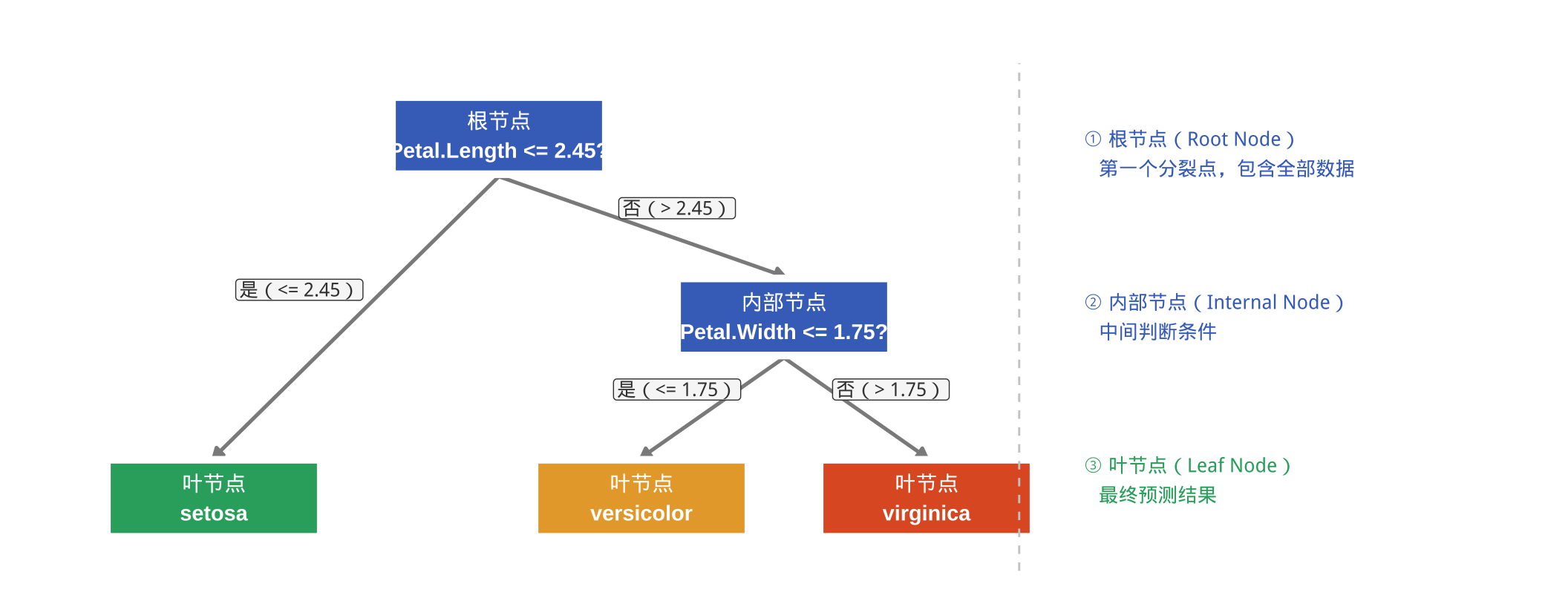
数据挖掘与R语言
第15讲:决策树与回归树——分类决策树
2026年05月20日
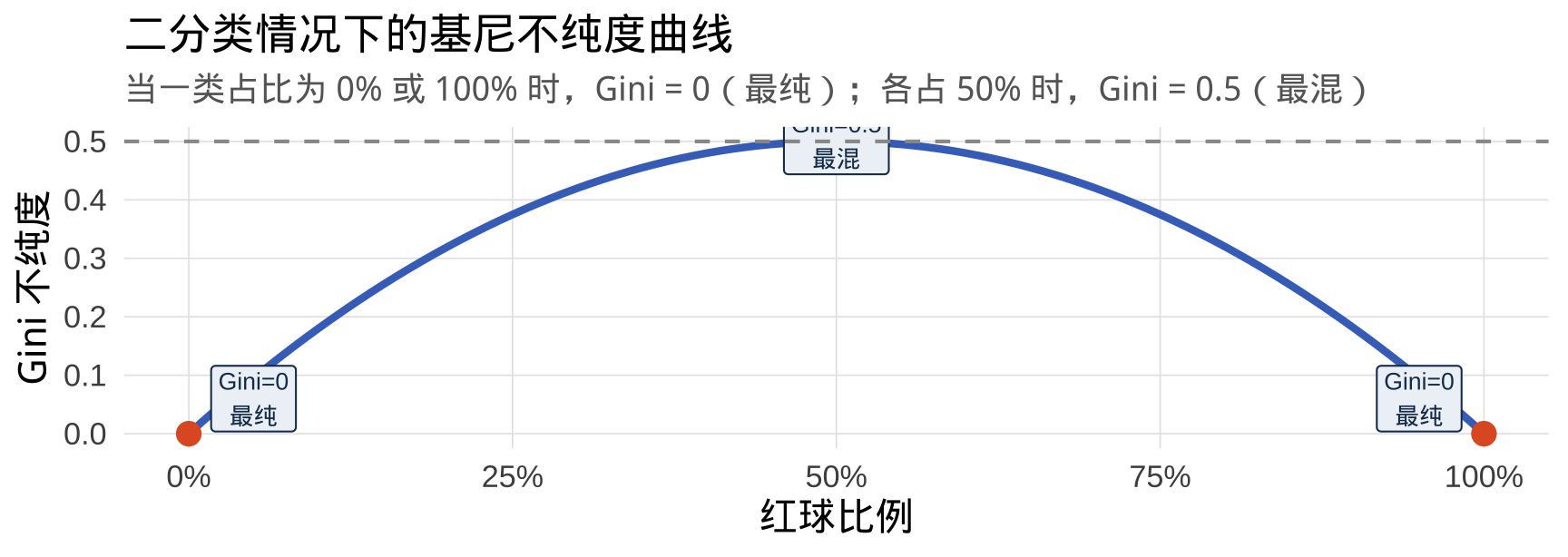
Gini 值的范围与含义
