数据挖掘与R语言
第18讲:层次聚类(Hierarchical Clustering)
2026年05月29日
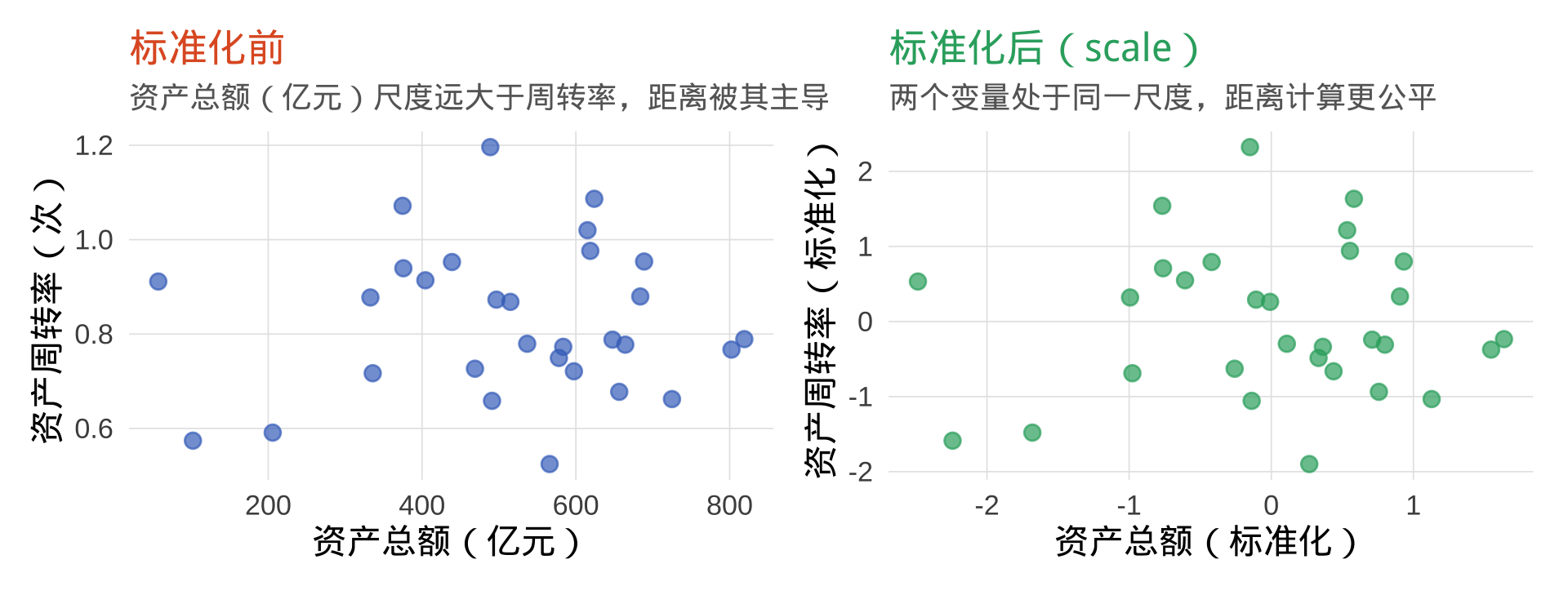
为什么要标准化?
凝聚法的基本思路
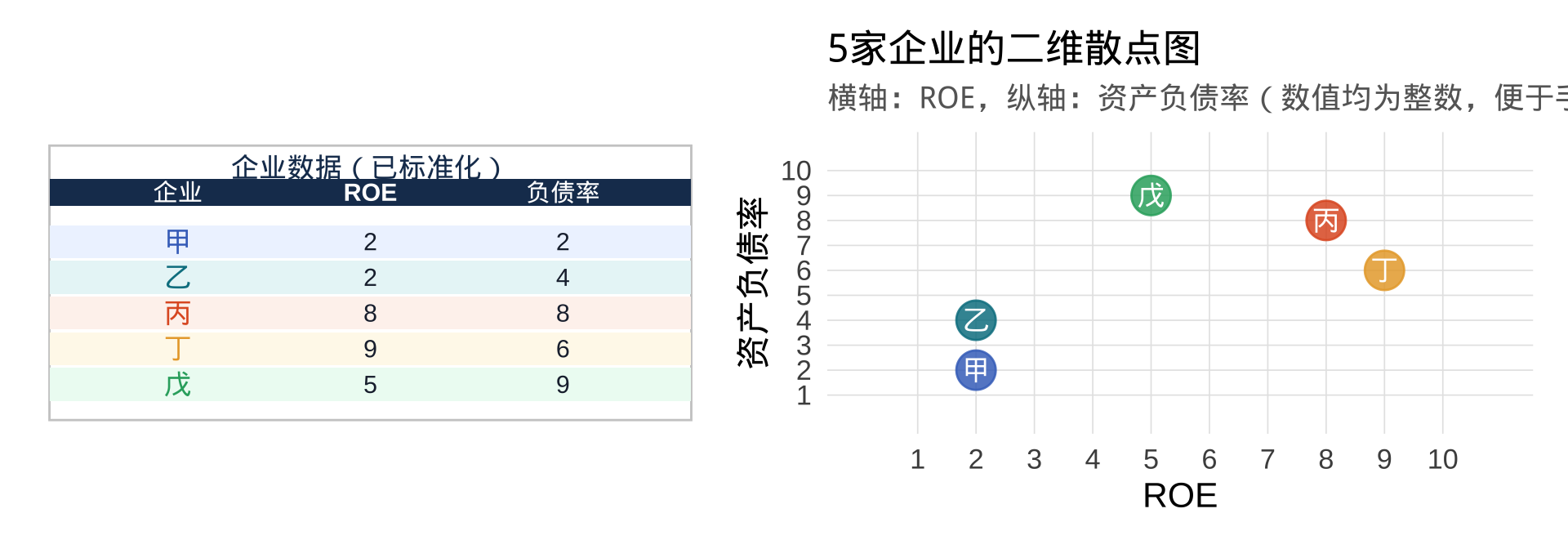
场景:对 5 家企业按财务指标进行层次聚类
设有 5 家企业,每家有两个指标:ROE(净资产收益率) 和 资产负债率(均已标准化):
注记
凝聚法算法:
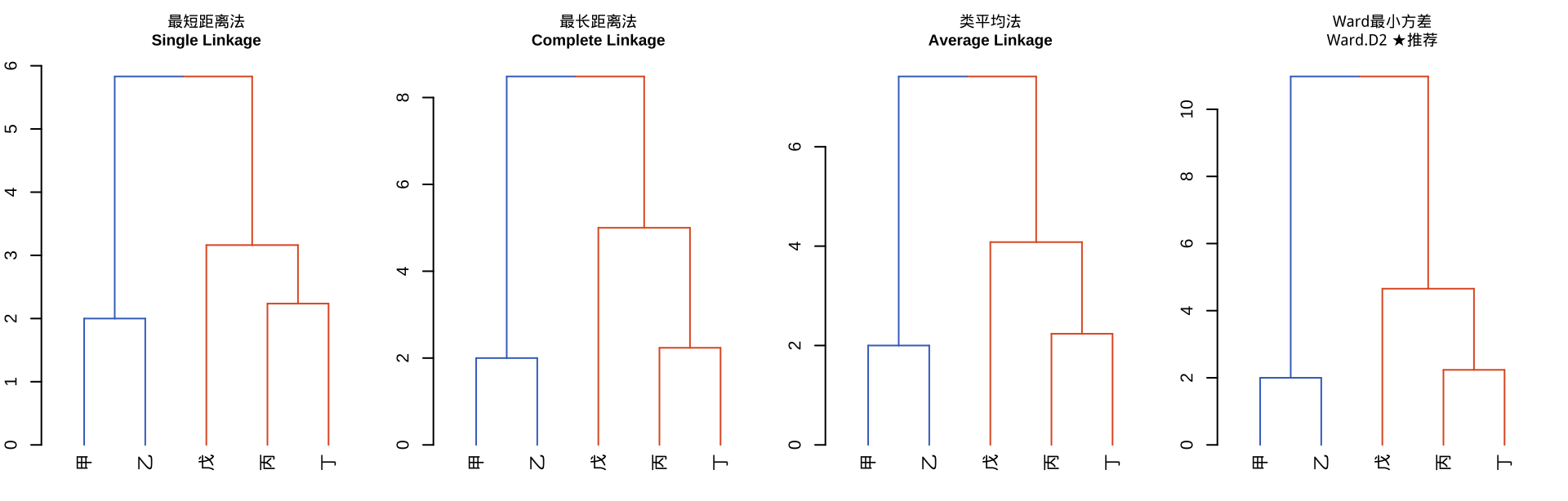
① 每个样本单独成一类(共 5 类)→ ② 找距离最近的两类合并 →
