▶️ 查看代码
1 2 3
2 500.00
3 10.05 499.08
4 801.09 301.20 800.00第19讲:层次聚类(二)——标准化、聚类画像与实战
2026年06月03日
聚类的终点不是数字,而是能够"说出来"的群体故事
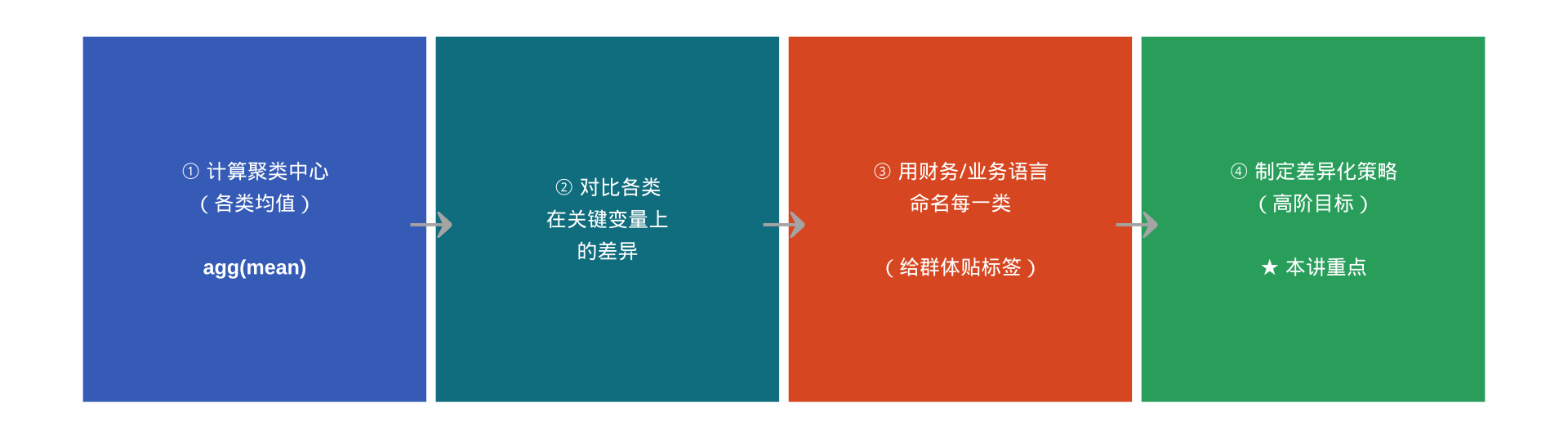
三步聚类画像法:
提示
