数据挖掘与R语言
第17讲:集成学习——随机森林
2026年05月27日
集成学习的三种主要方法

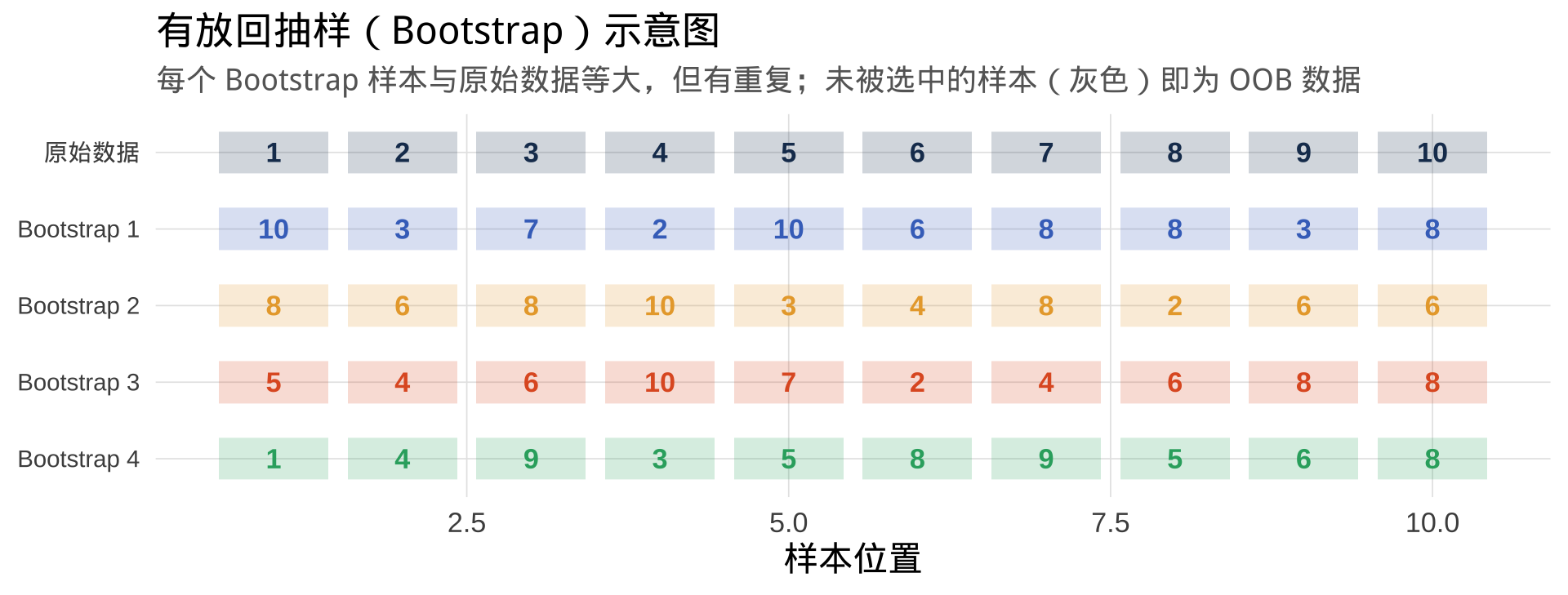
Bootstrap 的可视化理解
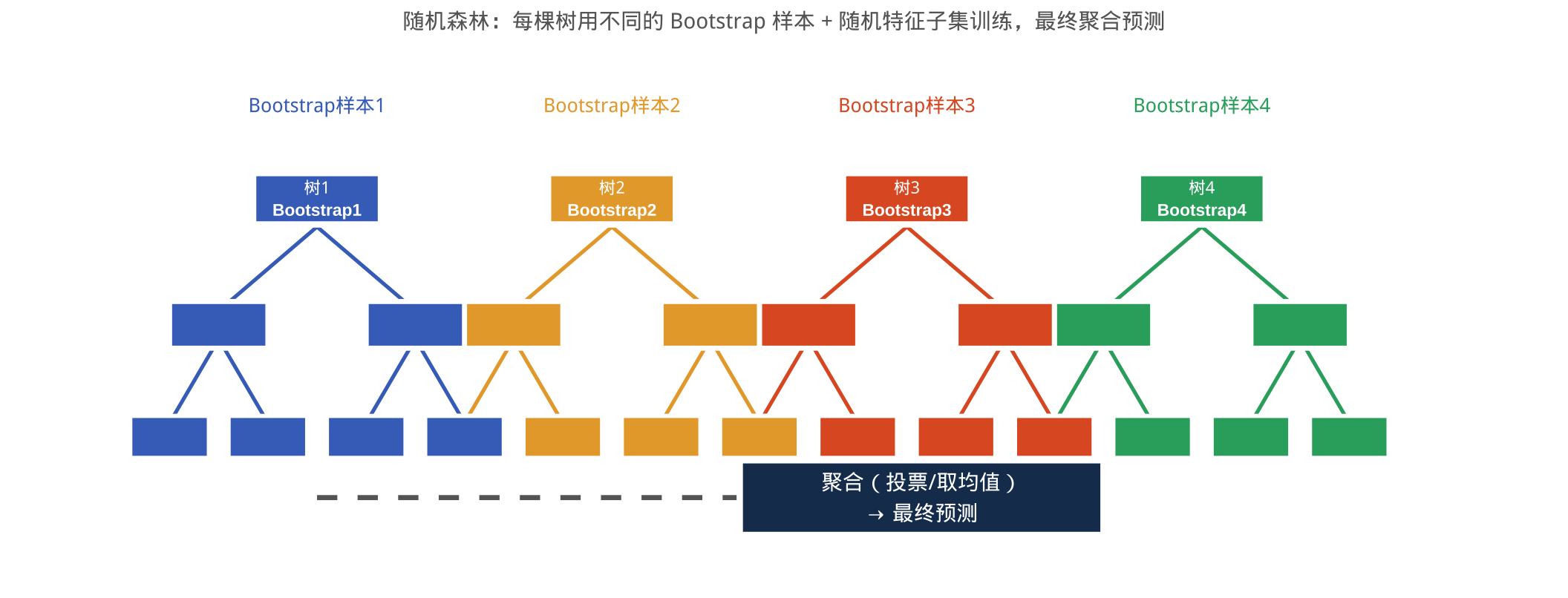
Bagging:Bootstrap + 聚合
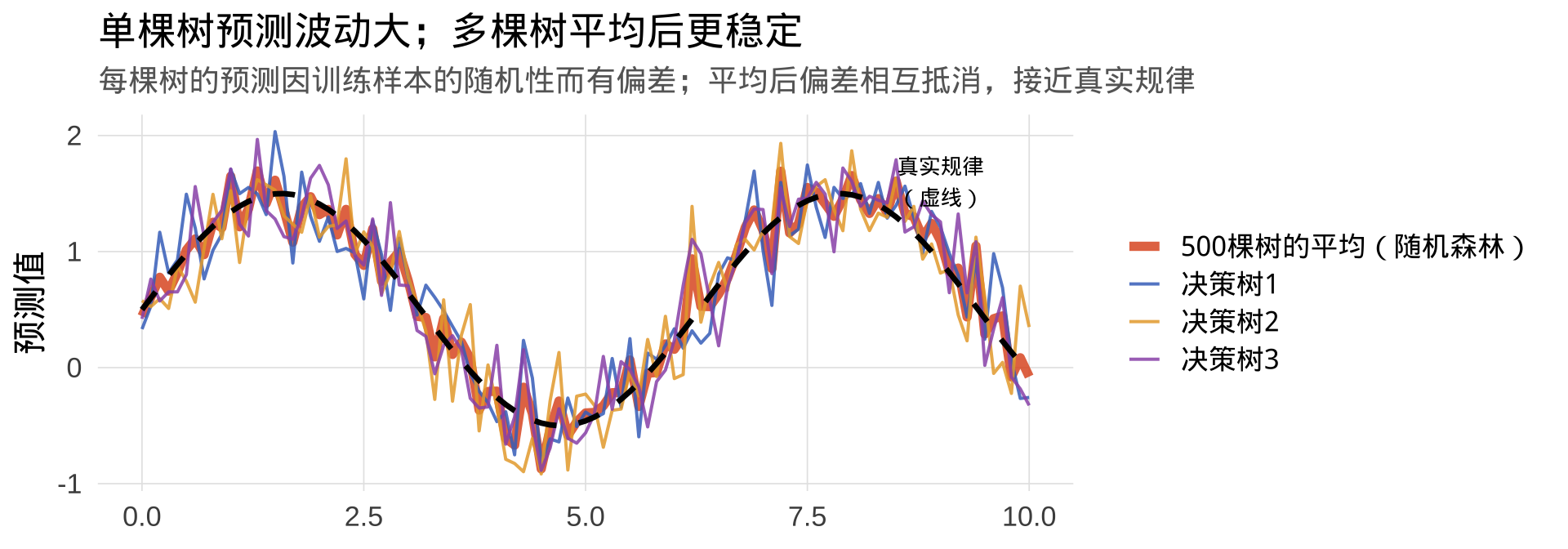
Bagging(Bootstrap Aggregating,自举聚合):
- 对原始训练集做 B 次 Bootstrap 抽样,得到 B 个不同的训练子集
- 在每个子集上独立训练一棵完整的决策树(并行,互不影响)
-
聚合:
- 分类:B 棵树各自投票,取多数票作为最终预测
- 回归:B 棵树各自预测一个数值,取平均值

随机森林完整算法流程
三个最重要的超参数
重要
randomForest() 的关键参数:
| 参数 | 含义 | 默认值 | 经验推荐 |
|---|---|---|---|
ntree |
树的数量 \(B\) | 500 | 通常 500–1000 已足够;太少不稳定,太多浪费计算 |