③ 重新计算距离 → ④ 重复直到合并为 1 类 → ⑤ 记录全程,画出谱系图
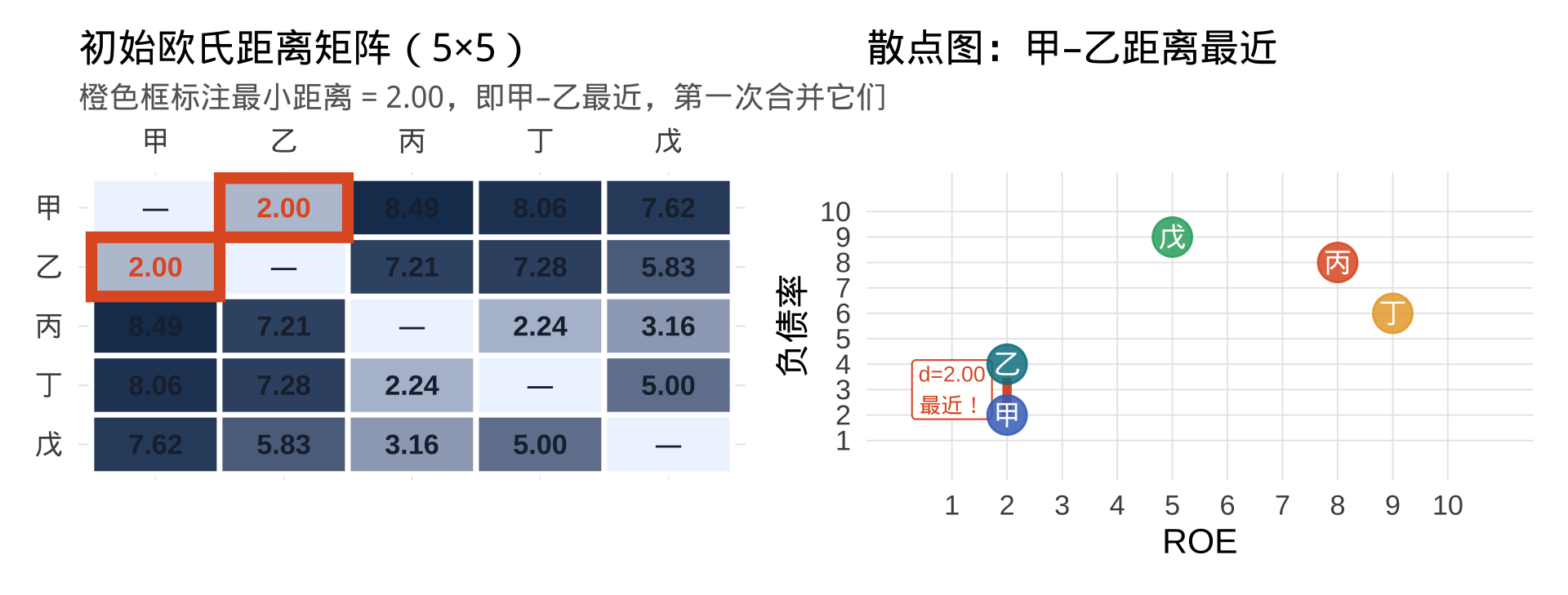
第 1 步:计算初始距离矩阵(5 类,各自独立)
当前状态:甲、乙、丙、丁、戊各自独立,共 5 类
重要
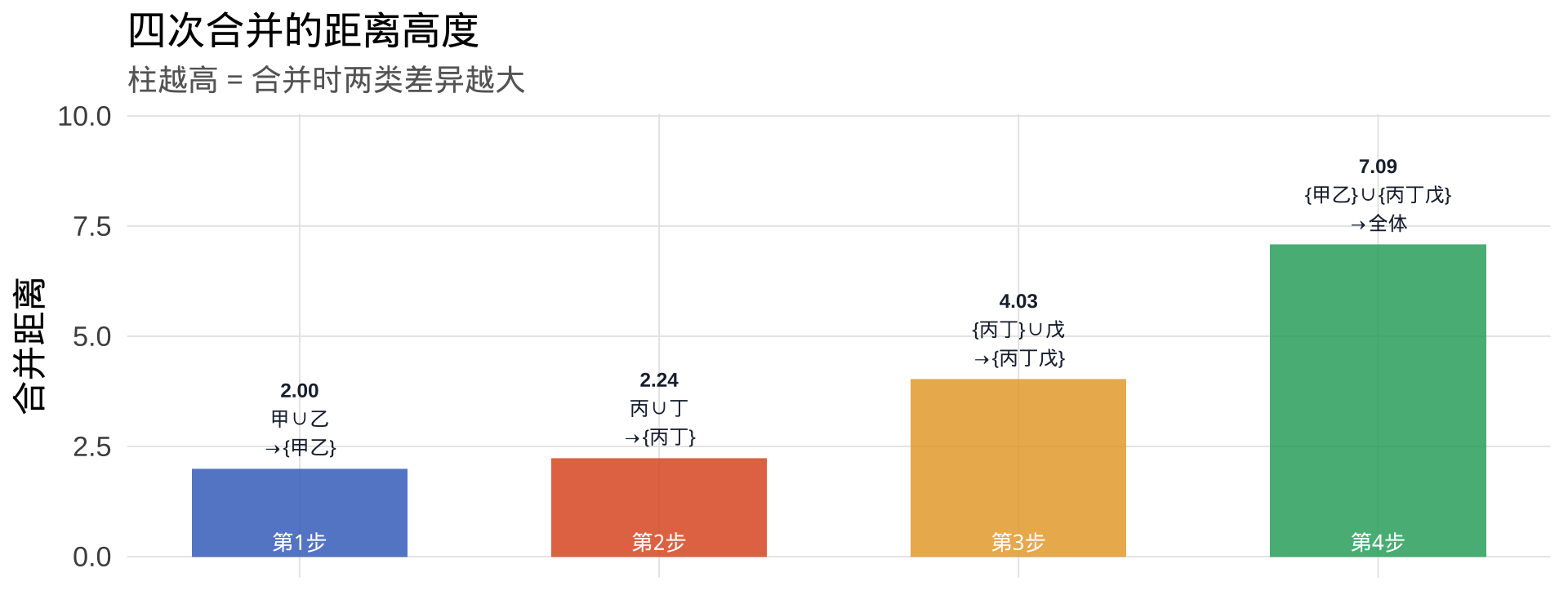
结论:甲(2,2)与乙(2,4)的欧氏距离 = \(\sqrt{(2-2)^2+(2-4)^2}=\sqrt{4}=2.00\),为最小距离。
→ 第一次合并:甲 ∪ 乙 → 新类 {甲乙}