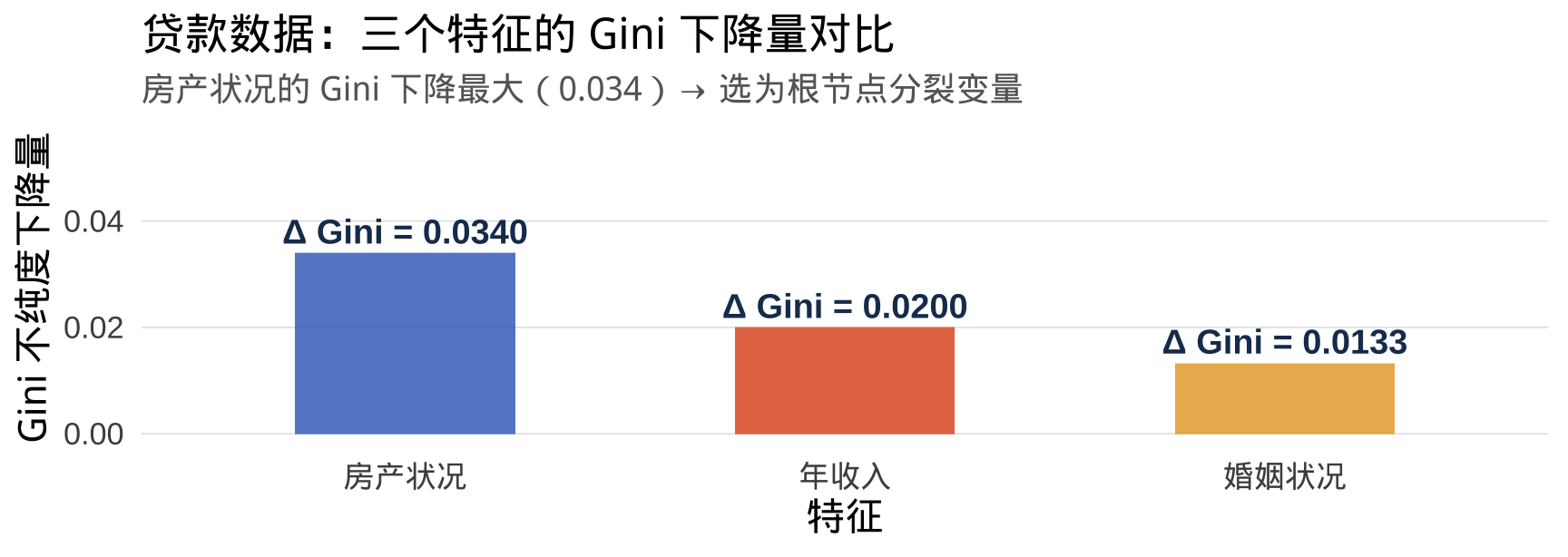
贷款数据:比较三个特征的分裂效果
提示
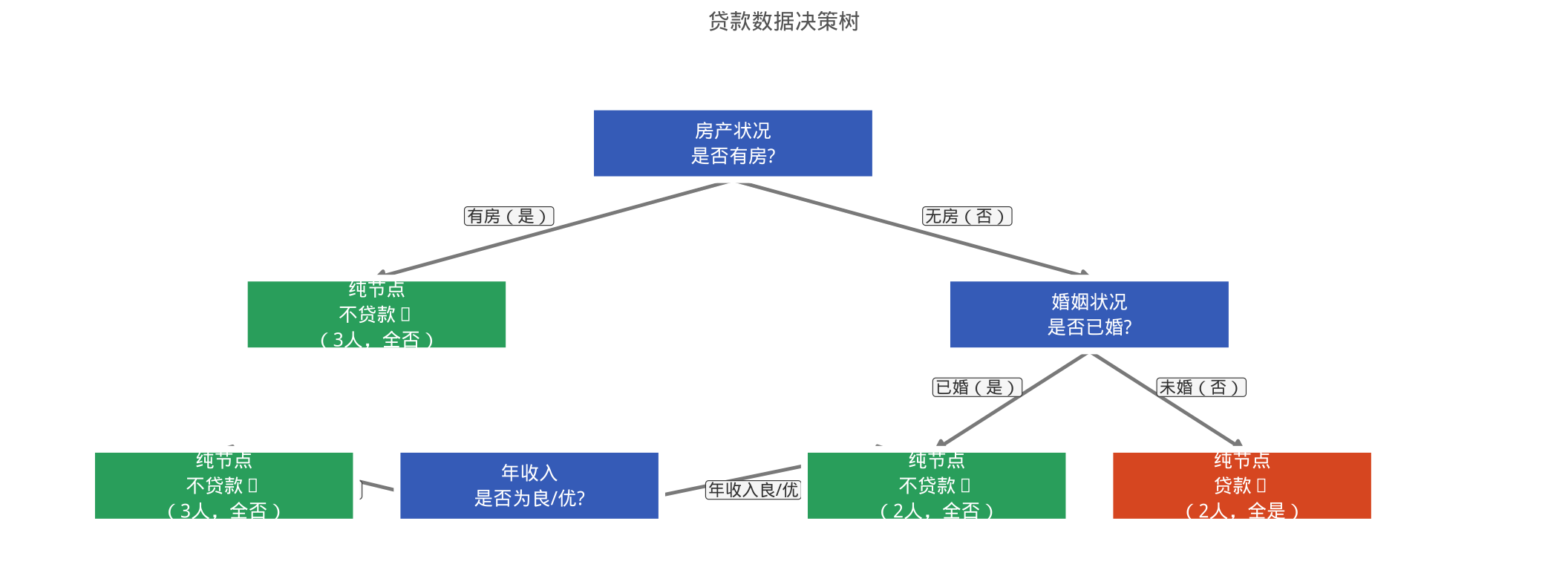
结论: 房产状况的 Gini 下降量最大(0.034),因此被选为根节点的分裂变量。有房产 → 全部拒绝贷款(Gini=0,纯节点);无房产 → 继续分裂。
