数据挖掘与R语言
第16讲:决策树与回归树——回归决策树
2026年05月22日
MSE 与基尼指数的对比
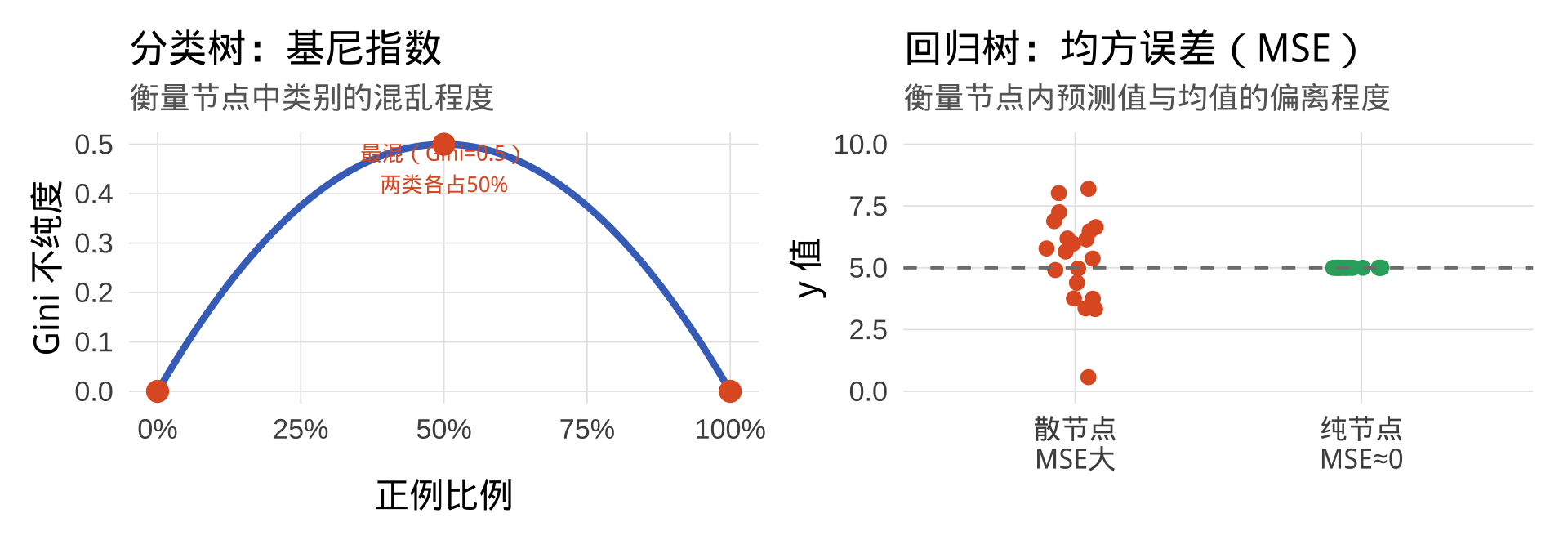
对比两种分裂方式
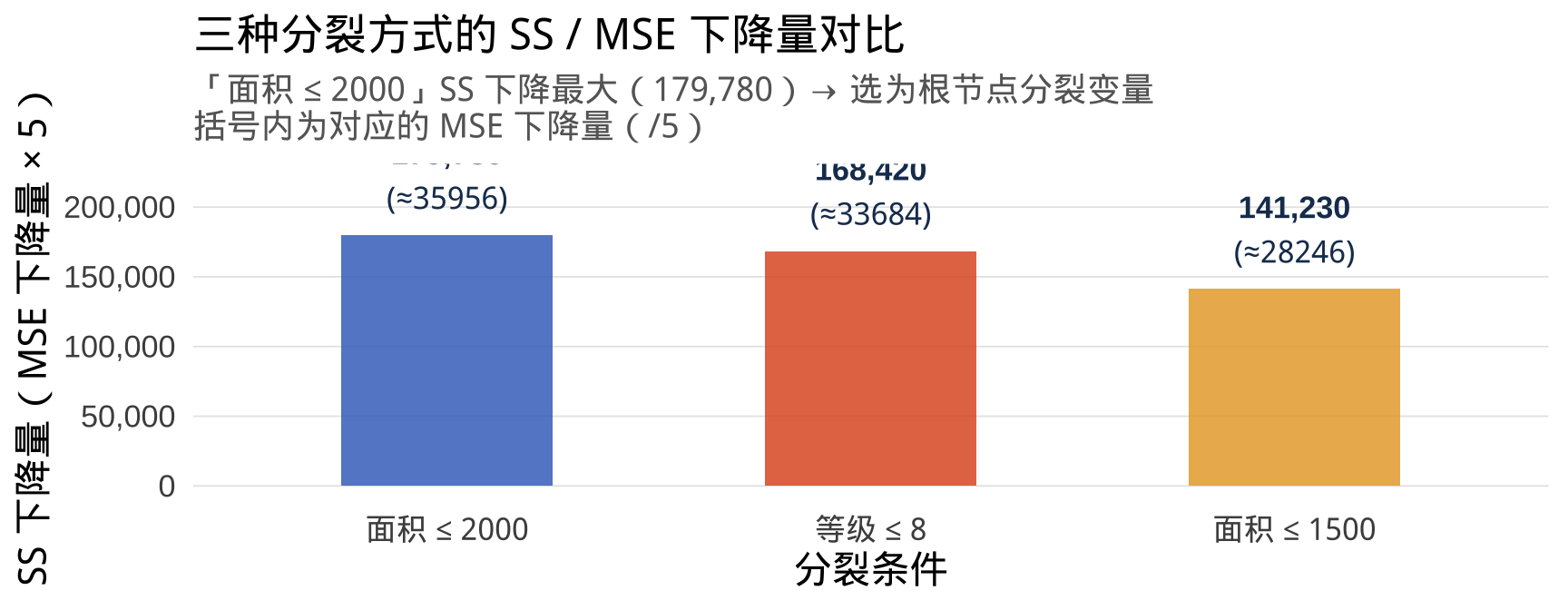
提示
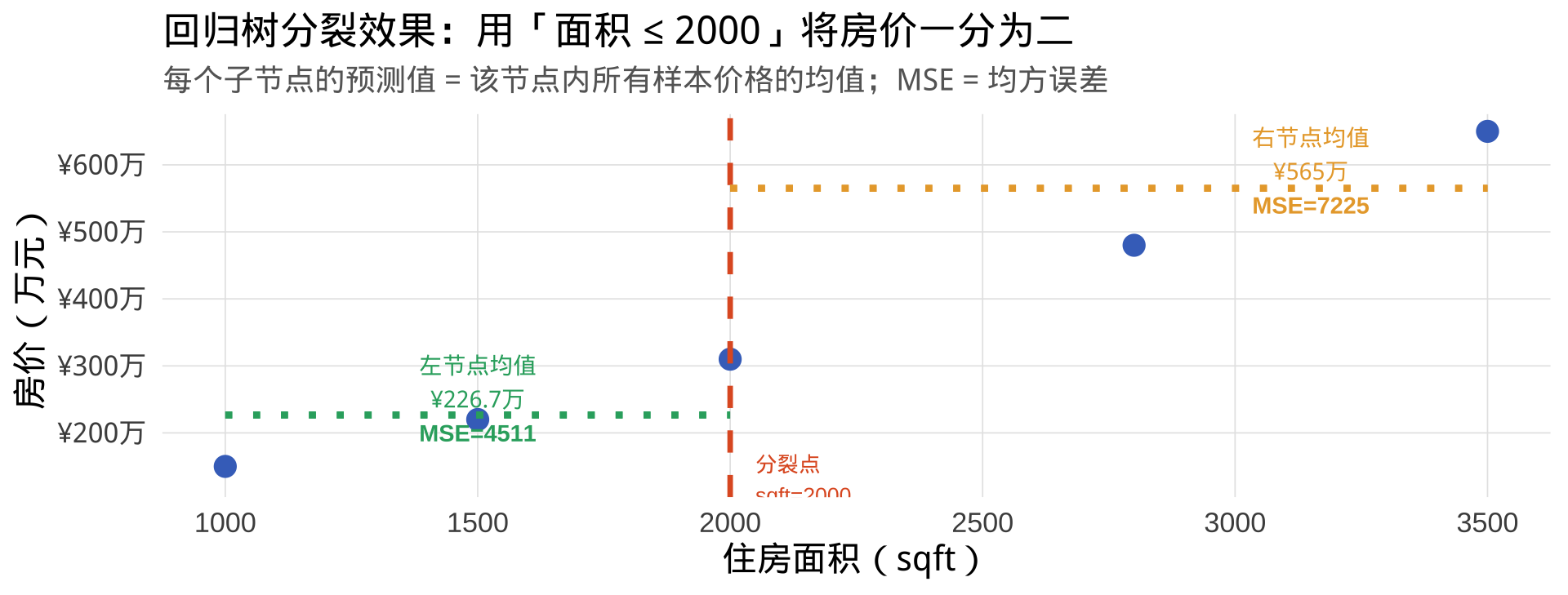
结论: "面积 ≤ 2000" 使 MSE 下降最大,因此被选为根节点的分裂变量。这与分类树选择"Gini 下降最大"的逻辑完全对应,只是评价指标换成了均方误差MSE。