注意:除了欧氏距离,还有曼哈顿距离、切比雪夫距离等计算距离的方法。同一数据集,用不同距离,聚类结果可能不同。
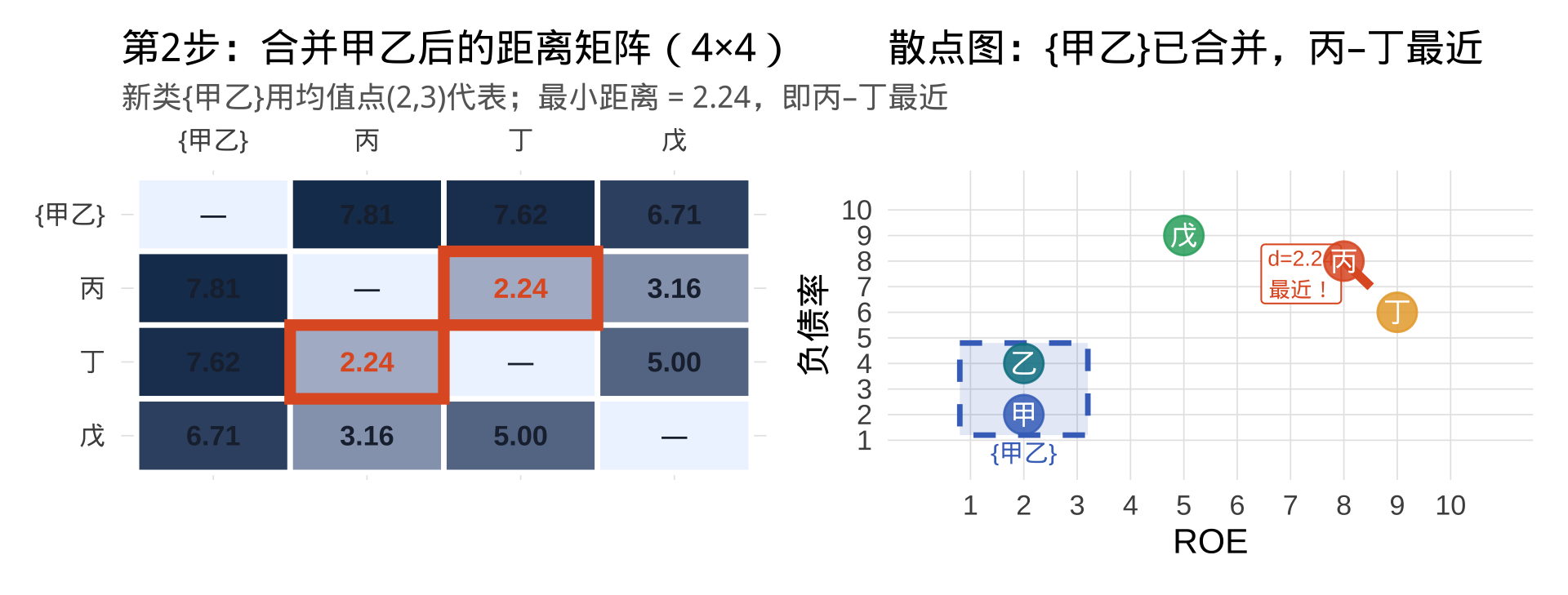
第 2 步:合并甲乙,重新计算距离(现有 4 类)
当前状态:{甲乙}、丙、丁、戊,共 4 类
重要
丙(8,8)与丁(9,6):\(\sqrt{(8-9)^2+(8-6)^2}=\sqrt{1+4}=\sqrt{5}\approx2.24\),为最小距离。
→ 第二次合并:丙 ∪ 丁 → 新类 {丙丁}
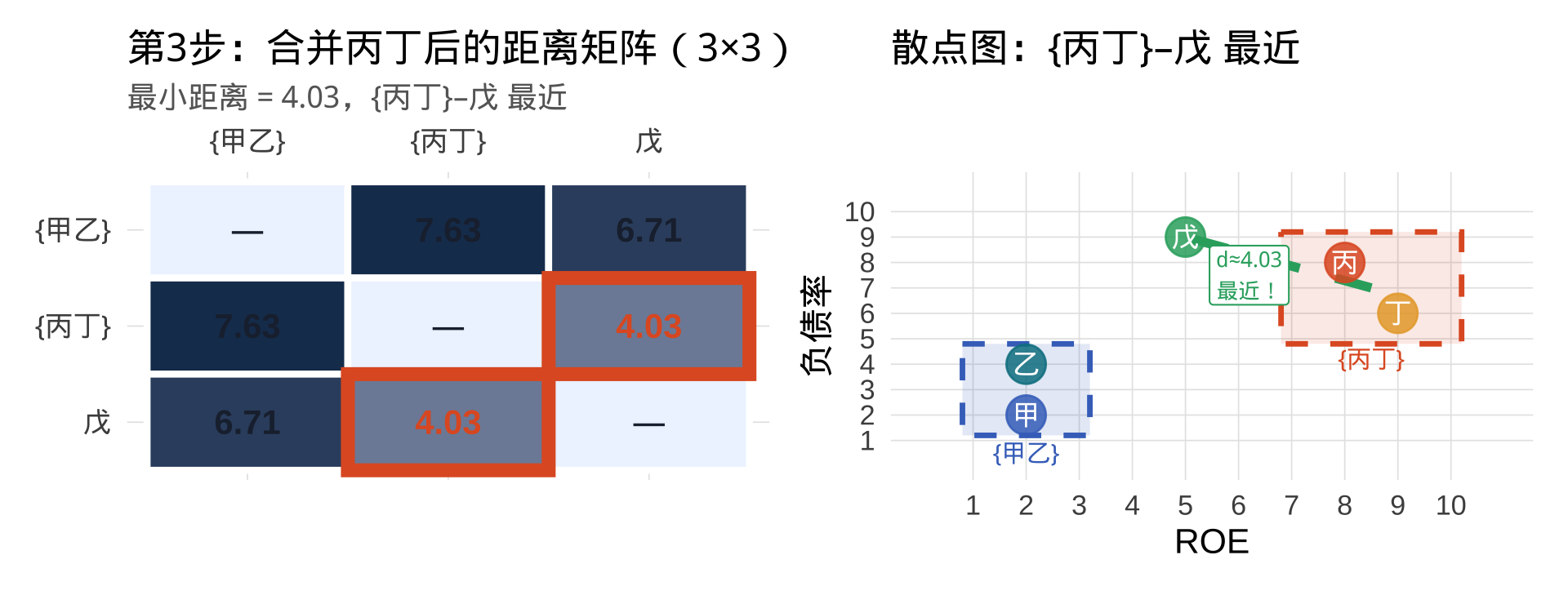
第 3 步:合并丙丁,重新计算距离(现有 3 类)