贷款数据:决策树结构(教材示例)
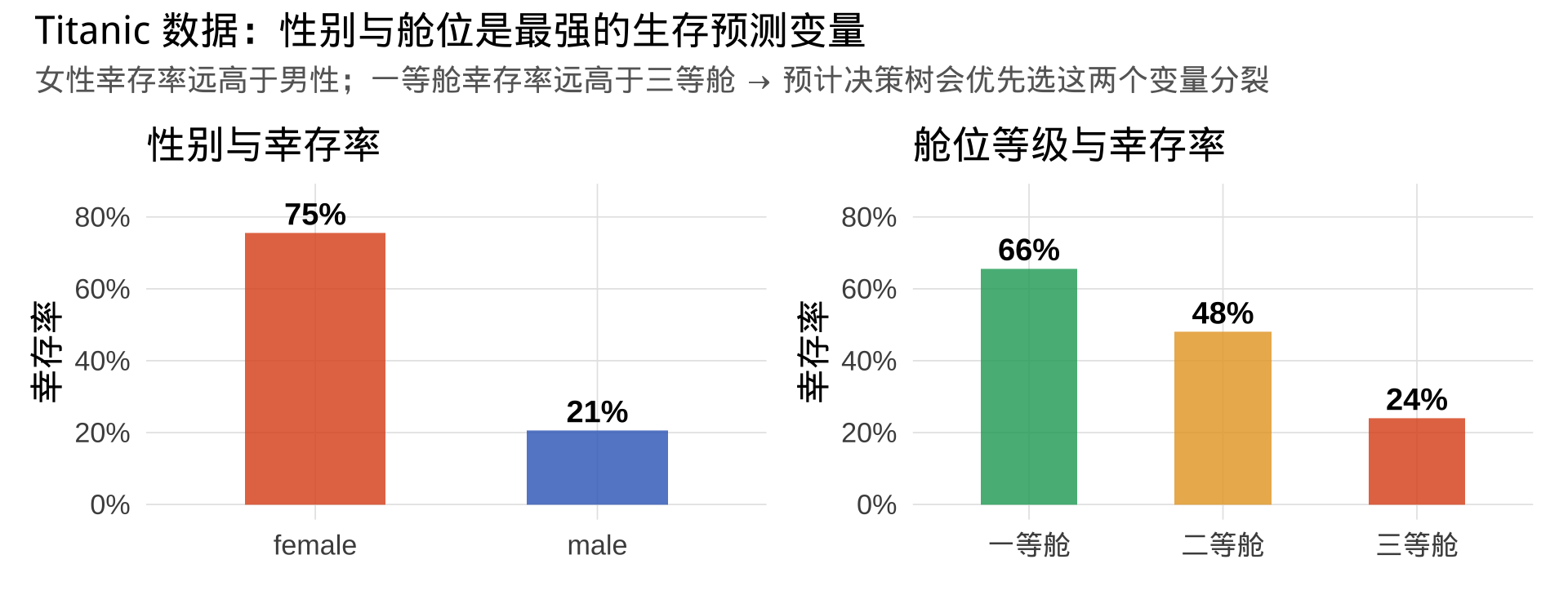
Titanic 数据可视化:谁更容易幸存?
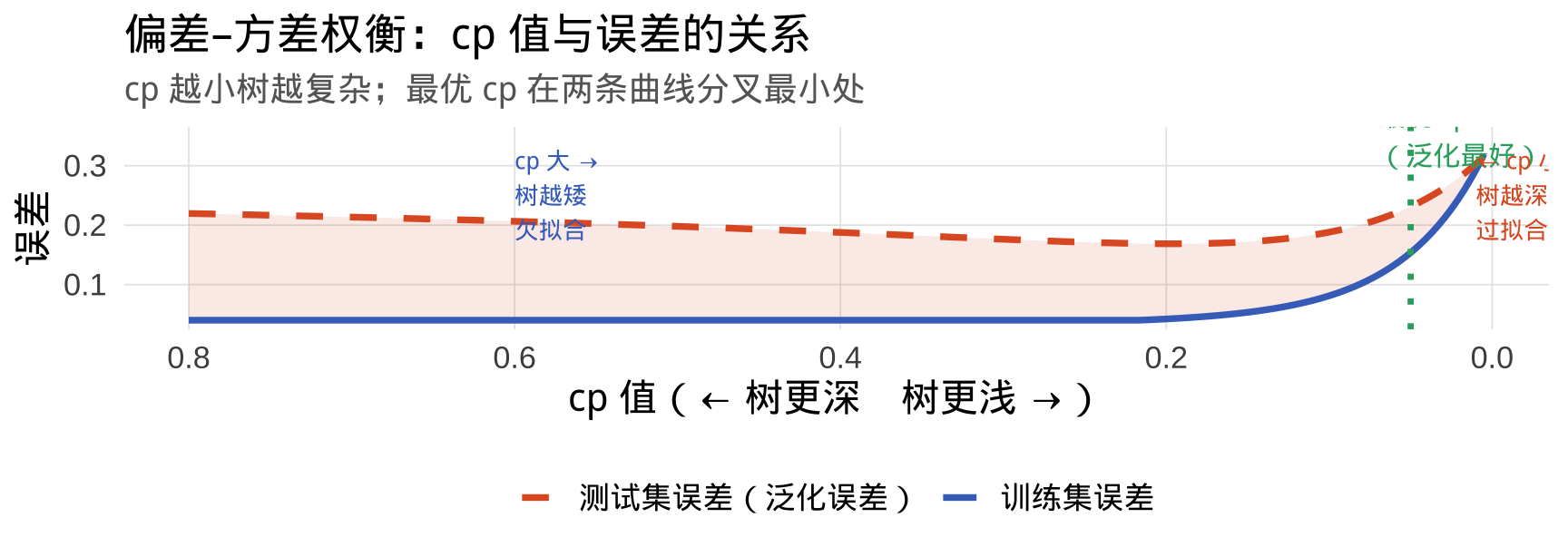
树太深会怎样?