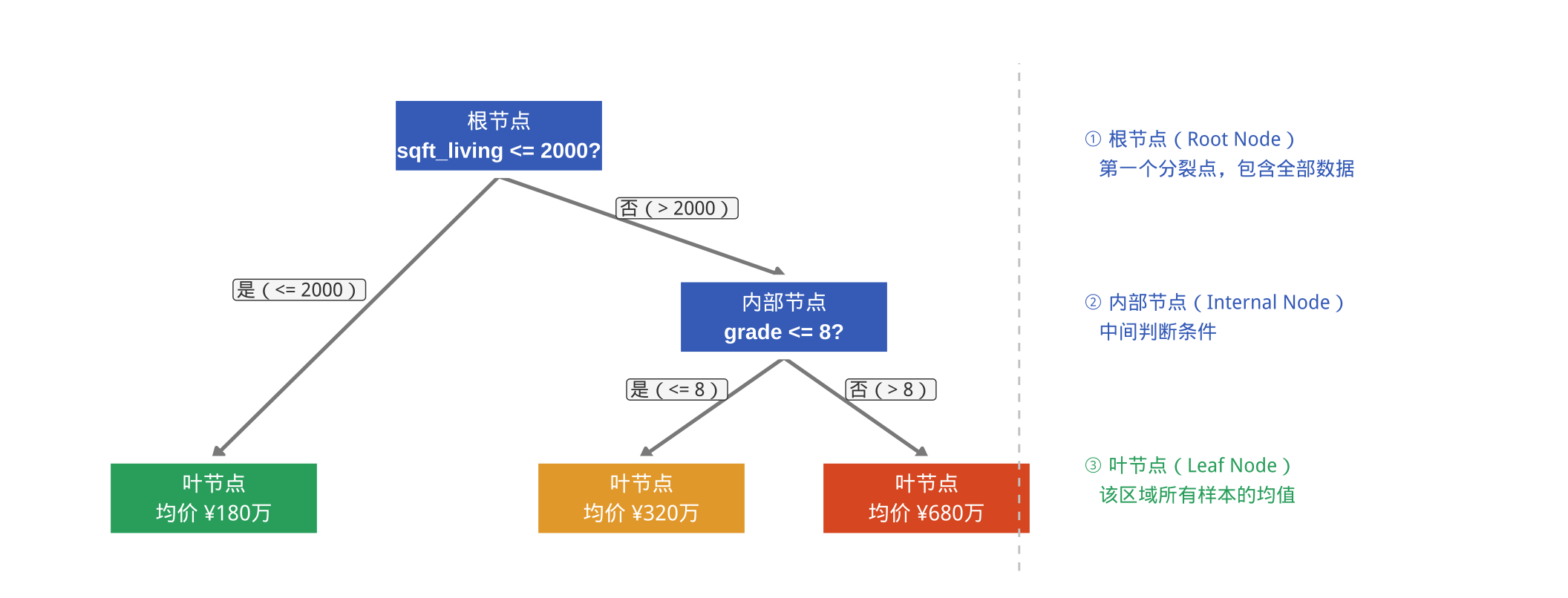
回归树的完整分裂逻辑
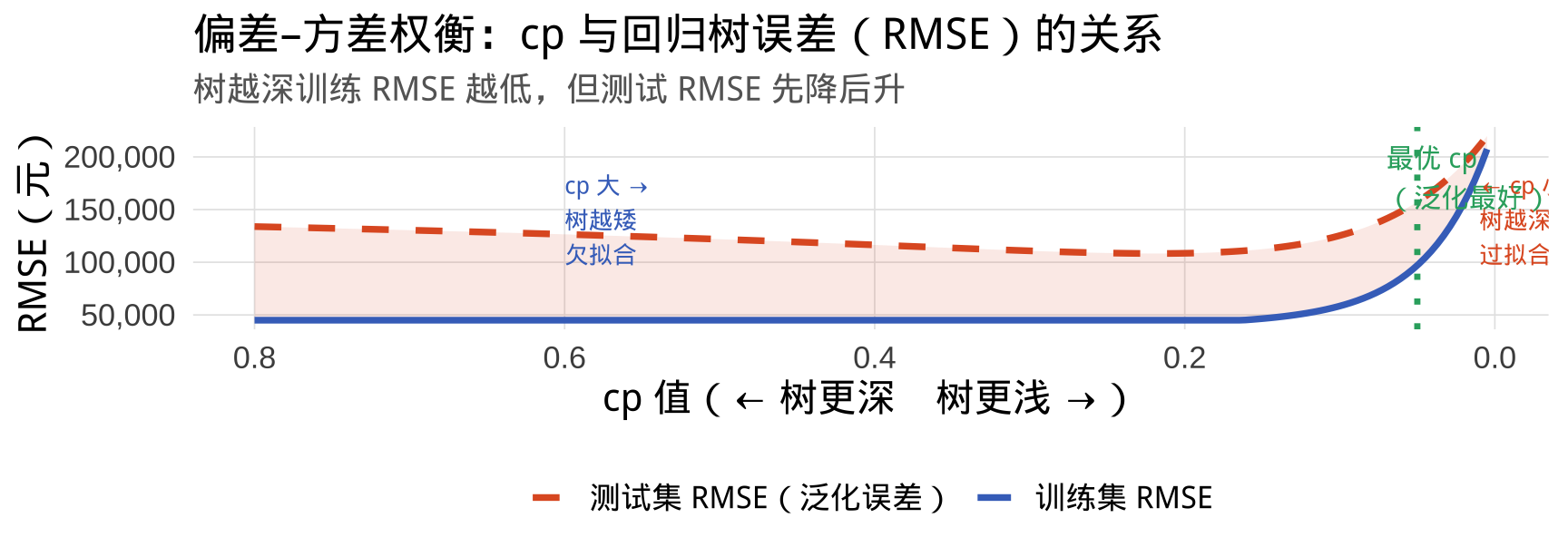
回归树的过拟合风险
训练集数据分析
▶️ 查看代码
# 方法一:将数据准备与绘图分离(推荐)
library(tidyverse)
# 准备数据
plot_data <- train_df %>%
select(medv, rm, lstat, crim) %>%