当前状态:{甲乙}、{丙丁}、戊,共 3 类
类间距离有多种计算方式,影响谱系图形态:
| 方法 | 类间距离定义 | 特点 |
|---|---|---|
| Single | 两类最近样本对的距离 | 易产生链式效应,类松散 |
| Complete | 两类最远样本对的距离 | 类紧凑,对离群点敏感 |
| Average | 所有样本对的平均距离 | 折中,效果稳定 |
| Centroid | 两类重心(均值点)之间的距离 | 代表类中心,但可能出现“反转”现象 |
| Ward.D2 ★ | 合并后类内方差增量最小 | 类最规整,财务分析首选 |
重要
{丙丁}均值点(8.5, 7) 与 戊(5, 9):\(\sqrt{(8.5-5)^2+(7-9)^2}=\sqrt{12.25+4}=\sqrt{16.25}\approx4.03\),最小。
→ 第三次合并:{丙丁} ∪ 戊 → 新类 {丙丁戊}
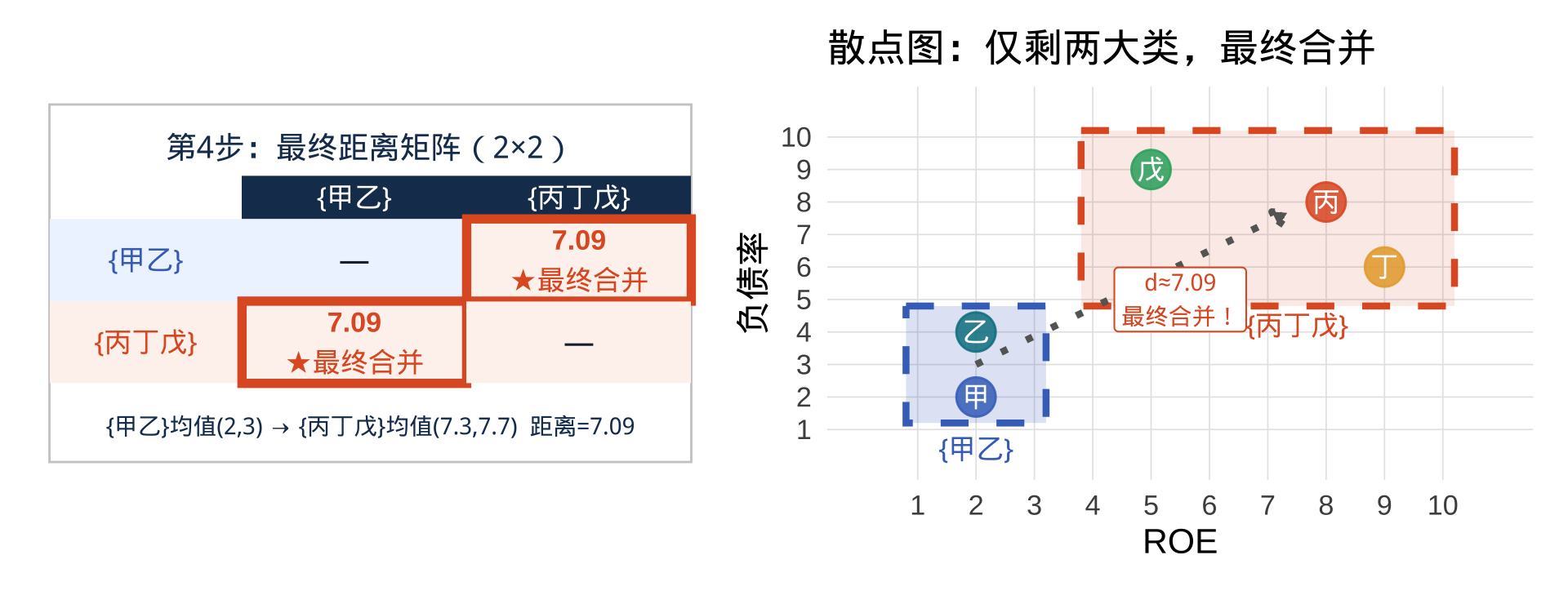
第 4 步:合并丙丁戊,重新计算距离(现有 2 类)
当前状态:{甲乙}、{丙丁戊},共 2 类
重要
{甲乙}均值点(2,3) 与 {丙丁戊}均值点(7.3, 7.7):距离 ≈ 7.09,为最终合并。
→ 第四次合并:{甲乙} ∪ {丙丁戊} → 全体 {甲乙丙丁戊},算法结束!