数据概览
遇难 幸存
424 290
遇难 幸存
0.594 0.406 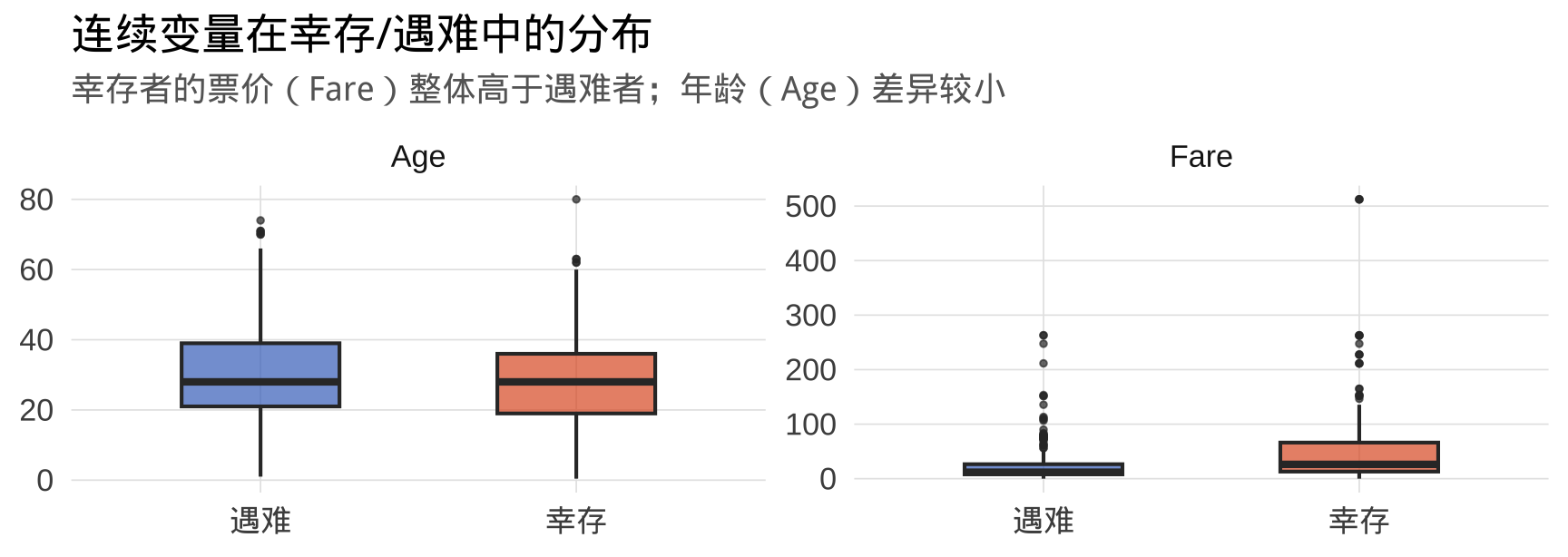
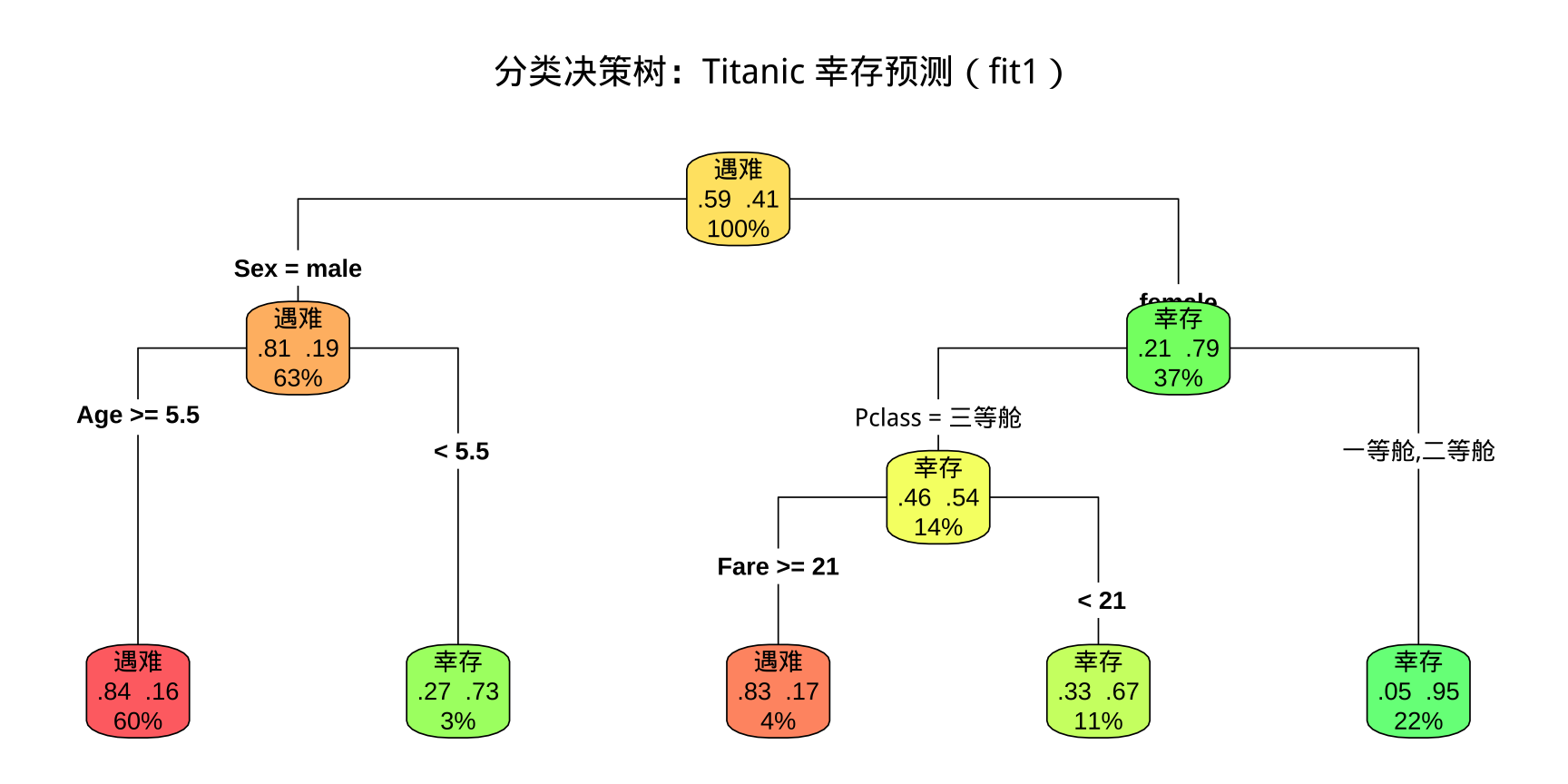
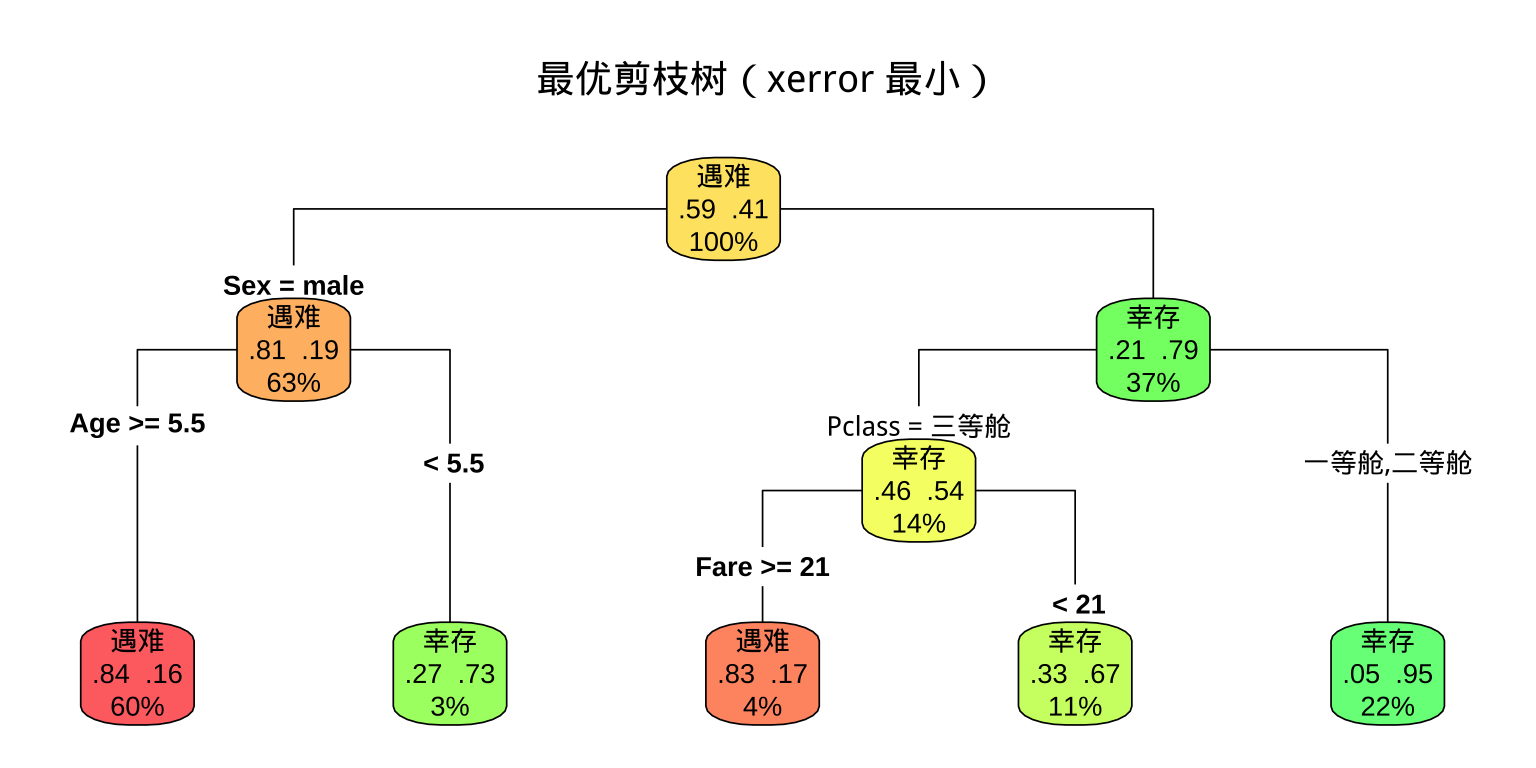
步骤四:决策树可视化
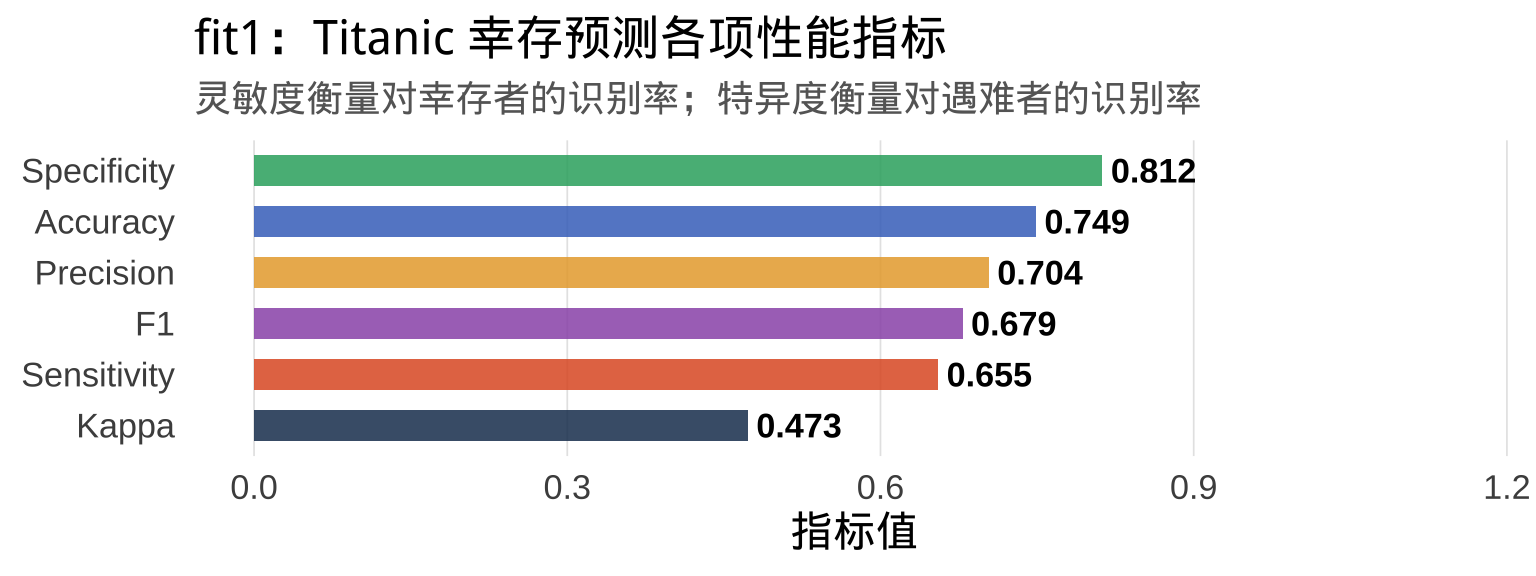
步骤六:混淆矩阵与准确性评估
Confusion Matrix and Statistics
Reference
Prediction 遇难 幸存
遇难 104 30
幸存 24 57
Accuracy : 0.749
95% CI : (0.685, 0.805)
No Information Rate : 0.595
P-Value [Acc > NIR] : 1.69e-06
Kappa : 0.473
Mcnemar's Test P-Value : 0.496
Sensitivity : 0.655
