
第20讲:K均值聚类(K-Means Clustering)
2026年06月05日
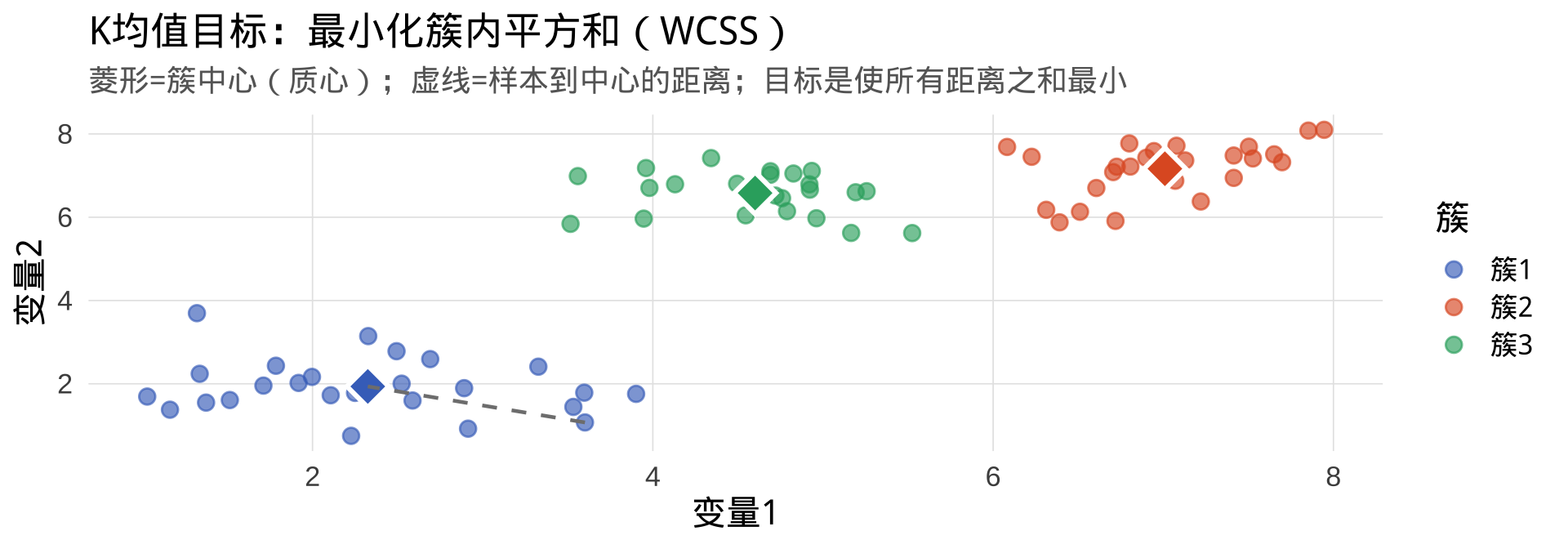
目标:找到 k 个"最优中心点",使每个样本到其所属中心的距离之和最小
注记
WCSS(Within-Cluster Sum of Squares):簇内平方和,是衡量聚类质量的核心指标。WCSS 越小,说明每个簇内的样本越紧凑、越相似。