mtry |
每次分裂随机选取的特征数 \(m\) | 分类:\(\sqrt{p}\);回归:\(p/3\) | 可通过 OOB 误差调优 |
nodesize |
叶节点最小样本数 | 分类:1;回归:5 | 增大可防止过拟合 |
ntree 的选择:
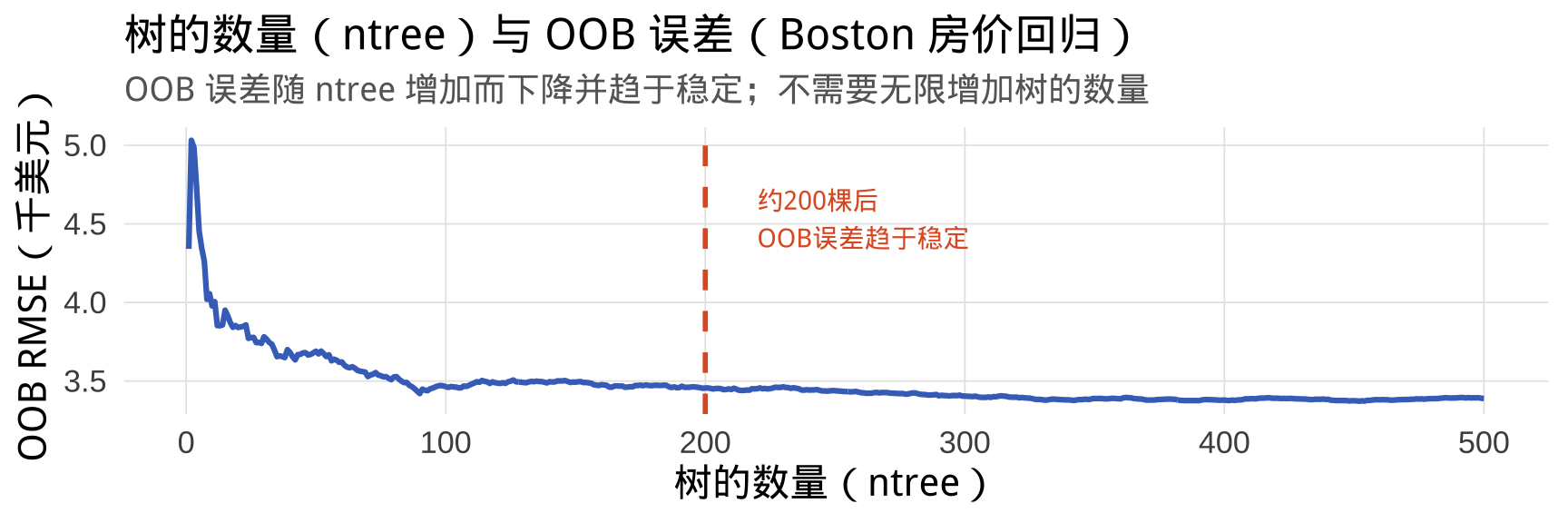
步骤三:OOB 误差随树数量的变化
▶️ 查看代码
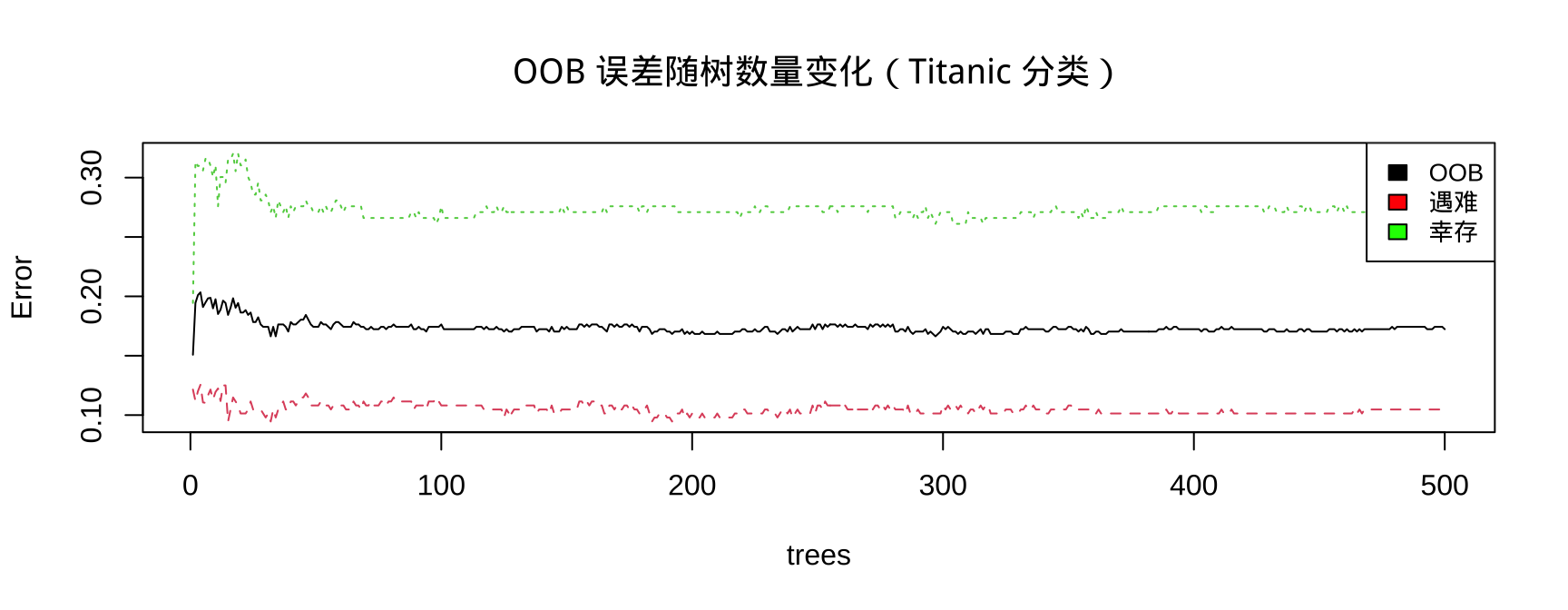
提示
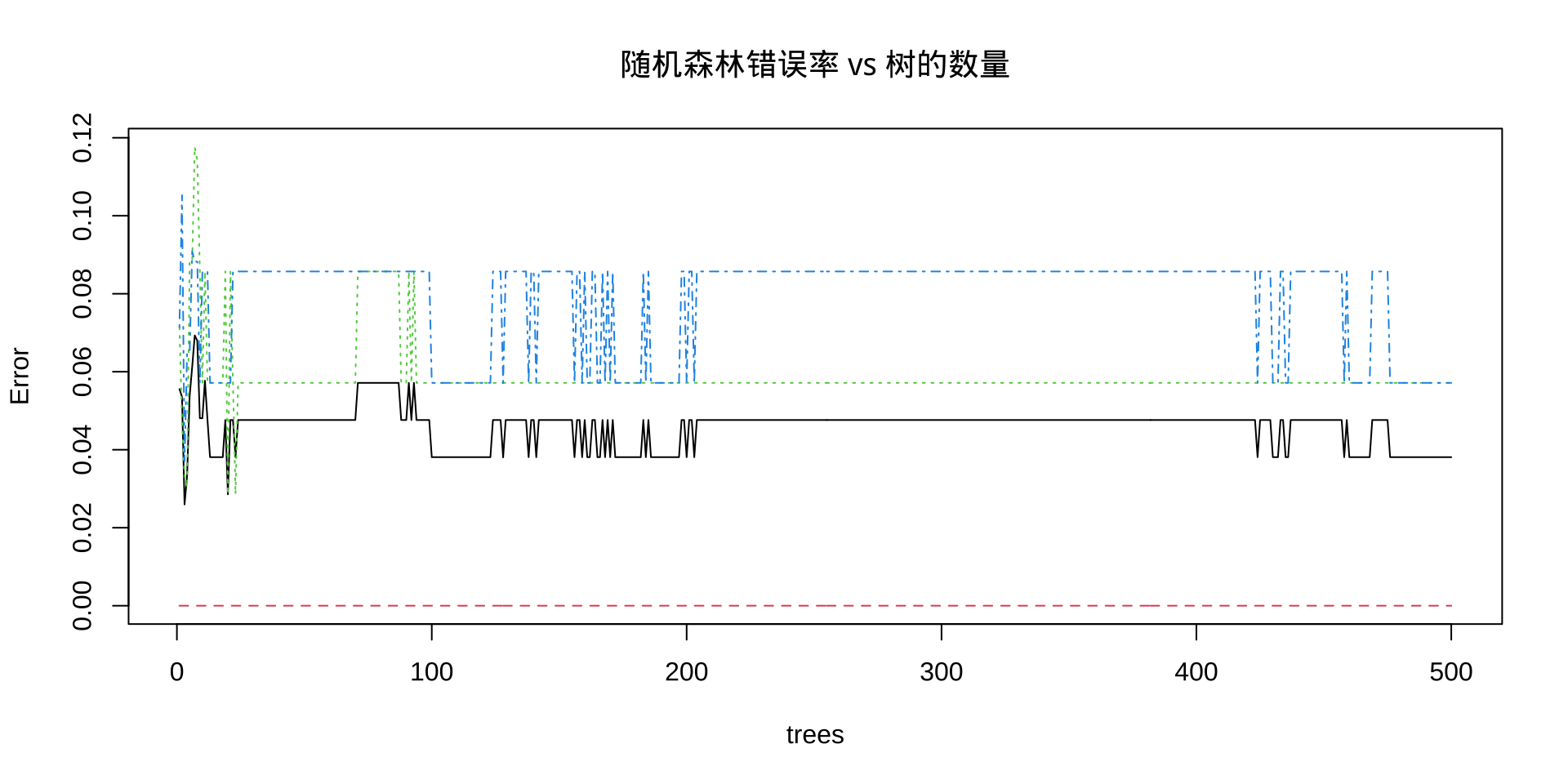
黑色线 = 整体 OOB 误差;红/绿线 = 各类别的 OOB 误差。误差曲线趋于平稳后,增加 ntree 意义不大。
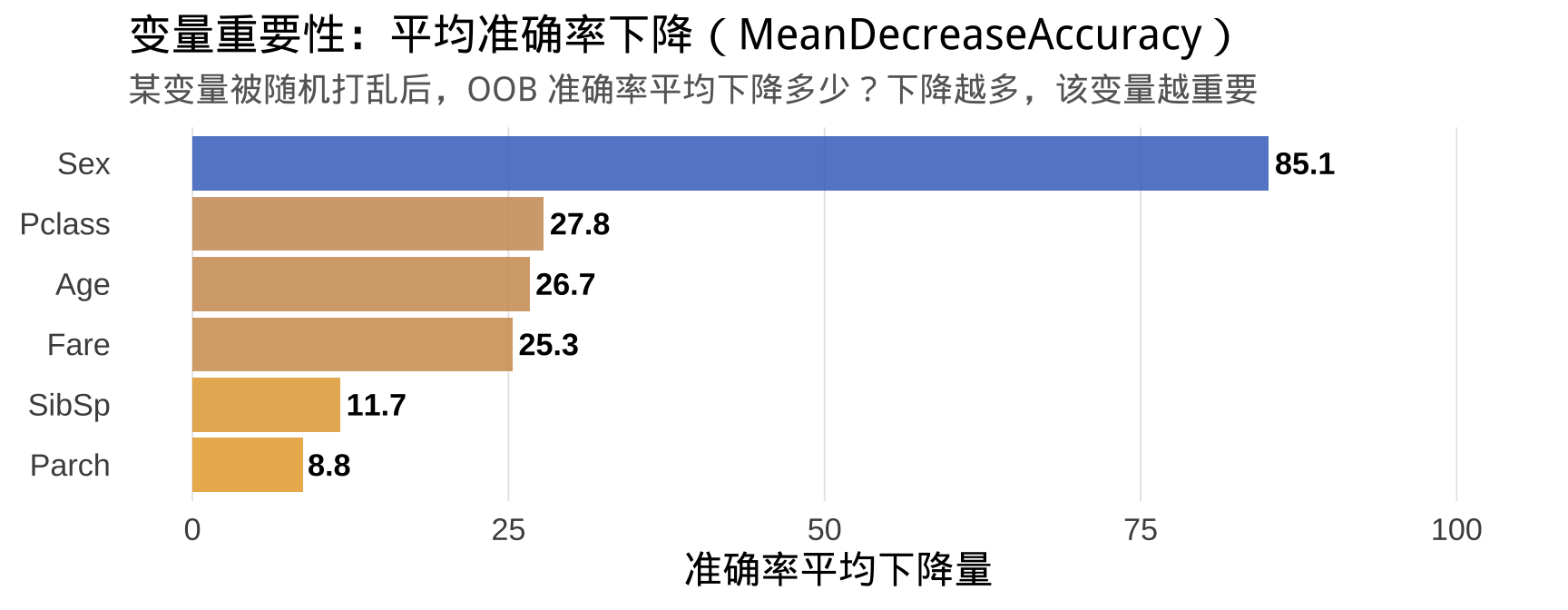
步骤四:变量重要性
遇难 幸存 MeanDecreaseAccuracy MeanDecreaseGini
Pclass 16.055 21.853 27.786 17.12
Sex 67.989 74.054 85.141 70.11
Age 19.289 17.728 26.659 39.32