Specificity : 0.812
Pos Pred Value : 0.704
Neg Pred Value : 0.776
Prevalence : 0.405
Detection Rate : 0.265
Detection Prevalence : 0.377
Balanced Accuracy : 0.734
'Positive' Class : 幸存
注记
混淆矩阵读法: 行是真实结果,列是预测结果。对角线数字越大越好。召回率/灵敏度(Sensitivity) = 实际幸存中被正确预测的比例;特异度(Specificity) = 实际遇难中被正确预测的比例。
fit2 可视化
▶️ 查看代码
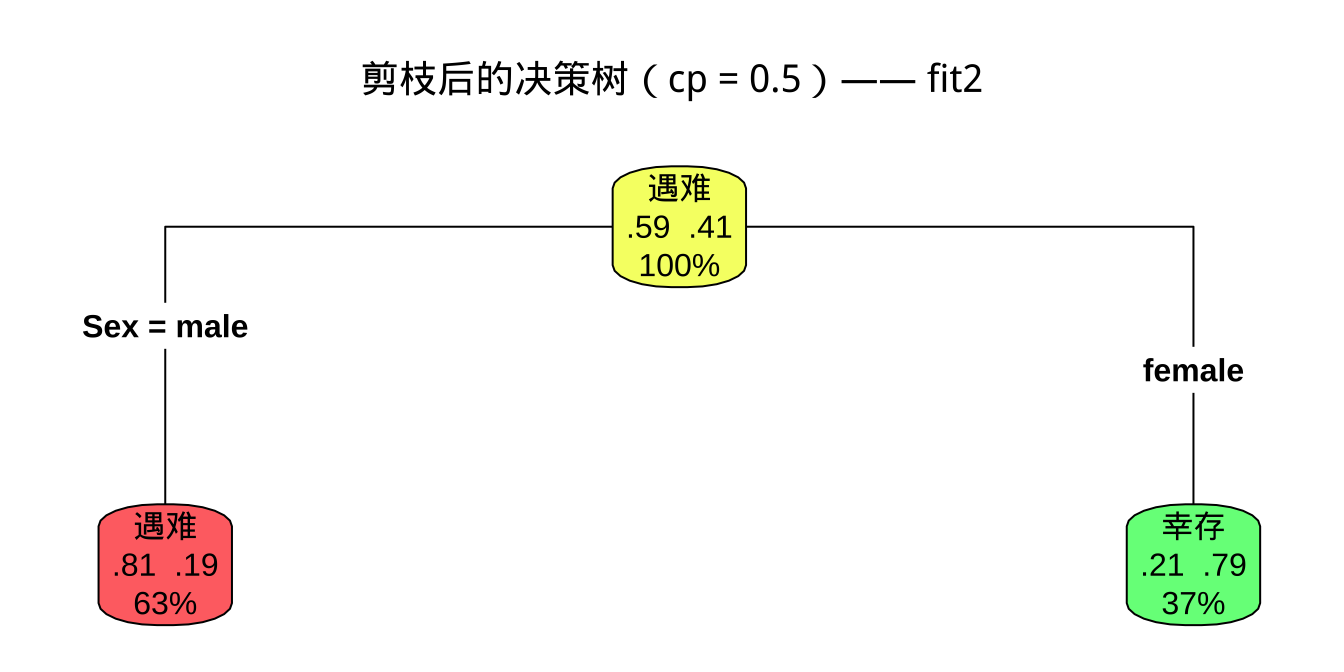
注记
fit2 只有一个分裂点:Sex。女性 → 幸存;男性 → 遇难。这与历史记录"妇女儿童优先"的救援原则吻合,但牺牲了对男性幸存者的识别能力。
两模型对比分析
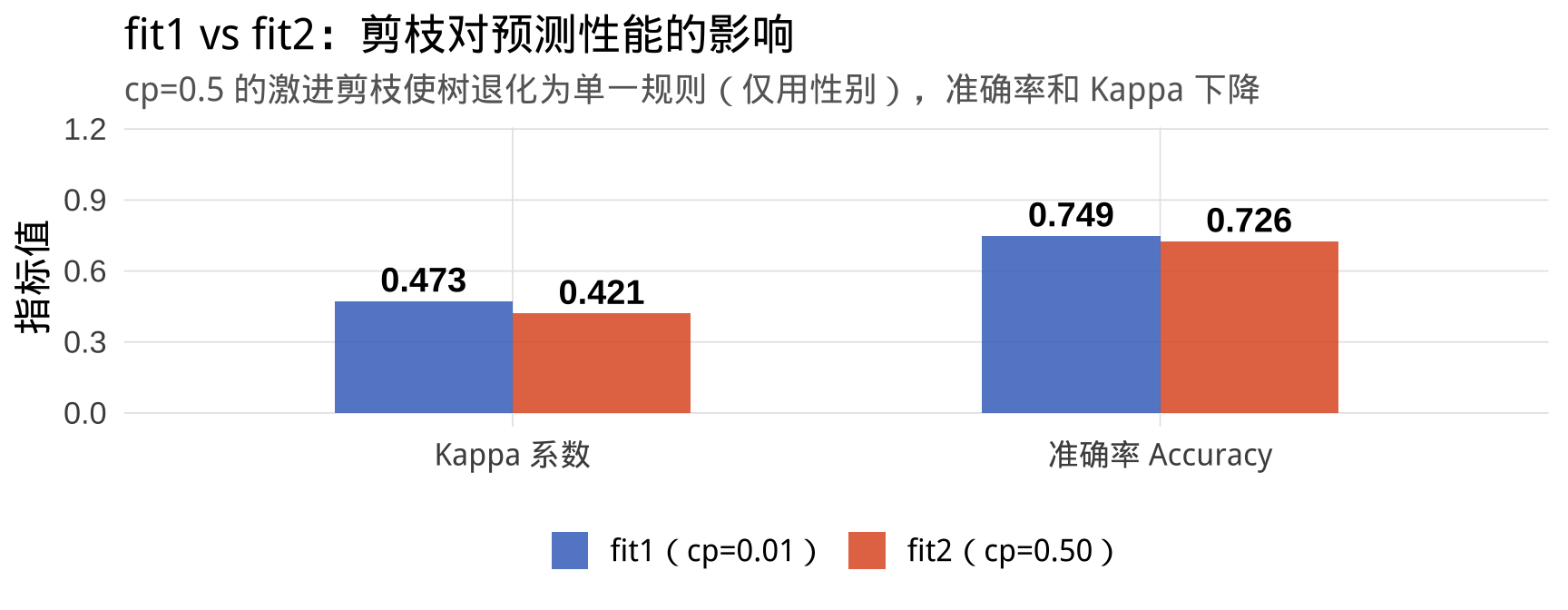
重要