pivot_longer(-medv, names_to = "变量", values_to = "值")
# 绘图
p1 <- ggplot(train_df, aes(x = medv)) +
geom_histogram(bins = 40, fill = "#4472C4", alpha = 0.75, color = "white") +
labs(title = "Boston 房价分布(训练集)",
subtitle = "右偏分布:少数高价房拉高均值",
x = "房价中位数(千美元)", y = "频数")
p2 <- ggplot(plot_data, aes(x = 值, y = medv)) +
geom_point(alpha = 0.2, size = 0.8, color = "#4472C4") +
geom_smooth(method = "loess", se = FALSE, color = "#e05c2a", linewidth = 1) +
facet_wrap(~变量, scales = "free_x", nrow = 1) +
labs(title = "主要特征与房价的关系(训练集)",
subtitle = "rm(房间数)与房价正相关;lstat(低收入比例)与房价负相关",
x = NULL, y = "房价(千美元)")
p1 + p2 + plot_layout(widths = c(1, 2))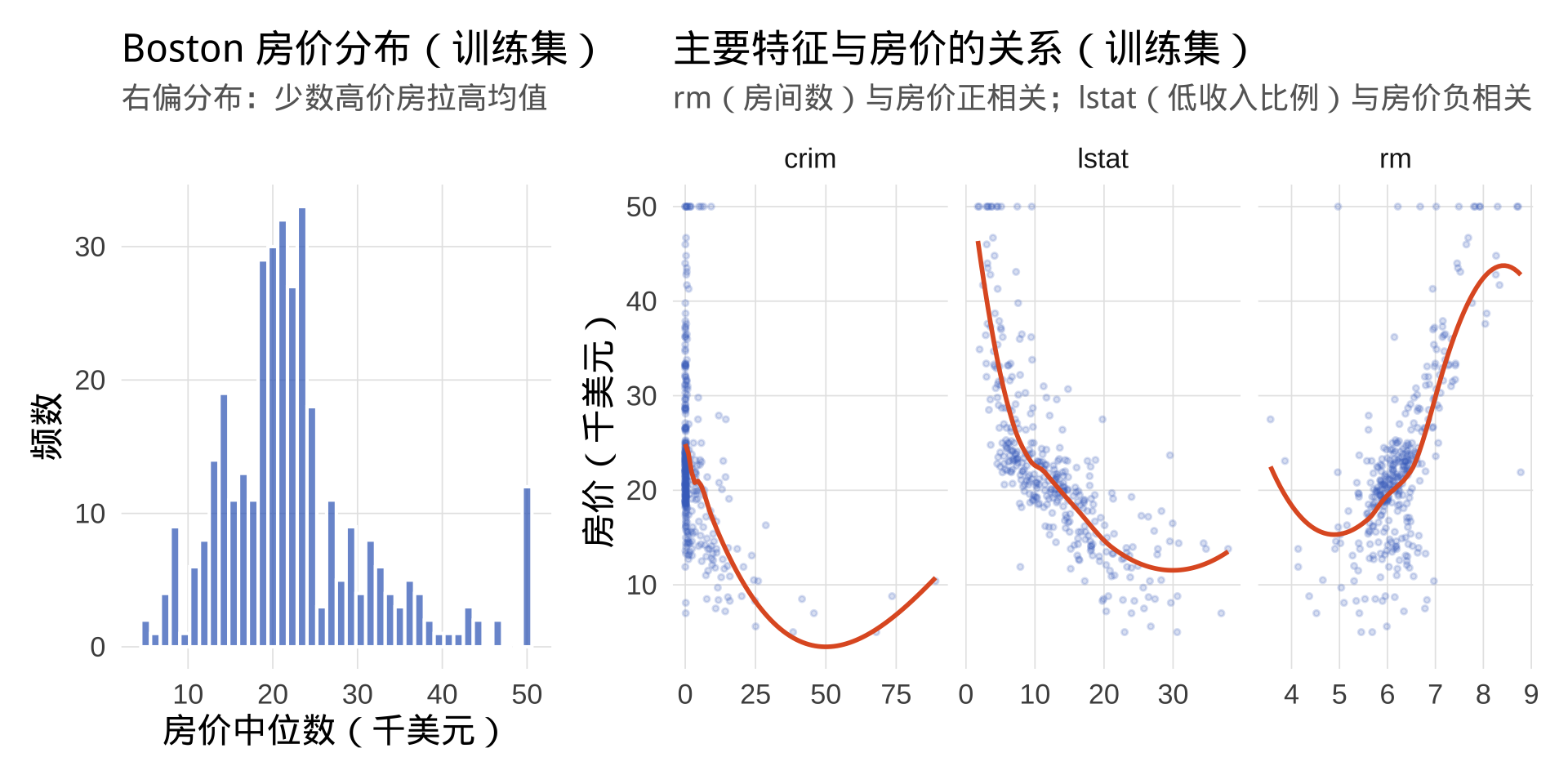
注记
rm(平均房间数)与房价正相关关系最强;lstat(低收入人口比例)与房价负相关。预计决策树会优先选这两个变量进行分裂。
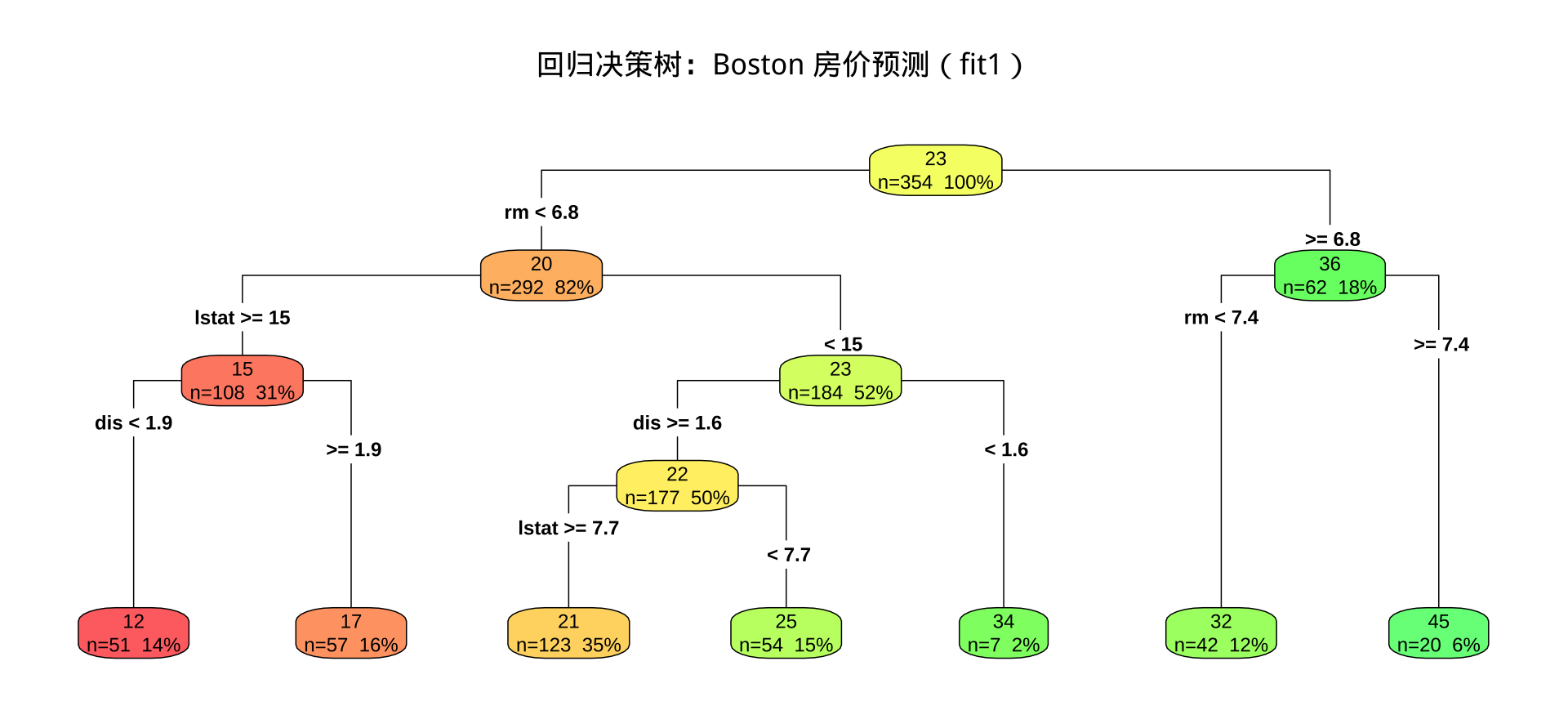