Fare 16.248 18.248 25.317 42.21
SibSp 11.477 2.295 11.690 9.24
Parch 7.714 2.690 8.773 8.53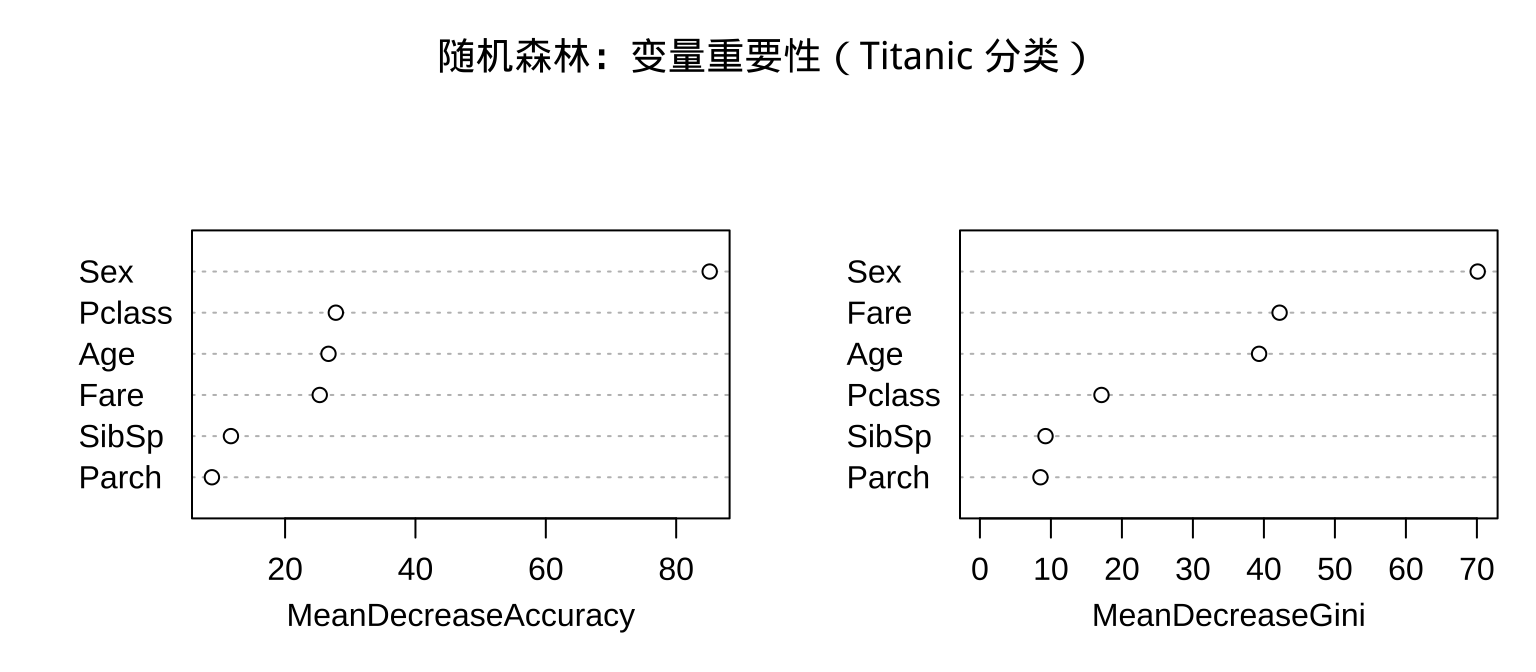
变量重要性详解
注记
两种重要性指标:
- MeanDecreaseAccuracy:随机打乱某变量后,OOB 准确率平均下降量 → 越大越重要
- MeanDecreaseGini:该变量在所有分裂中贡献的 Gini 指数下降总量 → 越大越重要
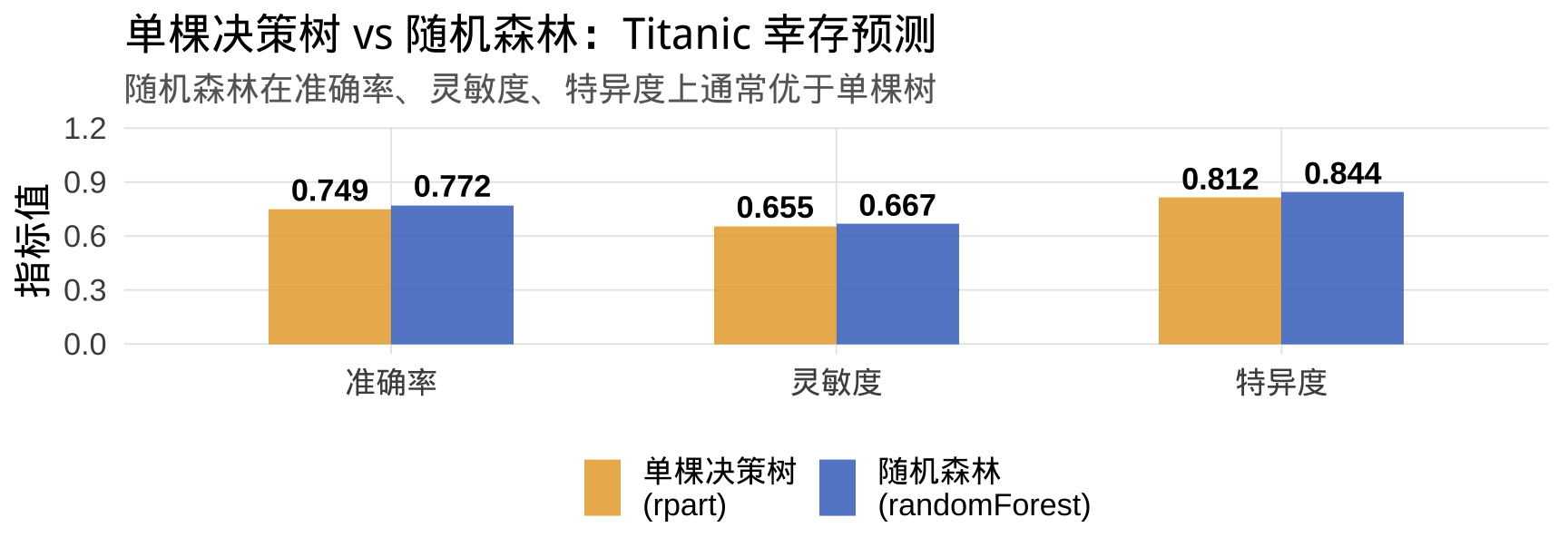
与单棵分类树的对比
步骤二:建立随机森林回归模型
▶️ 查看代码
library(caret)
library(randomForest)
# 设置交叉验证参数(可选,但推荐)
set.seed(42)
ctrl <- trainControl(
method = "repeatedcv", # 重复交叉验证
number = 5, # 5 折
repeats = 2 # 重复 2 次
)
set.seed(42)
rf_reg_caret <- train(
medv ~ .,
data = train_b,
method = "rf", # 随机森林
trControl = ctrl,
ntree = 500,
importance = TRUE,
verbose = FALSE
)
# 查看结果
rf_reg_caretRandom Forest
354 samples
13 predictor
No pre-processing
Resampling: Cross-Validated (5 fold, repeated 2 times)
Summary of sample sizes: 284, 283, 282, 284, 283, 282, ...
Resampling results across tuning parameters:
mtry RMSE Rsquared MAE
2 4.027 0.8312 2.635
7 3.575 0.8536 2.357
13 3.782 0.8305 2.428
RMSE was used to select the optimal model using the smallest value.