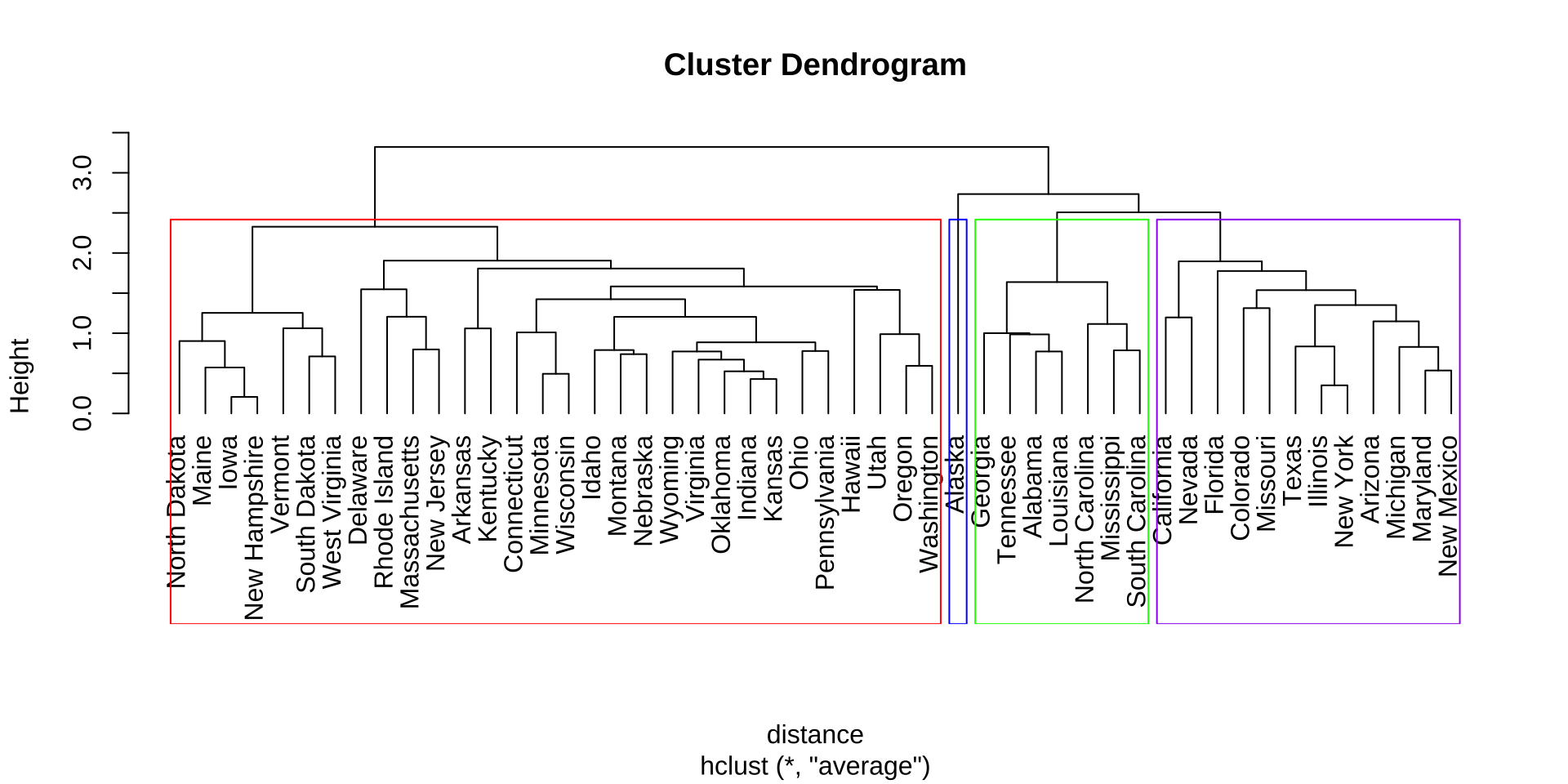
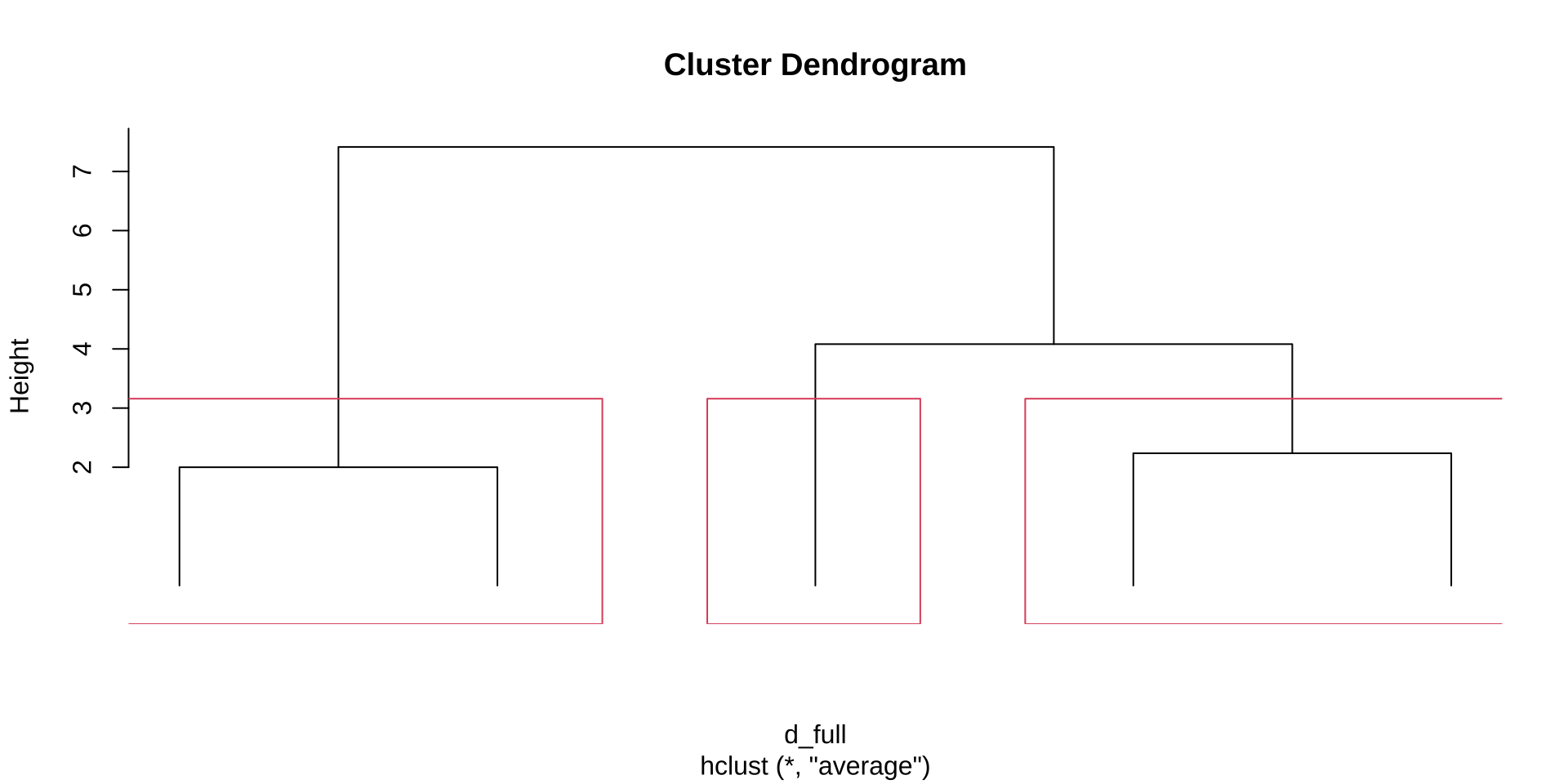
第 5 步:完整谱系图——读懂聚类的全部历史
所有合并步骤都记录在谱系图中,一图尽览!
提示
如何用谱系图决定分组数? 找"最长竖线"——即高度跳跃最大的合并步骤,在其下方画一条水平切割线。本例最大跳跃在第4步(距离从 4.03 跳到 7.1),故切为 k=2 是自然选择:{甲乙} 与 {丙丁戊} 两组。
合并算法(Linkage)的选择
核心代码:四步走(以 iris 为例)
用R内置数据集,走完完整分析流程
数据集: R 内置 iris(鸢尾花数据集,Fisher 1936)
| 变量 | 中文名 | 单位 |
|---|---|---|
Sepal.Length |
萼片长度 | cm |
Sepal.Width |
萼片宽度 | cm |
Petal.Length |
花瓣长度 | cm |
Petal.Width |
花瓣宽度 | cm |
共 150 个样本,3 个物种(setosa / versicolor / virginica)各 50 个。
实训中不使用Species列——聚类完成后再用它验证结果。
▶️ 查看代码
# ── Step 1:载入数据,取数值列(不含 Species 标签)──────────
data(iris)
iris_num <- iris[, 1:4] # Sepal.Length, Sepal.Width,