步骤三:回归决策树可视化
▶️ 查看代码
注记
回归树可视化中 extra = 101 显示每个节点的预测均值和样本数,而非类别概率。叶节点中的数值即为该区域内所有训练样本价格的均值。
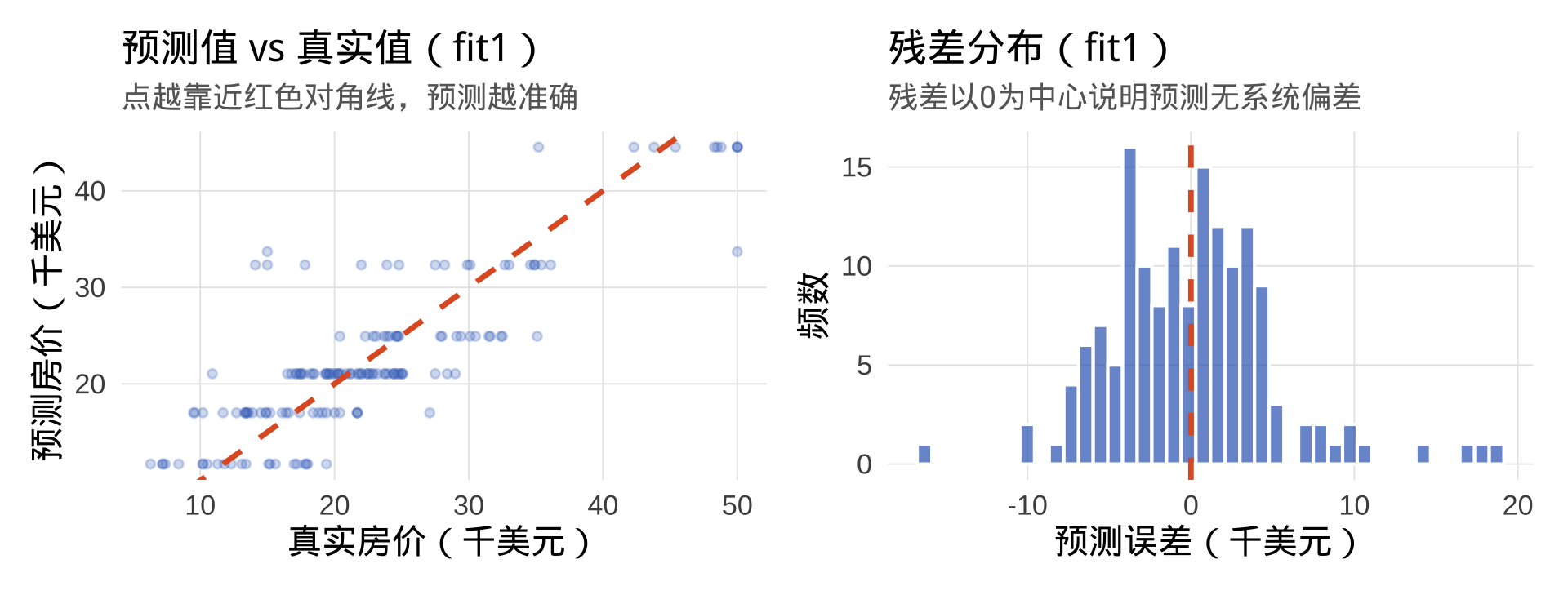
预测准确性分析
注记
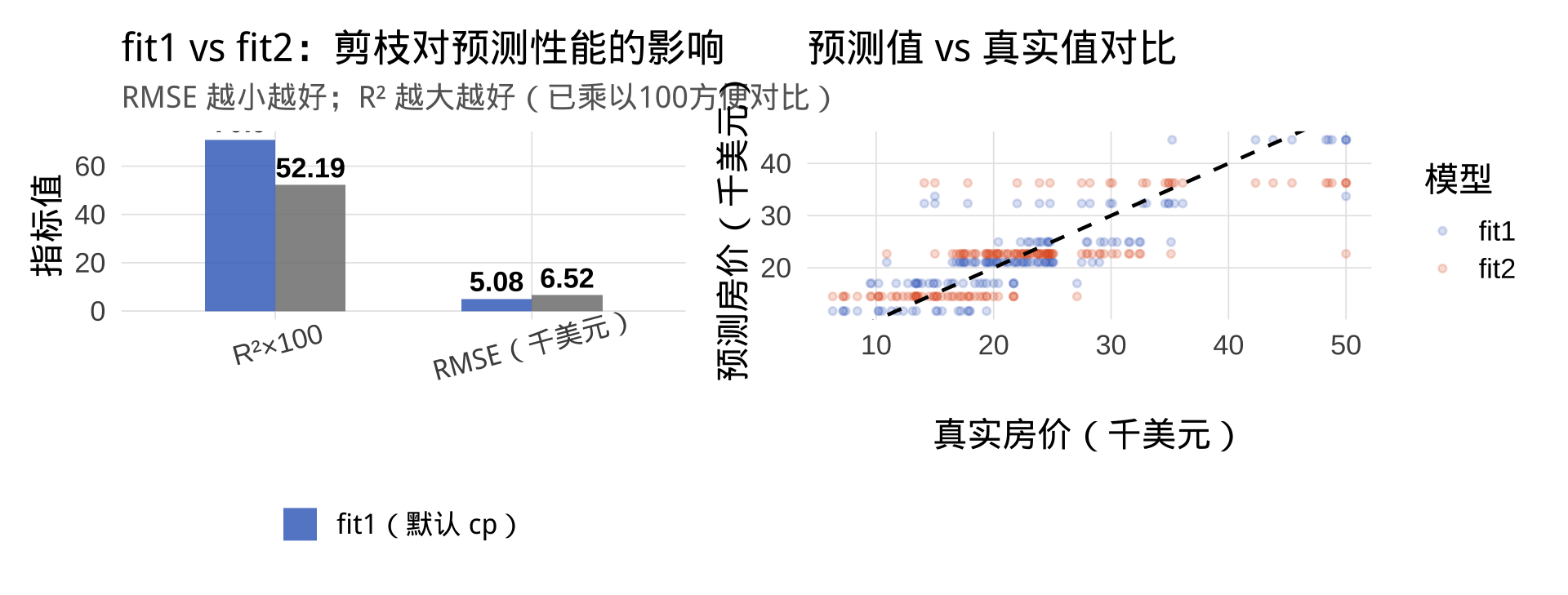
RMSE 的单位与因变量相同(美元)。例如 RMSE ≈ $4,800 意味着平均每套房的预测误差约 4800 美元。