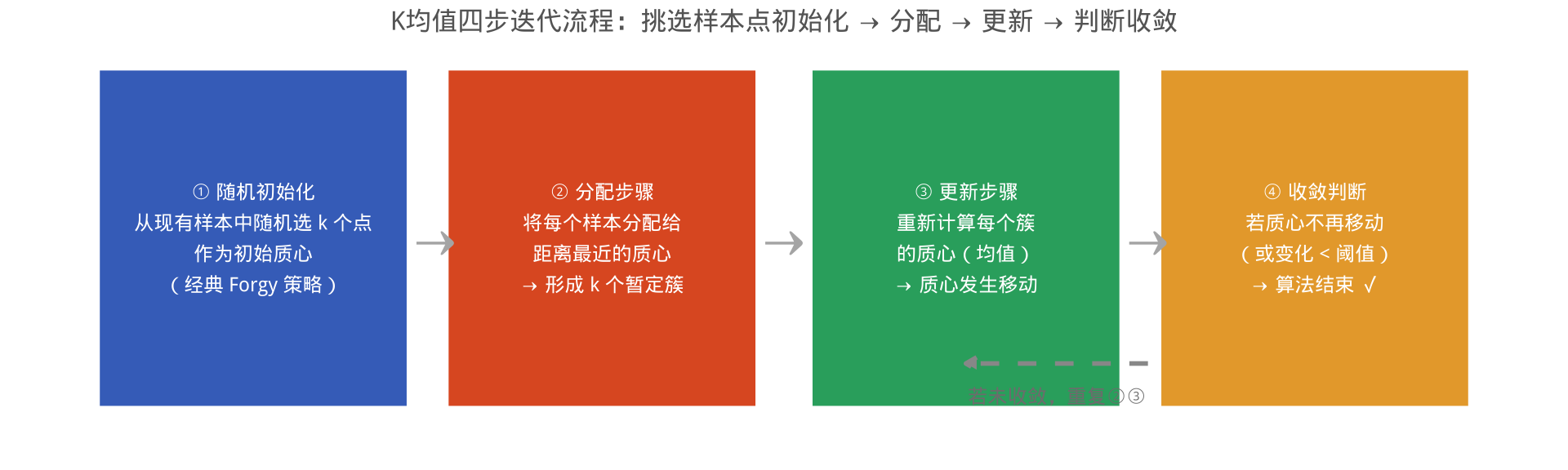
算法核心:反复"分配—更新—再分配",直到中心不再移动
重要
关键数学保证:每次"分配+更新"循环后,WCSS 单调不增——算法一定会收敛,但不一定收敛到全局最优(可能是局部最优)。因此实践中通常运行多次(nstart=25),取WCSS最小的结果。
数据:6个二维点(A–F),目标:用 K均值聚为 2 组
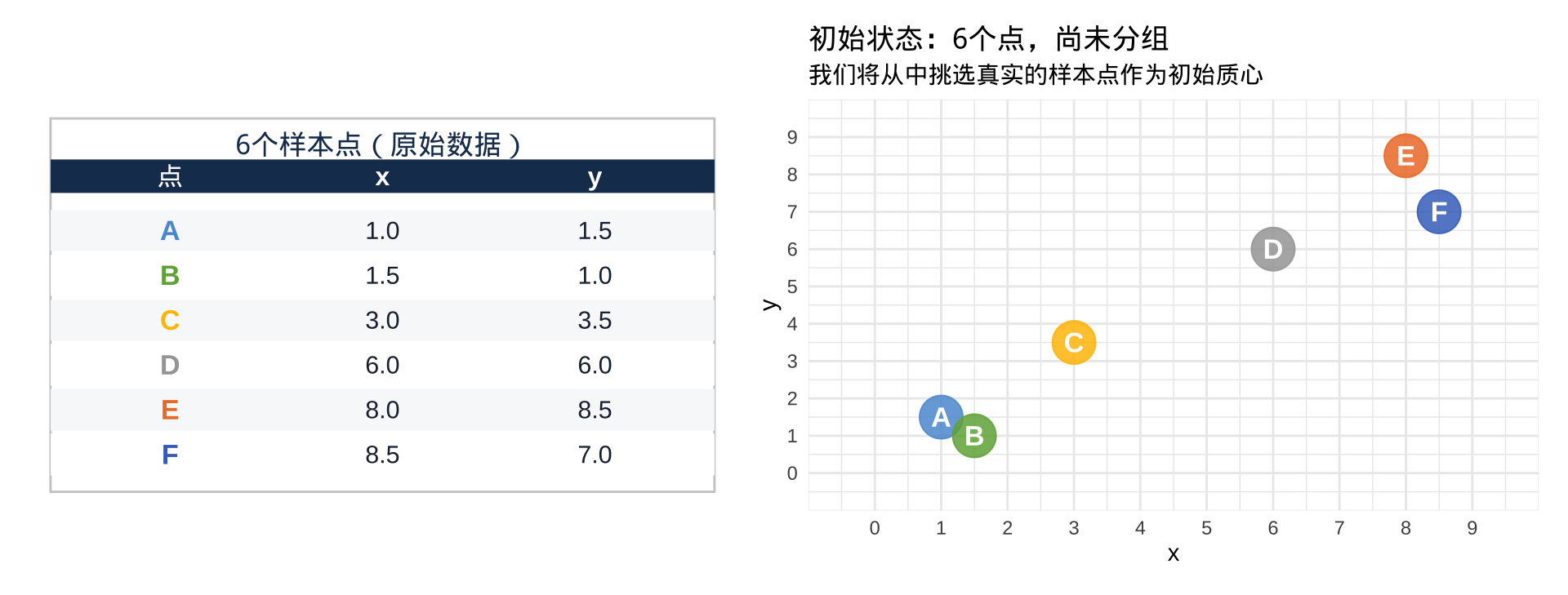