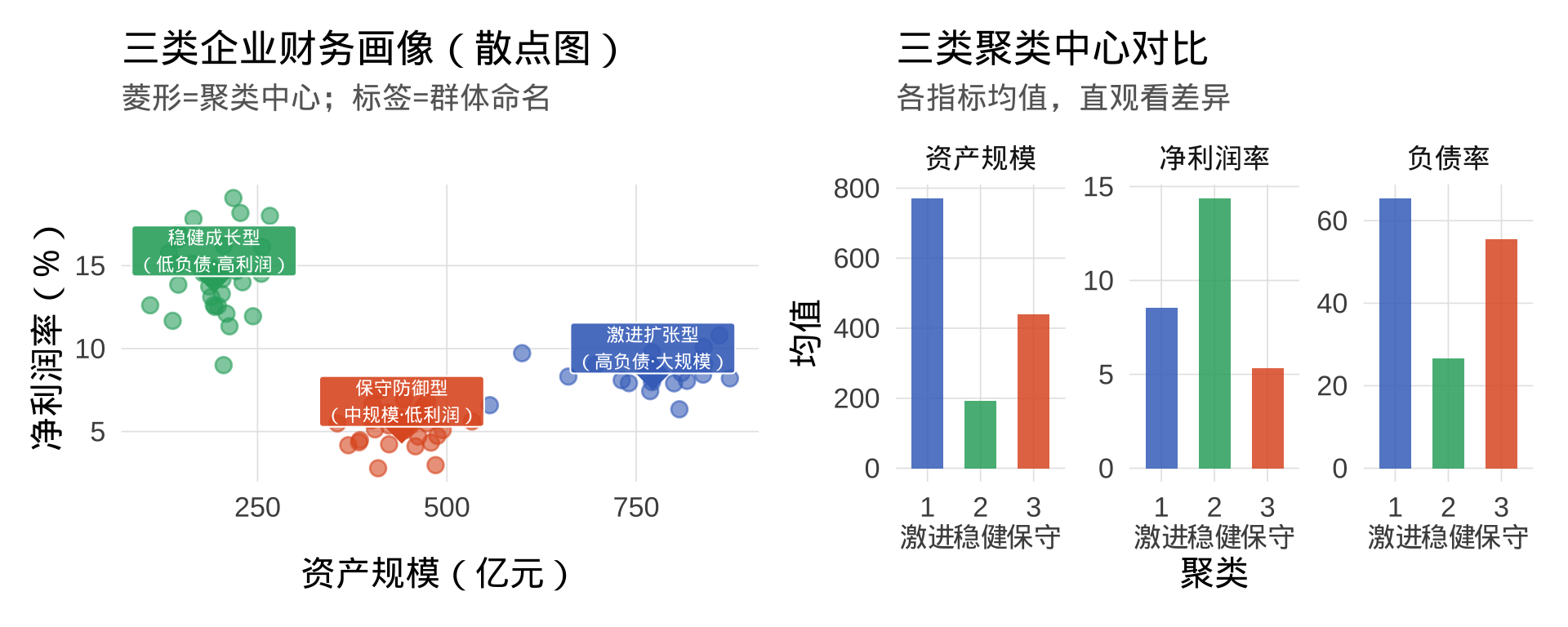
聚类命名示例:
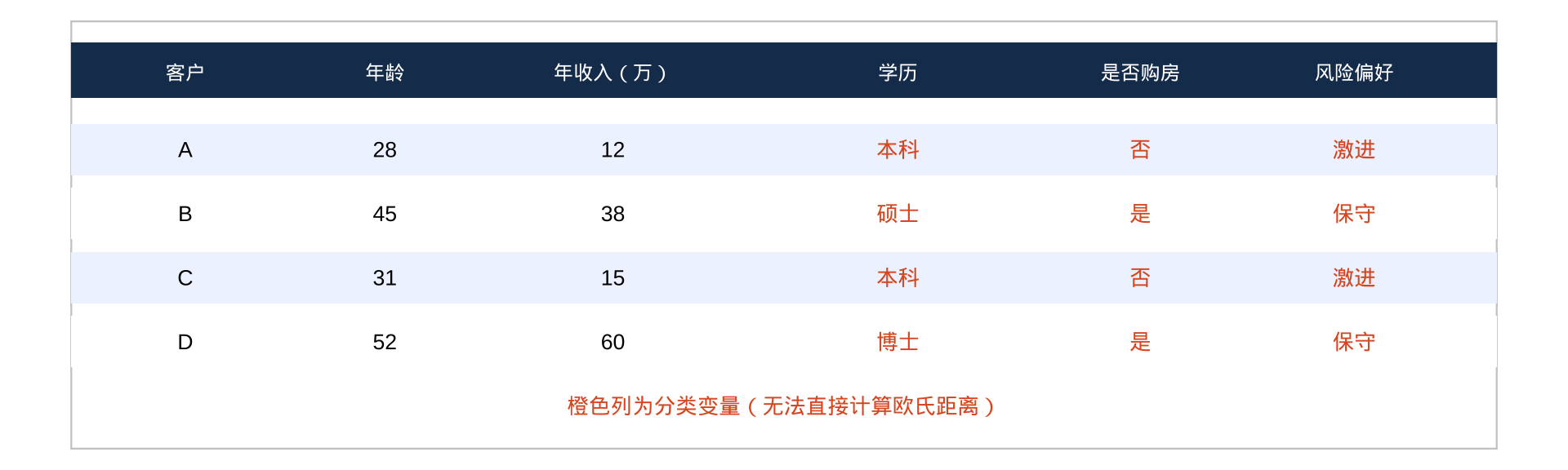
现实数据往往是"混合型"的
注记
前两列(年龄、年收入)是数值型,可直接计算欧氏距离;后三列(学历、是否购房、风险偏好)是分类型,不能直接计算距离。混合数据需要专门的距离方法。

重要