The final value used for the model was mtry = 7. mtry
2 7
Call:
randomForest(x = x, y = y, ntree = 500, mtry = param$mtry, importance = TRUE, verbose = FALSE)
Type of random forest: regression
Number of trees: 500
No. of variables tried at each split: 7
Mean of squared residuals: 11.52
% Var explained: 86.03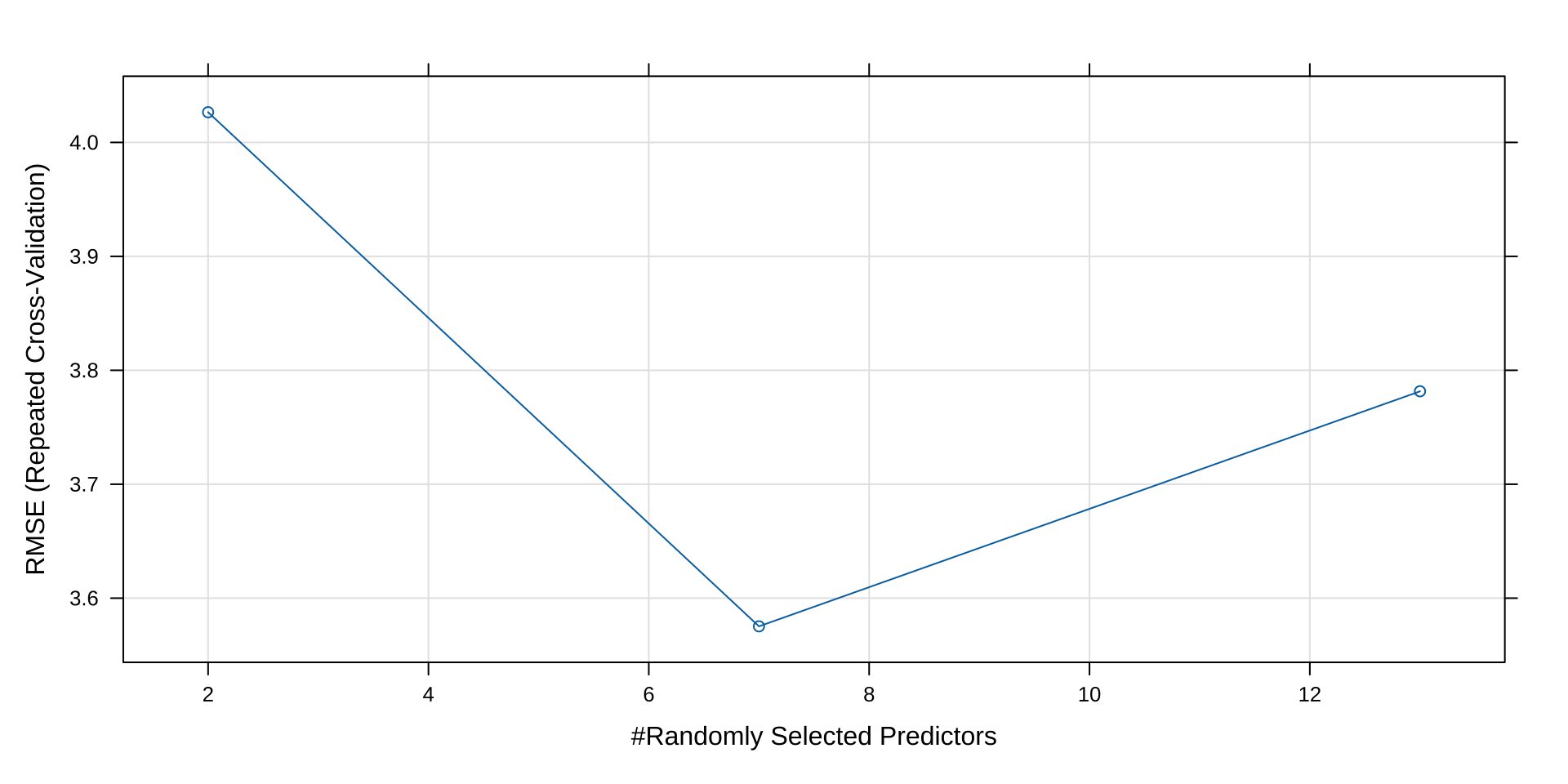
注记
caret::train() 会自动调整 mtry 参数。如果不指定 tuneGrid,它会在默认的几个 mtry 值中自动选择最优值。
caret 的 train() 会输出 RMSE 和 R² 的交叉验证均值,而非 OOB 误差。原始随机森林的 OOB 指标仍在 rf_reg_caret$finalModel 中。
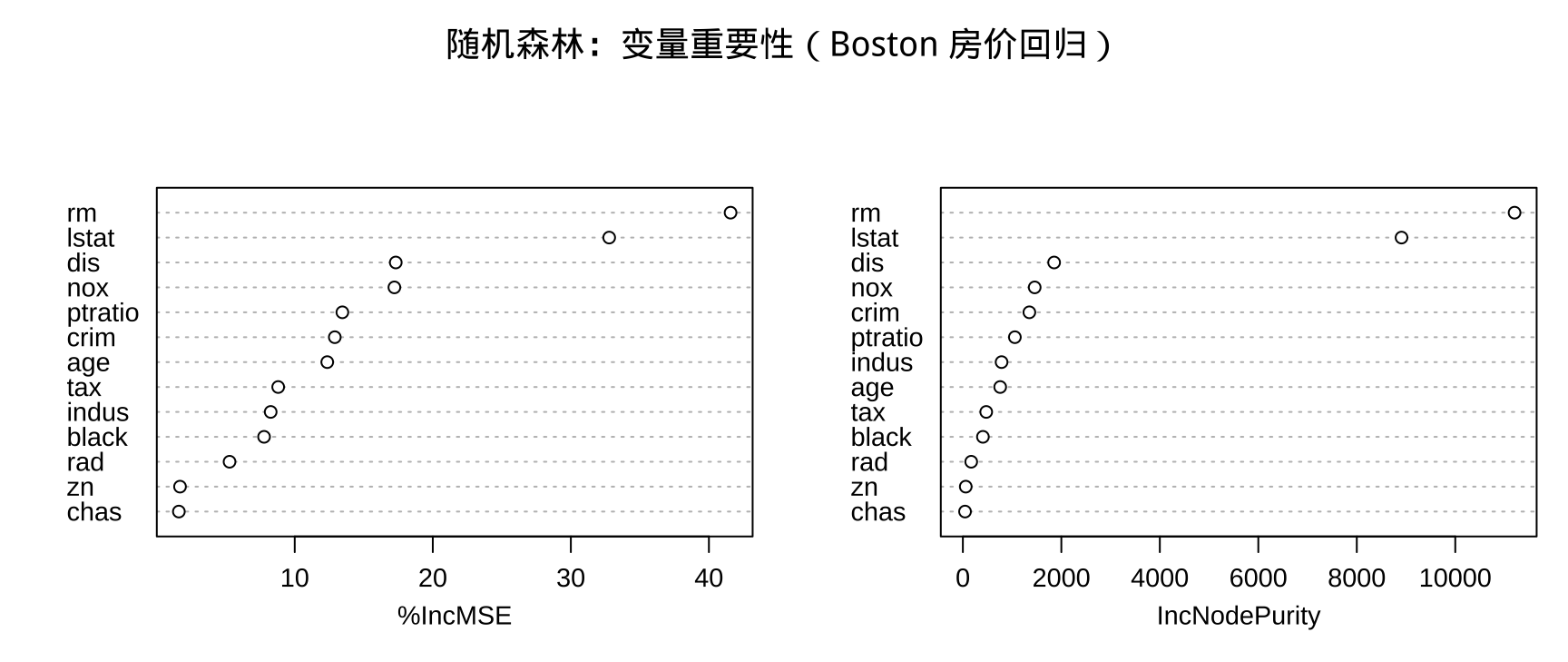