结论: cp = 0.5 使树退化为仅用性别做判断(男→遇难,女→幸存),忽略了舱位、年龄等重要信息,准确率和 Kappa 均下降。实际应用中应用 printcp() 找最优 cp。
科学选择最优 cp
▶️ 查看代码
交叉验证误差最小的 cp: 0.01 ▶️ 查看代码
▶️ 查看代码
Confusion Matrix and Statistics
Reference
Prediction 遇难 幸存
遇难 104 30
幸存 24 57
Accuracy : 0.749
95% CI : (0.685, 0.805)
No Information Rate : 0.595
P-Value [Acc > NIR] : 1.69e-06
Kappa : 0.473
Mcnemar's Test P-Value : 0.496
Sensitivity : 0.655
Specificity : 0.812
Pos Pred Value : 0.704
Neg Pred Value : 0.776
Prevalence : 0.405
Detection Rate : 0.265
Detection Prevalence : 0.377
Balanced Accuracy : 0.734
'Positive' Class : 幸存
| (1) | (2) | (3) | |
|---|---|---|---|
| accuracy | 0.749 | 0.726 | 0.749 |
| kappa | 0.473 | 0.421 | 0.473 |
| sensitivity | 0.655 | 0.609 | 0.655 |
| specificity | 0.812 | 0.805 | 0.812 |
| pos_pred_value | 0.704 | 0.679 | 0.704 |
| neg_pred_value | 0.776 | 0.752 | 0.776 |
| precision | 0.704 | 0.679 | 0.704 |
| recall | 0.655 | 0.609 | 0.655 |
| f1 | 0.679 | 0.642 | 0.679 |