常见误区:对分类变量强行使用数值编码(如将学历编为 1/2/3),隐含了"博士与本科的距离是硕士与本科的两倍"这样的假设。若没有明确理由支持这种等距假设,应使用 ordered factor 配合 daisy(),让算法按秩归一化处理。
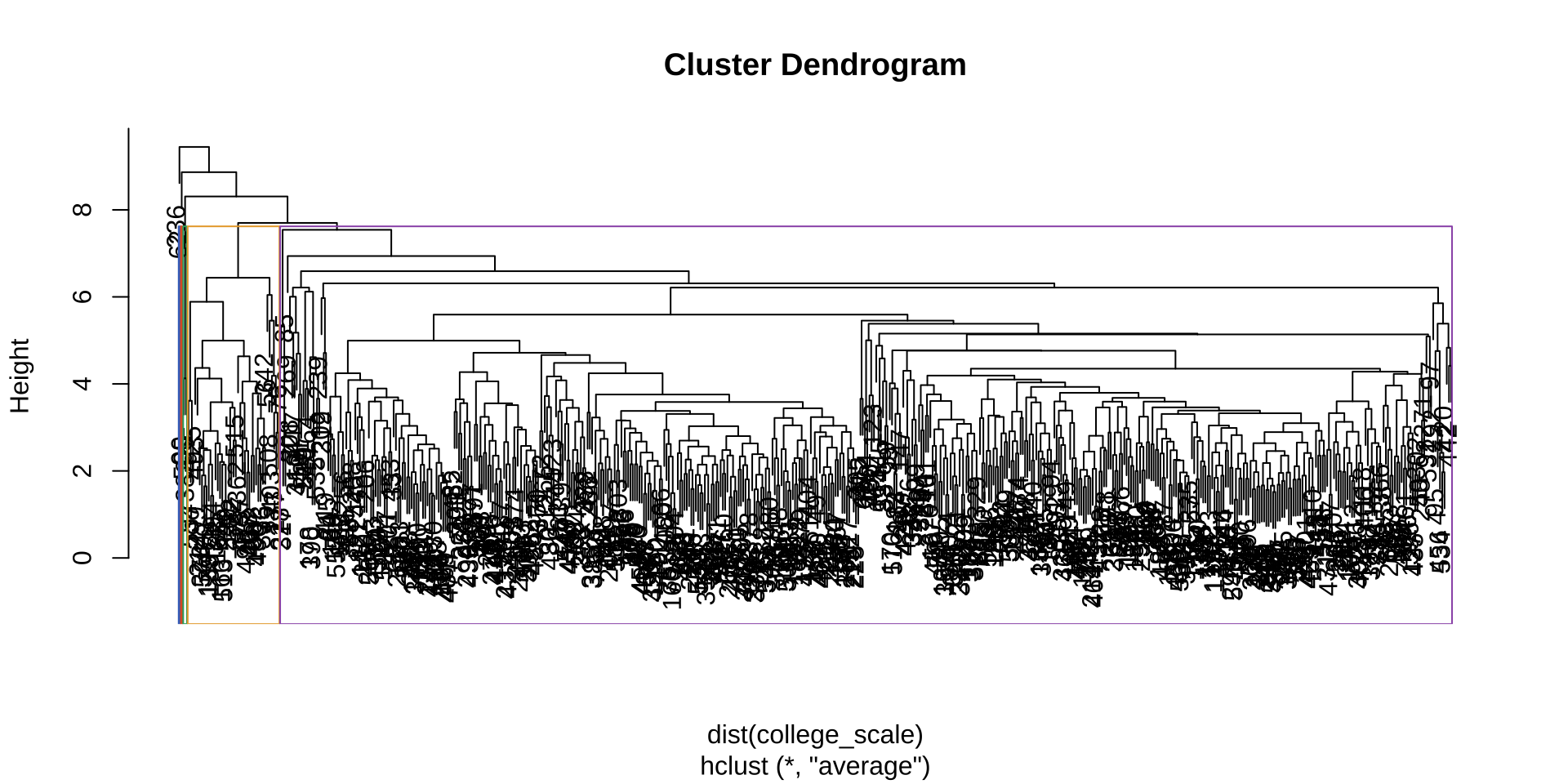
对标准化数据做层次聚类(平均链接法),画谱系图。

注记
谱系图分析:观察纵轴高度的"大跳跃"位置——两个相邻合并步骤之间距离差最大处,是确定 k 值的参考依据。