结合房价中位数(约 $21,000),可判断预测精度是否可接受。
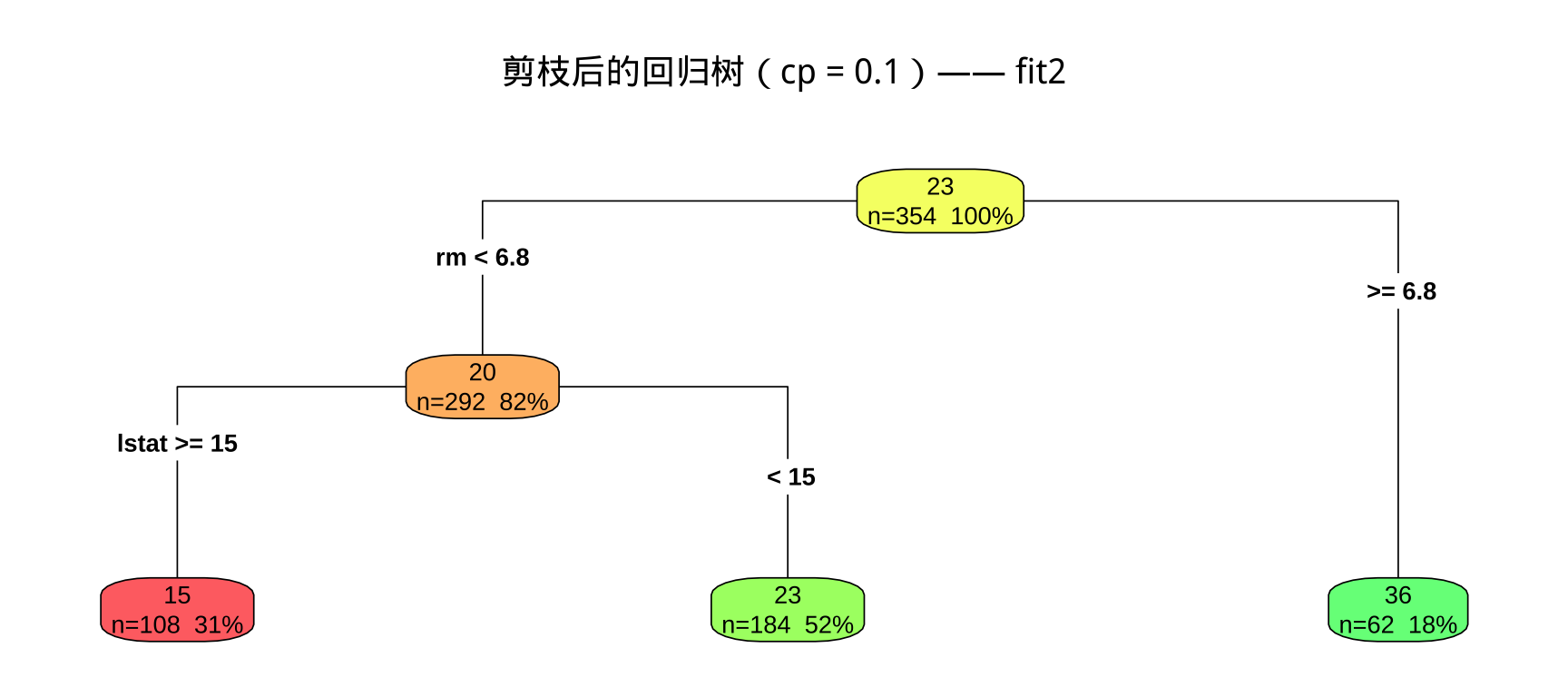
fit2 可视化
两模型对比分析
科学选择最优 cp
▶️ 查看代码
交叉验证误差最小的 cp: 0.01 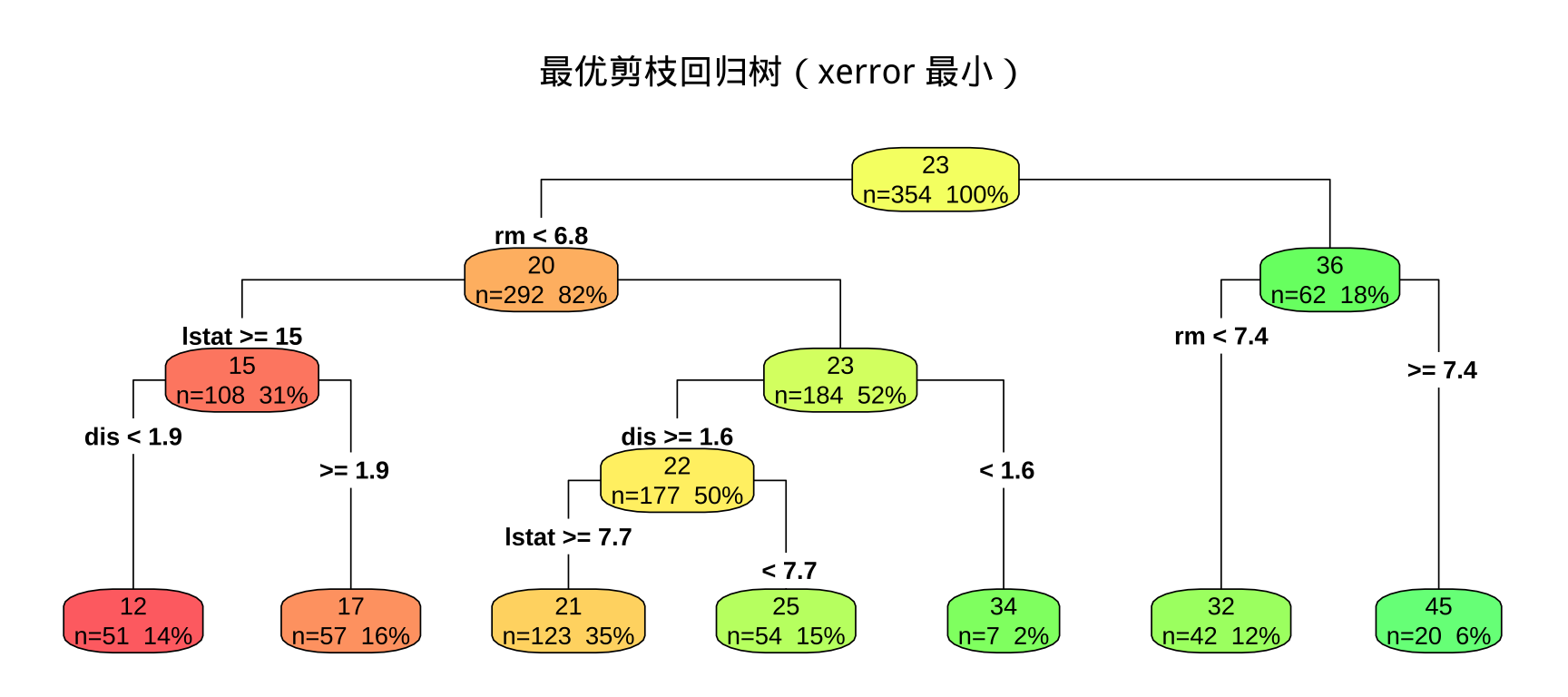
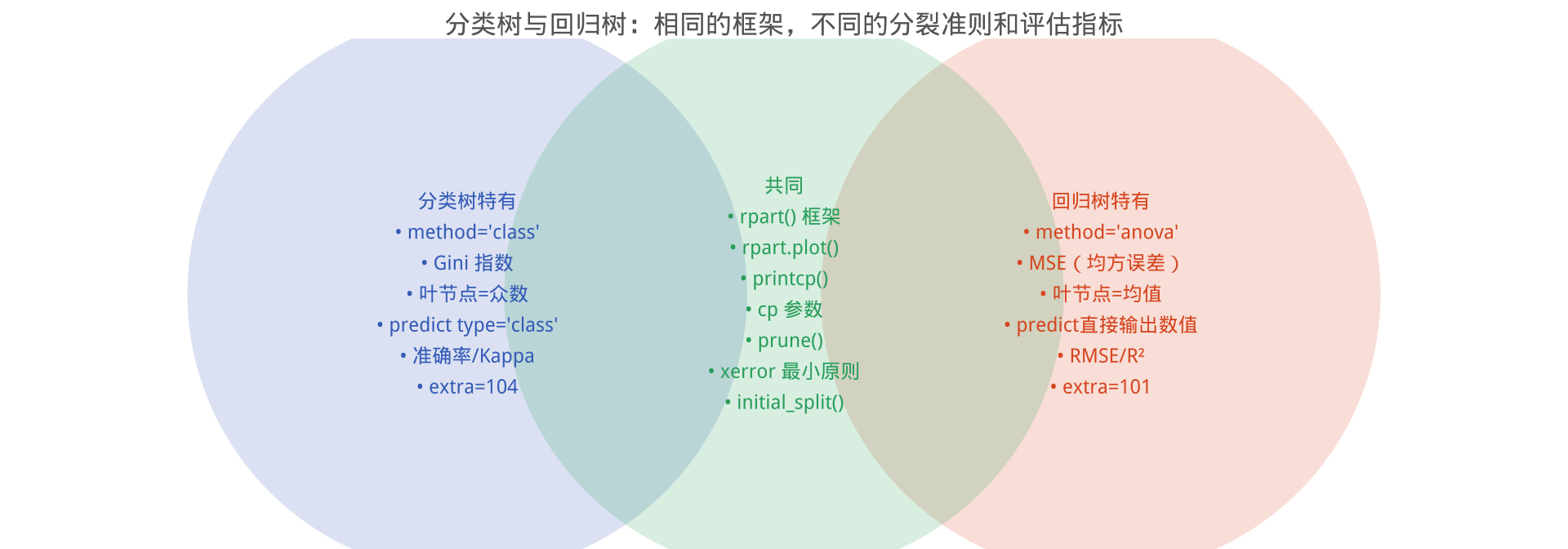
相同点与不同点
完整建模流程回顾

步骤 3:可视化并总结决策路径