步骤四:变量重要性可视化
▶️ 查看代码
rf variable importance
Overall
rm 100.000
lstat 77.999
dis 39.315
nox 39.065
ptratio 29.637
crim 28.263
age 26.896
tax 18.004
indus 16.642
black 15.442
rad 9.186
zn 0.209
chas 0.000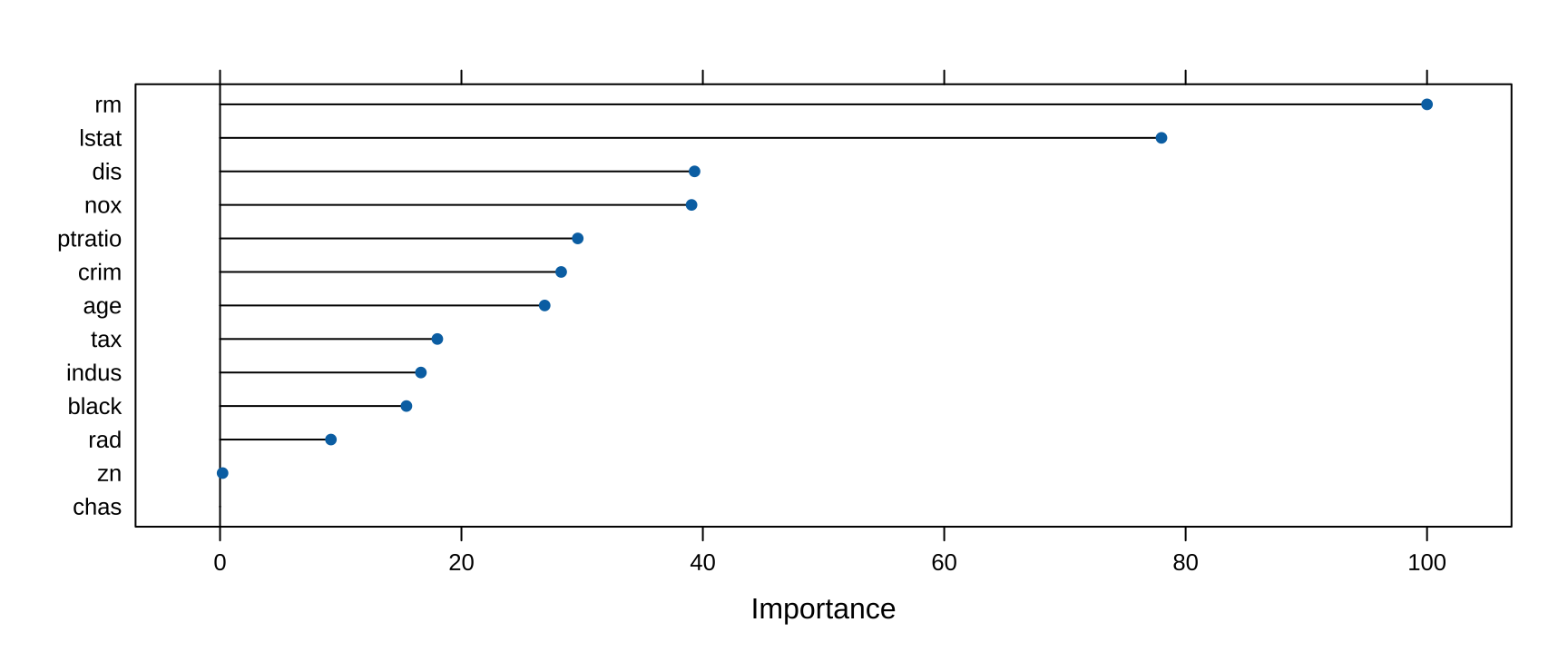
注记
回归随机森林的重要性指标:MeanDecreaseNodePurity(即 RSS 总下降量),对应分类树的 MeanDecreaseGini。lstat(低收入比例)和 rm(平均房间数)通常是波士顿房价最重要的预测变量。
步骤五:预测效果可视化
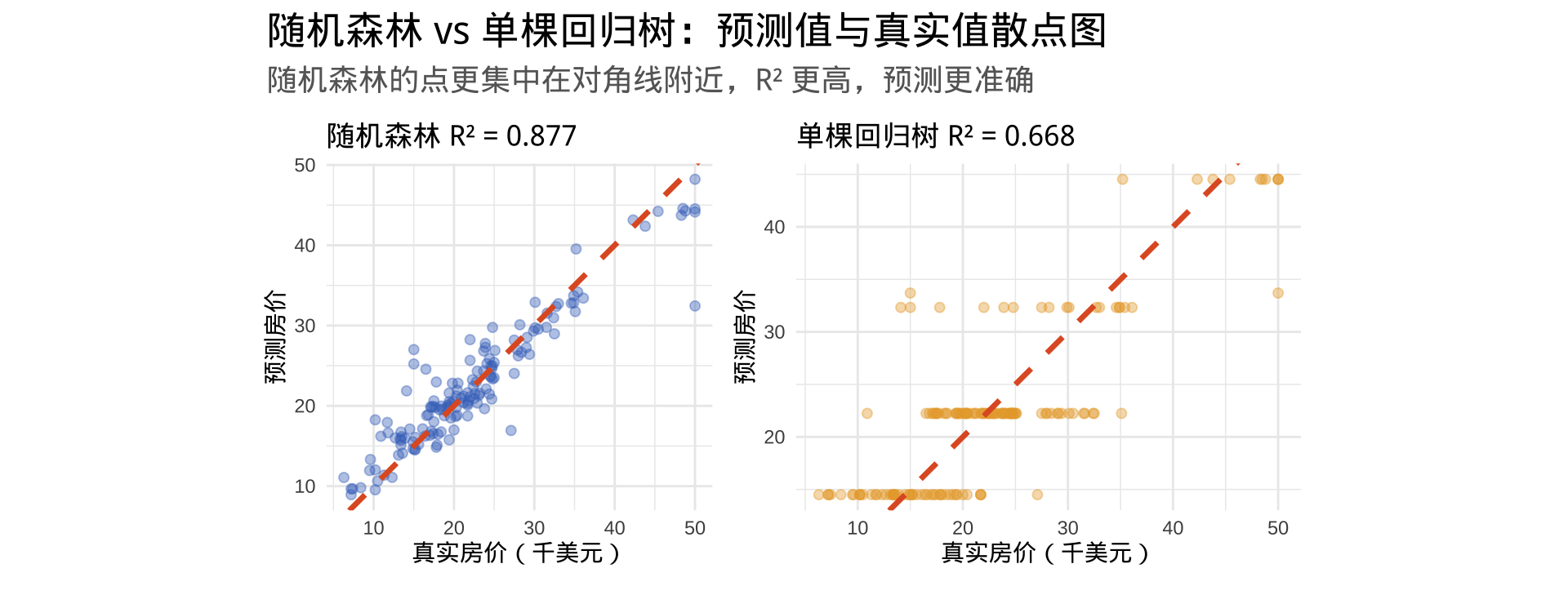
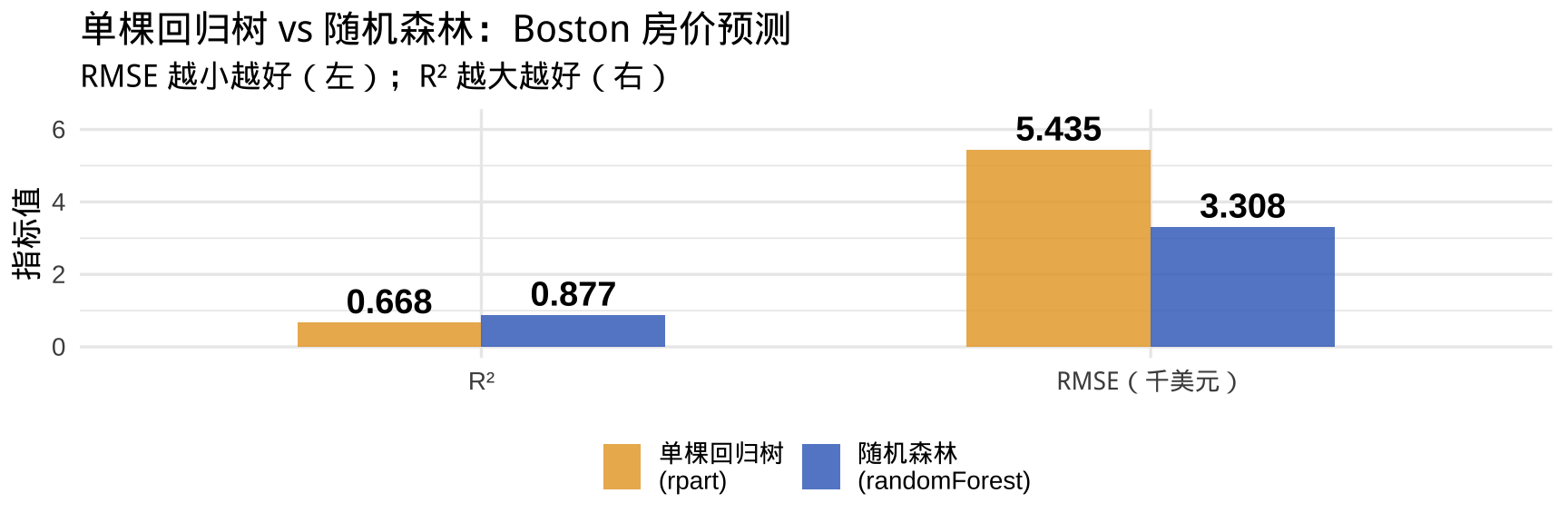
随机森林 vs 单棵回归树:数值对比
重要
随机森林通过集成多棵树,通常能显著降低 RMSE 并提升 R²。代价是计算时间增加和可解释性降低(无法像单棵树那样直观展示决策路径,但可通过变量重要性部分弥补)。
何时选择哪个模型?