本数据集高度跳跃约在 6–8 之间,提示可考虑 k=4 或 k=5。
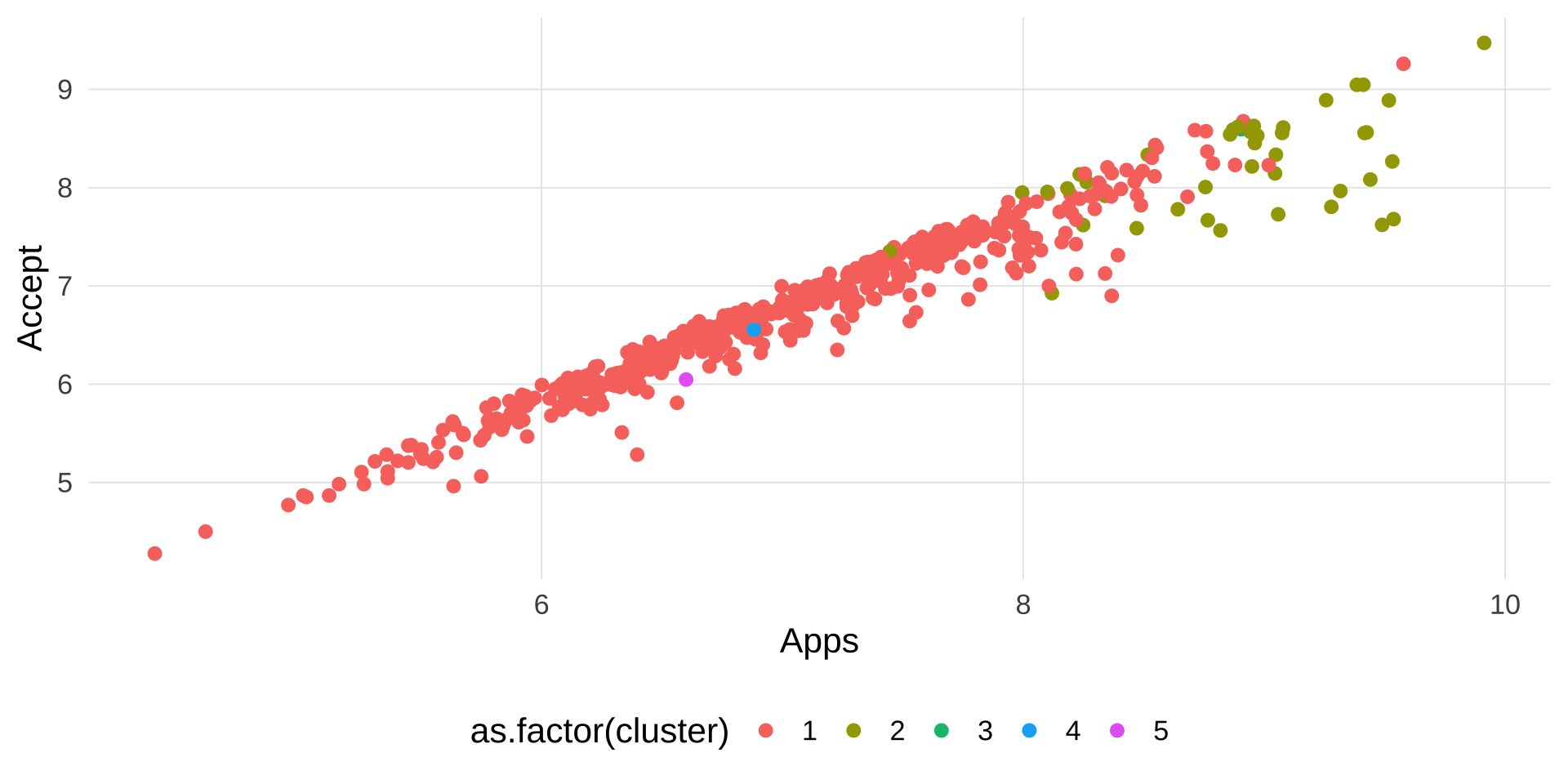
注记
图形分析:

提示
高阶思考:聚类不是终点,画像与策略才是。在实际项目中,对每一类群体,都应能回答:"这类客户/学校/企业的核心特征是什么?对应的管理/经营/投资策略应该如何差异化?"