▶️ 查看代码
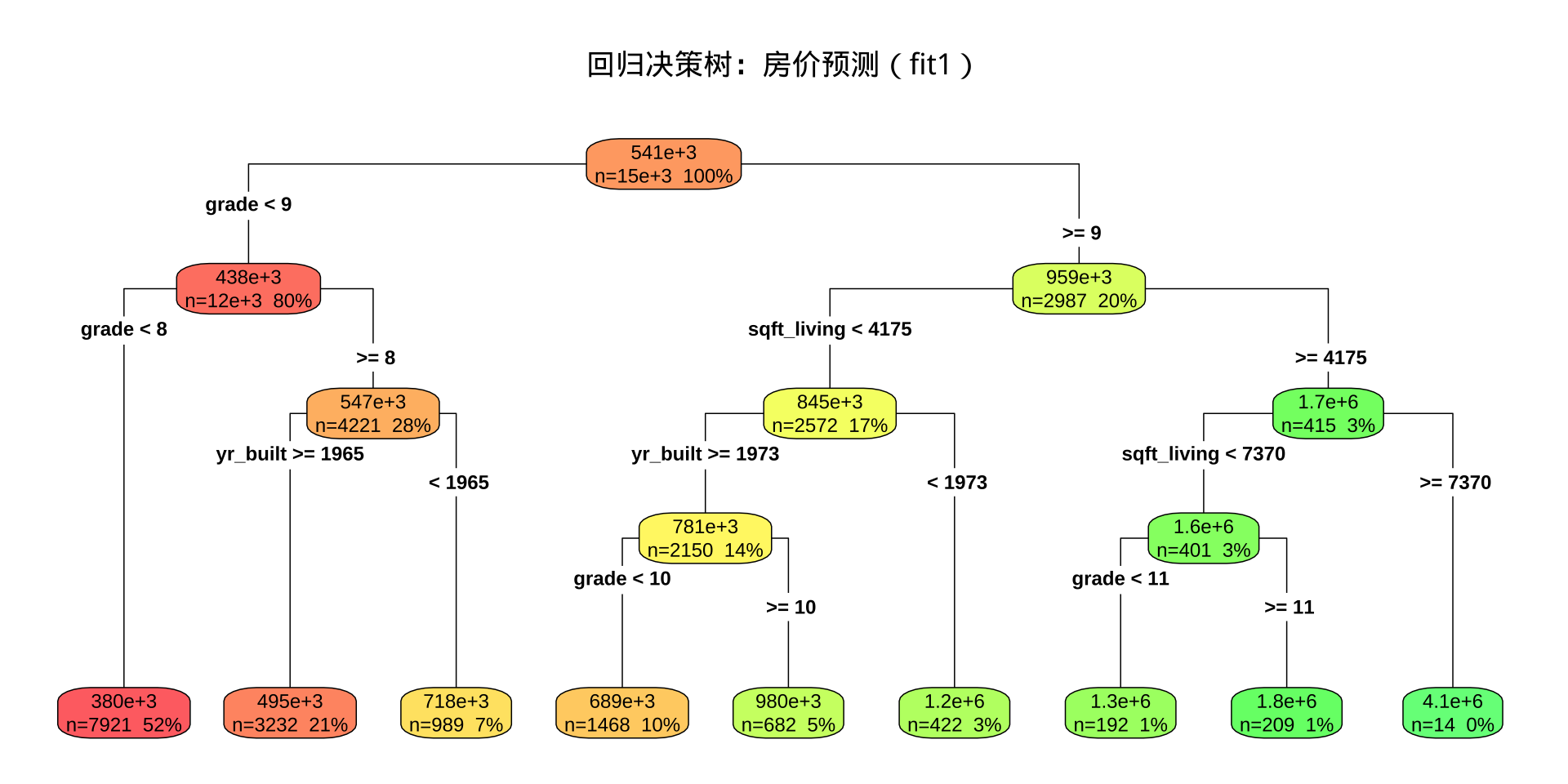
要求: 根据可视化结果,至少总结 一条 完整的决策路径,描述"若……则预测房价约为……",说明该叶节点对应的均值以及样本数量。
步骤 5:cp = 0.1 剪枝,建立 fit2
▶️ 查看代码
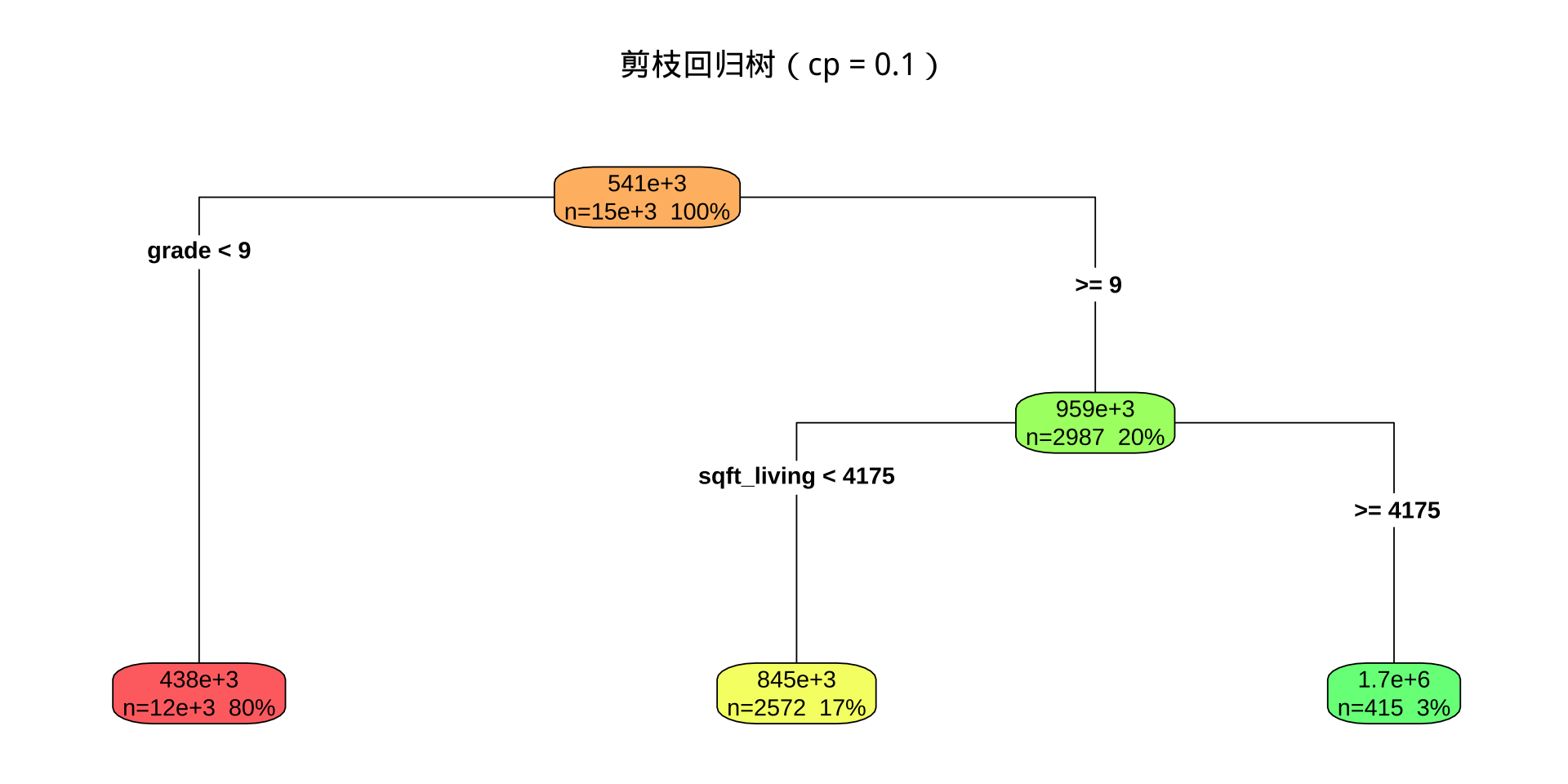
要求: 描述 fit2 的树形结构(节点数、叶节点数);与 fit1 对比说明 cp=0.1 的剪枝效果;fit2 使用了哪些变量?