完整建模流程回顾

作业说明
项目介绍: 项目介绍:现有鸢尾花数据集iris(R内置数据集),需要通过鸢尾花的花瓣长度、宽度、花萼长度和宽度四个属性信息,建立关于鸢尾花类型Species的随机森林模型。将70%数据进行模型训练,30%数据进行模型验证,分析模型预测的准确性。
9.1
读入数据文件,将数据集进行划分,70%为训练数据集,30%为测试数据集,见参考代码。查看训练数据集和测试数据集的结构信息。并分析训练数据集的结构信息。
'data.frame': 150 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...▶️ 查看代码
训练集样本数: 105 测试集样本数: 45 'data.frame': 105 obs. of 5 variables:
$ Sepal.Length: num 4.9 4.7 4.6 5 5.4 4.9 5.4 4.3 5.7 5.4 ...
$ Sepal.Width : num 3 3.2 3.1 3.6 3.9 3.1 3.7 3 4.4 3.9 ...
$ Petal.Length: num 1.4 1.3 1.5 1.4 1.7 1.5 1.5 1.1 1.5 1.3 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.4 0.1 0.2 0.1 0.4 0.4 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ... Sepal.Length Sepal.Width Petal.Length Petal.Width Species
Min. :4.30 Min. :2.20 Min. :1.00 Min. :0.1 setosa :35
1st Qu.:5.20 1st Qu.:2.80 1st Qu.:1.50 1st Qu.:0.3 versicolor:35
Median :5.70 Median :3.00 Median :4.20 Median :1.3 virginica :35
Mean :5.84 Mean :3.07 Mean :3.76 Mean :1.2
3rd Qu.:6.30 3rd Qu.:3.40 3rd Qu.:5.10 3rd Qu.:1.8
Max. :7.90 Max. :4.40 Max. :6.90 Max. :2.5
setosa versicolor virginica
35 35 35 9.2
用训练数据集运用train函数进行随机森林建模,得到模型结果为rfModel,定义采样方法为repeatedcv,5折交叉验证,迭代5次。随机数种子为1000次。因变量为Species ,其余变量为自变量。分析随机森林的特征选择不同组合下的平均分类准确率。
▶️ 查看代码
# 2.1 设置交叉验证参数
set.seed(1000)
ctrl <- trainControl(
method = "repeatedcv", # 重复交叉验证
number = 5, # 5 折
repeats = 5 # 迭代 5 次
)
# 2.2 训练随机森林模型
rfModel <- train(
Species ~ .,
data = train_data,
method = "rf",
trControl = ctrl,
importance = TRUE,
ntree = 500,
verbose = FALSE
)
# 2.3 查看模型结果
print(rfModel)Random Forest
105 samples
4 predictor
3 classes: 'setosa', 'versicolor', 'virginica'
No pre-processing
Resampling: Cross-Validated (5 fold, repeated 5 times)
Summary of sample sizes: 84, 84, 84, 84, 84, 84, ...
Resampling results across tuning parameters:
mtry Accuracy Kappa
2 0.9562 0.9343
3 0.9600 0.9400
4 0.9581 0.9371
Accuracy was used to select the optimal model using the largest value.
The final value used for the model was mtry = 3.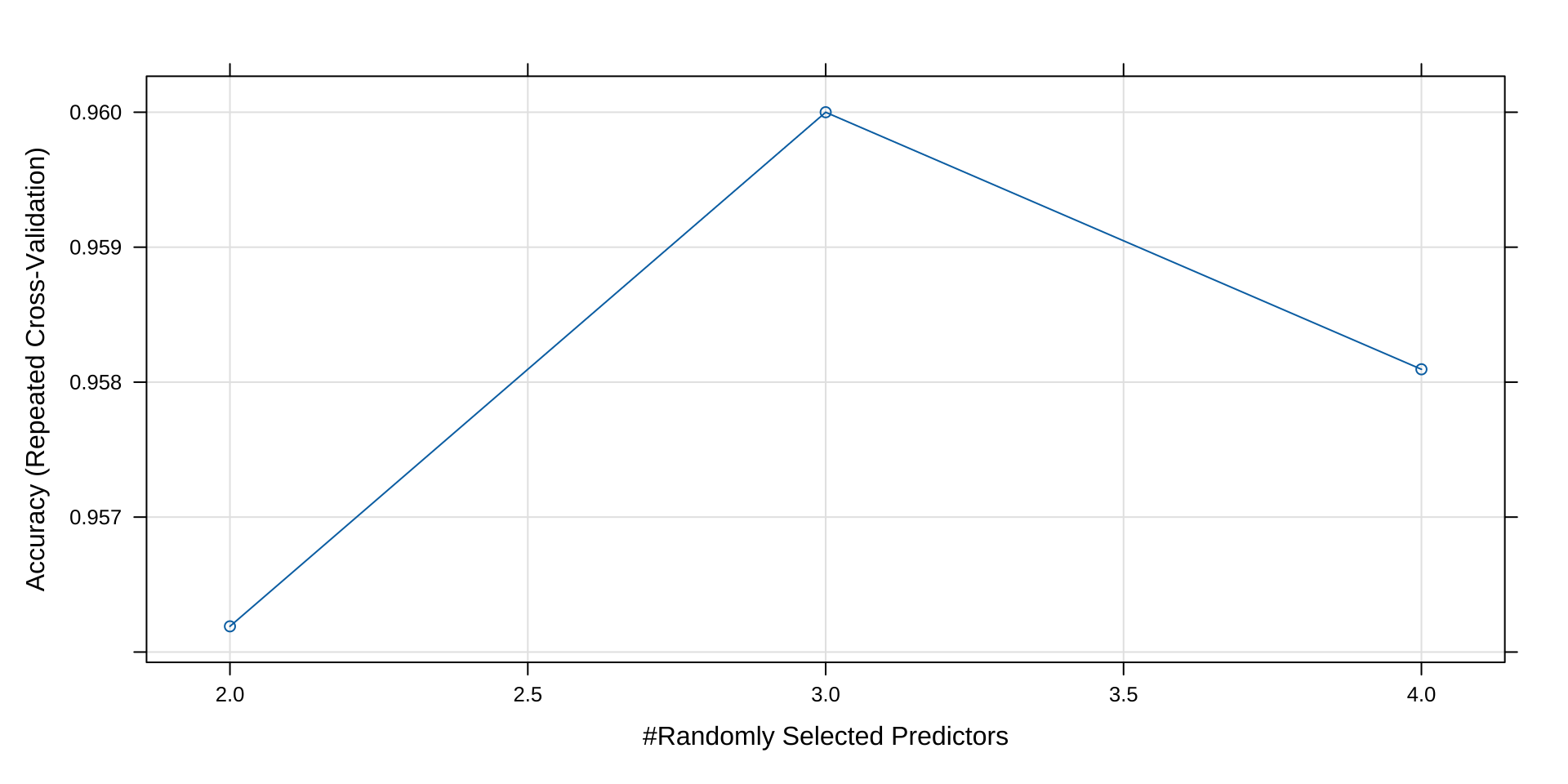
mtry
2 39.3
将模型rfModel,应用于测试数据集testset,通过CrossTable函数来分析模型的预测准确率。
▶️ 查看代码
Cell Contents
|-------------------------|
| N |
| N / Col Total |
| N / Table Total |
|-------------------------|
Total Observations in Table: 45
| 预测类别