| prevalence | 0.405 | 0.405 | 0.405 |
| detection_rate | 0.265 | 0.247 | 0.265 |
| detection_prevalence | 0.377 | 0.363 | 0.377 |
| balanced_accuracy | 0.734 | 0.707 | 0.734 |
完整建模流程回顾

步骤 3:可视化并总结决策路径
▶️ 查看代码
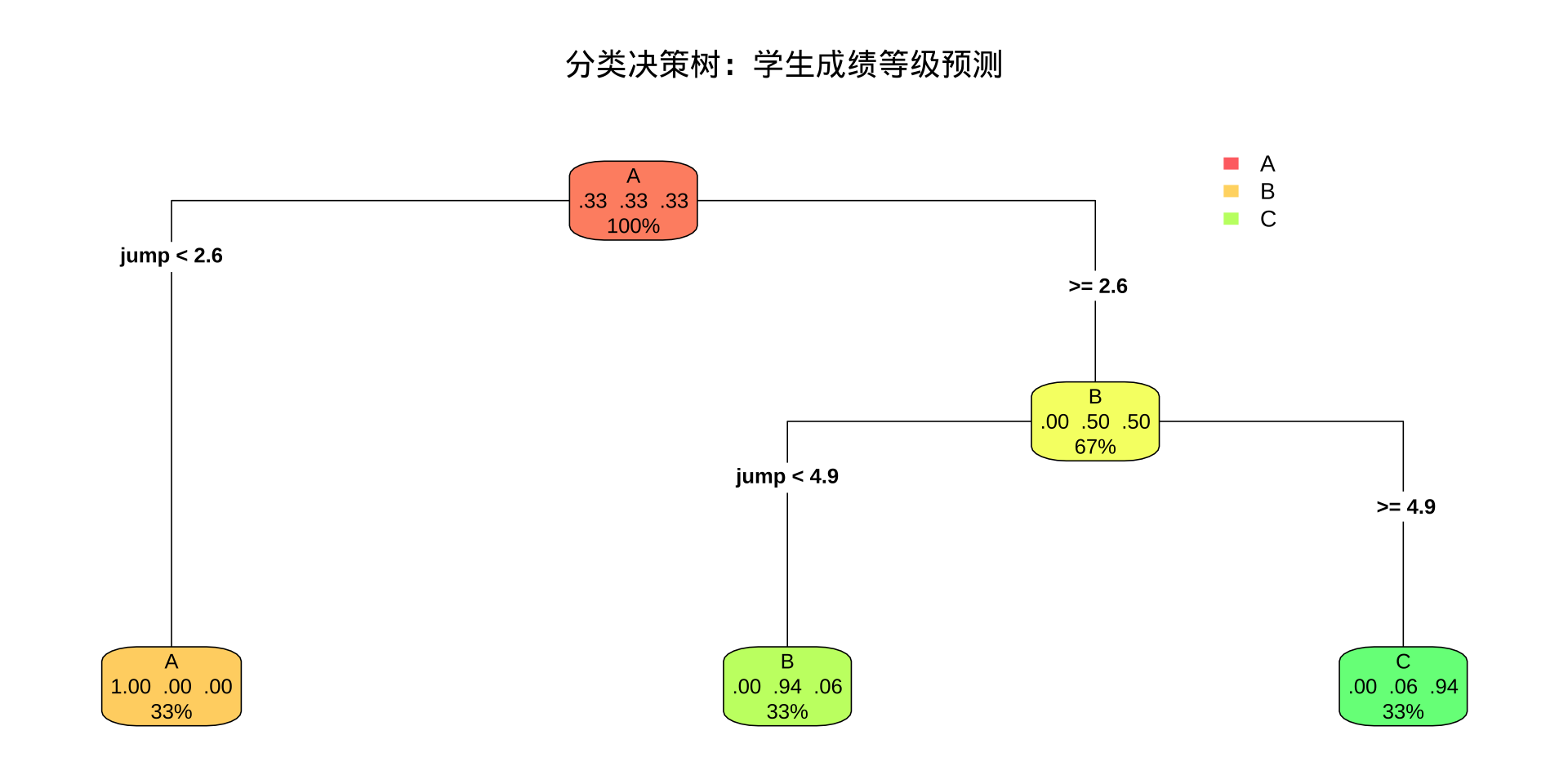
要求: 根据可视化结果,至少总结 一条 完整的决策路径(从根节点到叶节点),用文字描述"若……则预测等级为……"的规则,并说明该叶节点包含多少比例的训练样本。
步骤 5:剪枝建立 fit2
▶️ 查看代码
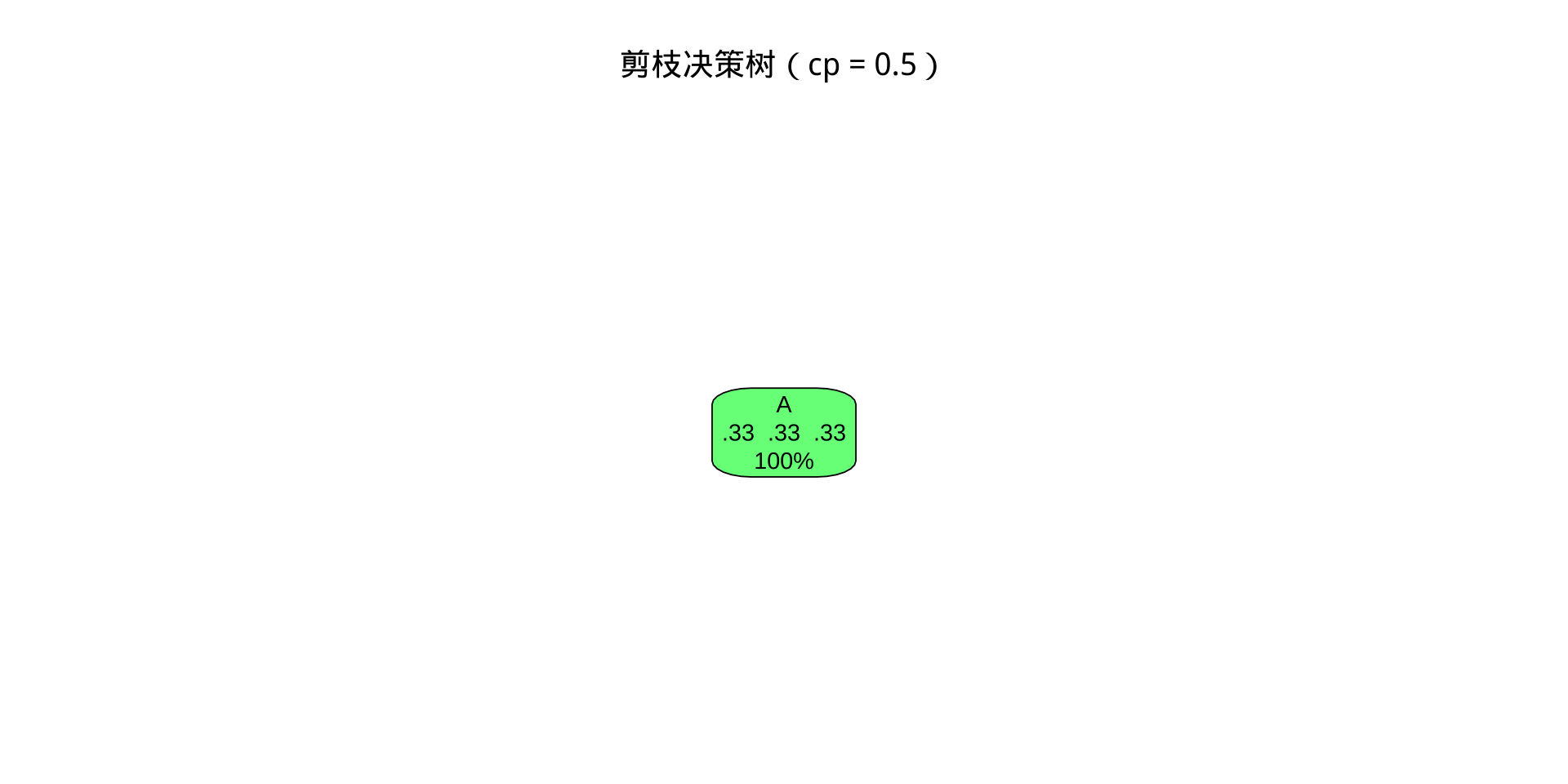
要求: 描述 fit2 的树形结构(有几个节点、几个叶节点);与 fit1 对比,说明 cp = 0.5 对树的形状产生了什么影响。