# Petal.Length, Petal.Width
# ── Step 2:标准化(必须!四列量纲相近但仍建议标准化)───────
iris_scaled <- scale(iris_num)
# ── Step 3:计算欧氏距离矩阵 ─────────────────────────────────
distance <- dist(iris_scaled, method = "euclidean")#默认"euclidean",可不选
# ── Step 4:执行层次聚类(平均距离法)───────────────
fit <- hclust(distance, method = "average")
# ── Step 5:绘制基础谱系图 ───────────────────────────────────
plot(fit, hang = -1, cex = 0.55, labels = FALSE,
main = "iris 层次聚类谱系图(Average)",
xlab = "", sub = "", ylab = "距离")
# ── Step 6:切分,获取分组标签 ───────────────────────────────
groups <- cutree(fit, k = 3)
table(groups) # 各组样本数
# ── Step 7:与真实物种标签对比(验证聚类质量)───────────────
table(聚类结果 = groups, 真实物种 = iris$Species)▶️ 查看代码
注记
选择 k 的方法:
① 目视法:观察谱系图,找高度跳跃最大的合并步骤
② 轮廓系数:cluster::silhouette(groups, d),值越接近 1 越好
③ 先验知识:iris 已知共 3 个物种,可直接验证 k=3 的效果
谱系图演示(iris 150 个样本)
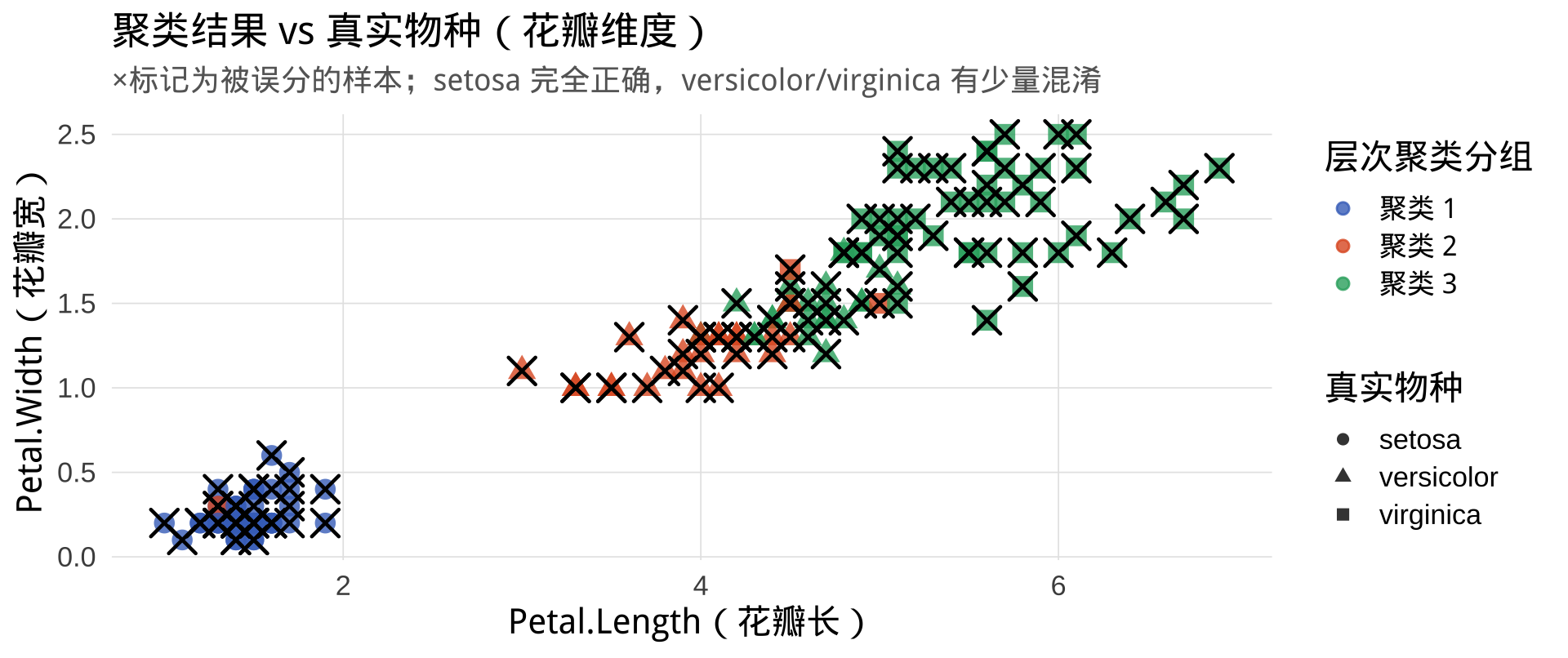
groups_iris
1 2 3
49 30 71 | setosa | versicolor | virginica |
|---|---|---|
| 49 | 0 | 0 |
| 1 | 27 | 2 |
| 0 | 23 | 48 |
提示
解读: setosa(组1)被完美分离;versicolor 与 virginica 花瓣特征有重叠,共约 26 个样本被误分,整体准确率约 82.7%——这正是层次聚类在真实数据上的典型表现。
警告
常见错误清单:
| 错误 | 正确做法 |
|---|---|
把 Species 列也放进聚类 |
聚类只用数值列;标签列用于事后验证 |
忘记 scale()
|
标准化消除量纲影响,即使单位相同也推荐执行 |
| 把聚类当分类,算"准确率" | 聚类无标签,用轮廓系数或混淆矩阵事后对比 |
| k 值随意设定 | 结合谱系图断裂点 + 先验知识(如已知 3 个物种)综合判断 |
按以下步骤进行层次聚类建模:
变量进行标准化处理
计算欧氏距离矩阵
使用平均链法(average linkage)进行层次聚类
画聚类树图
用cutree()函数将类别数划为3类
用table()函数查看划为3类时的层次聚类结果
使用rect.hclust()函数叠加4类,重新绘制树状图。
▶️ 查看代码