实际类别 | setosa | versicolor | virginica | Row Total |
-------------|------------|------------|------------|------------|
setosa | 15 | 0 | 0 | 15 |
| 1.000 | 0.000 | 0.000 | |
| 0.333 | 0.000 | 0.000 | |
-------------|------------|------------|------------|------------|
versicolor | 0 | 15 | 0 | 15 |
| 0.000 | 0.882 | 0.000 | |
| 0.000 | 0.333 | 0.000 | |
-------------|------------|------------|------------|------------|
virginica | 0 | 2 | 13 | 15 |
| 0.000 | 0.118 | 1.000 | |
| 0.000 | 0.044 | 0.289 | |
-------------|------------|------------|------------|------------|
Column Total | 15 | 17 | 13 | 45 |
| 0.333 | 0.378 | 0.289 | |
-------------|------------|------------|------------|------------|
▶️ 查看代码
模型准确率(caret): 0.9556 9.4
用训练数据集运用randomForest函数进行随机森林建模,设置随机数种子1000,以Species为因变量;查看模型信息,并分析模型的错误率。
▶️ 查看代码
Call:
randomForest(formula = Species ~ ., data = train_data, ntree = 500, importance = TRUE)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 2
OOB estimate of error rate: 3.81%
Confusion matrix:
setosa versicolor virginica class.error
setosa 35 0 0 0.00000
versicolor 0 33 2 0.05714
virginica 0 2 33 0.05714▶️ 查看代码
OOB 错误率: 0.0381 setosa versicolor virginica class.error
setosa 35 0 0 0.00000
versicolor 0 33 2 0.05714
virginica 0 2 33 0.057149.5
对随机森林结果可视化,并分析建立多少树的时候模型预测的分类结果趋于稳定。
6、将模型应用于测试数据集,并分析模型预测准确性:模型准确率、精准度、召回率。
▶️ 查看代码
Confusion Matrix and Statistics
预测
实际 setosa versicolor virginica
setosa 15 0 0
versicolor 0 15 0
virginica 0 2 13
Overall Statistics
Accuracy : 0.956
95% CI : (0.849, 0.995)
No Information Rate : 0.378
P-Value [Acc > NIR] : 2.61e-16
Kappa : 0.933
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: setosa Class: versicolor Class: virginica
Sensitivity 1.000 0.882 1.000
Specificity 1.000 1.000 0.938
Pos Pred Value 1.000 1.000 0.867
Neg Pred Value 1.000 0.933 1.000
Prevalence 0.333 0.378 0.289
Detection Rate 0.333 0.333 0.289
Detection Prevalence 0.333 0.333 0.333
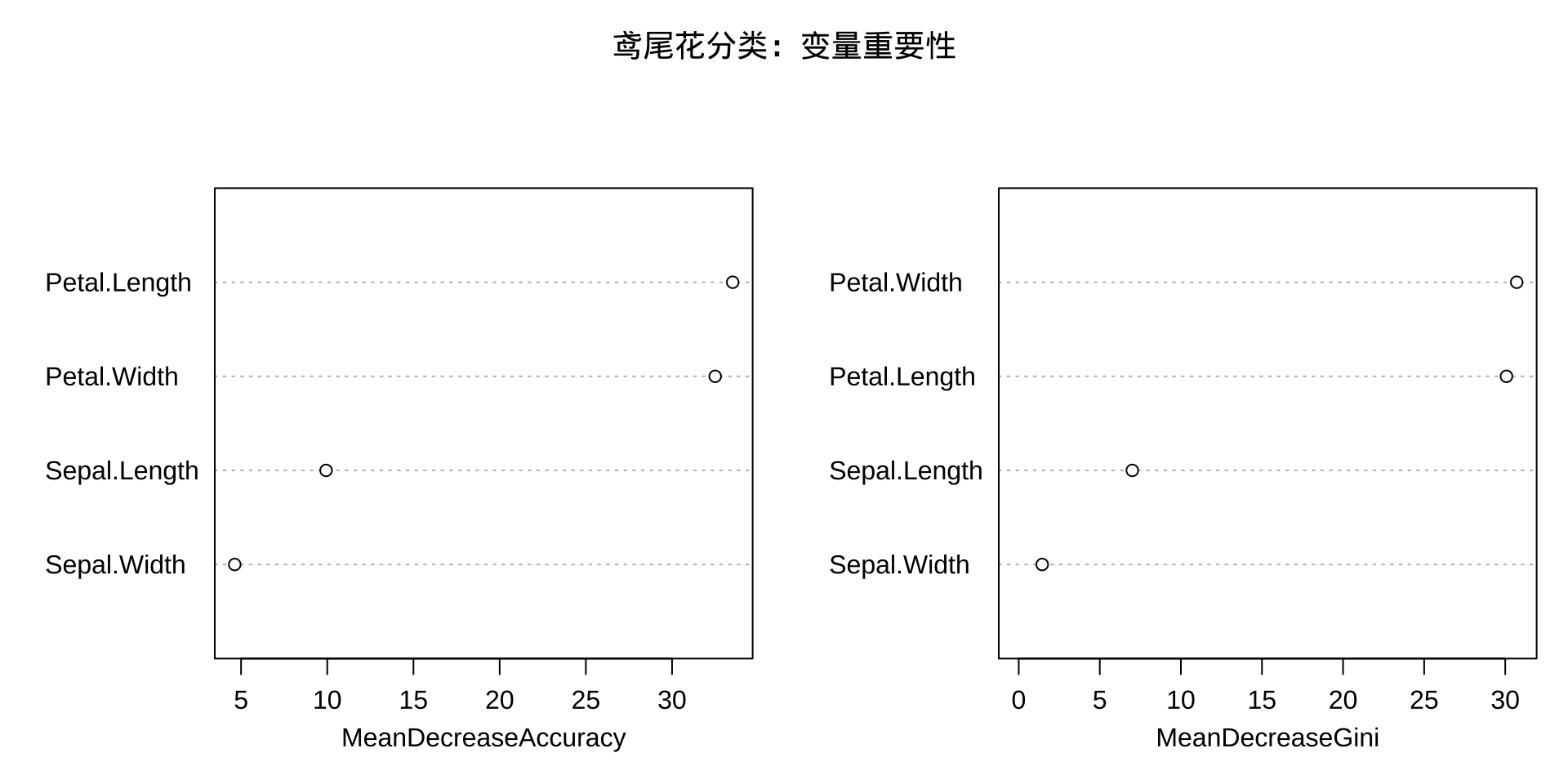
Balanced Accuracy 1.000 0.941 0.9697、对各个自变量进行重要程度度量,并按照变量重要程度降序排列。
setosa versicolor virginica MeanDecreaseAccuracy MeanDecreaseGini
Sepal.Length 6.263 0.5197 10.20 9.931 7.004
Sepal.Width 4.836 1.2470 2.88 4.631 1.448
Petal.Length 23.430 30.7303 26.12 33.518 30.075
Petal.Width 20.642 29.2989 29.17 32.502 30.707