以真实样本 A 和 C 作为初始质心 设定初始质心:μ₁ 选定 A(1.0, 1.5),μ₂ 选定 C(3.0, 3.5)。右侧远端样本因距离原因暂归属于 C
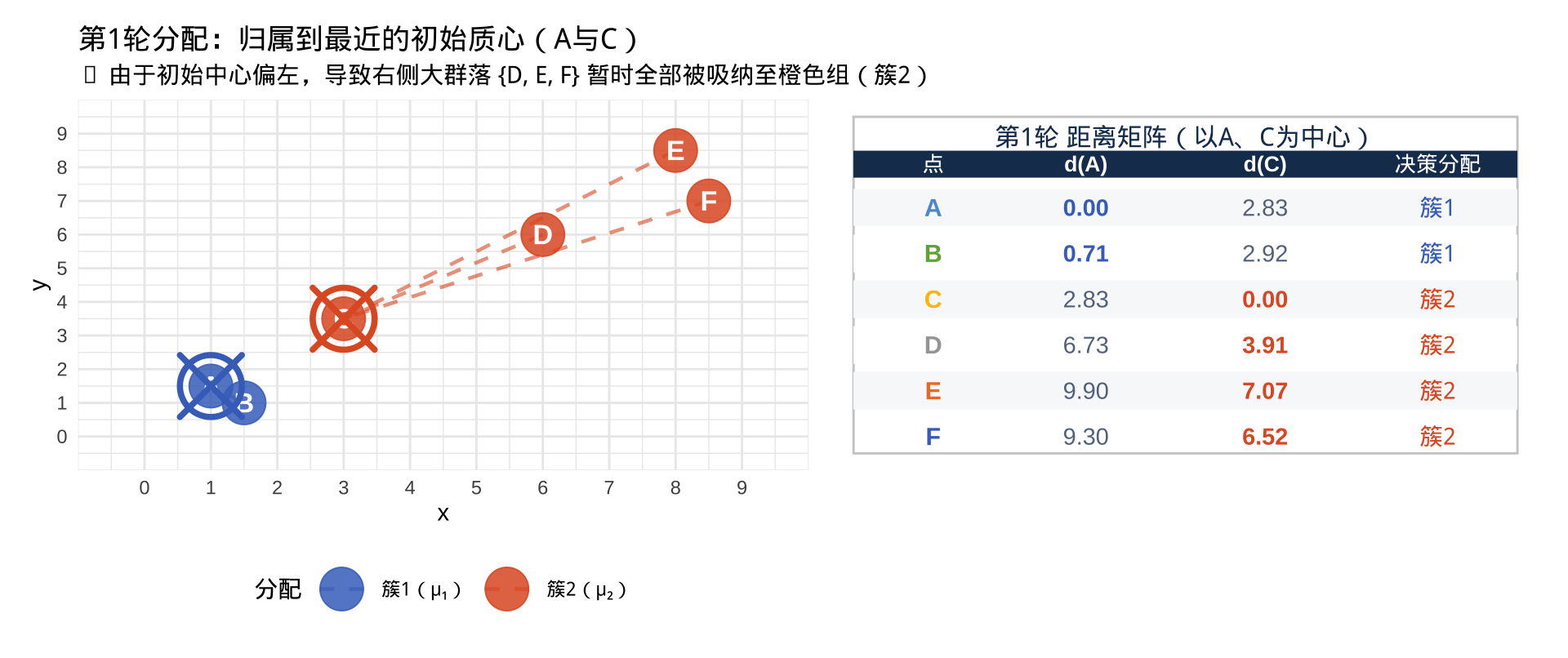
警告
当前临时聚类状态:簇1 = {A, B},簇2 = {C, D, E, F}。由于右侧三个高坐标点的强力拉扯,橙色组的几何中心即将会发生剧烈漂移!
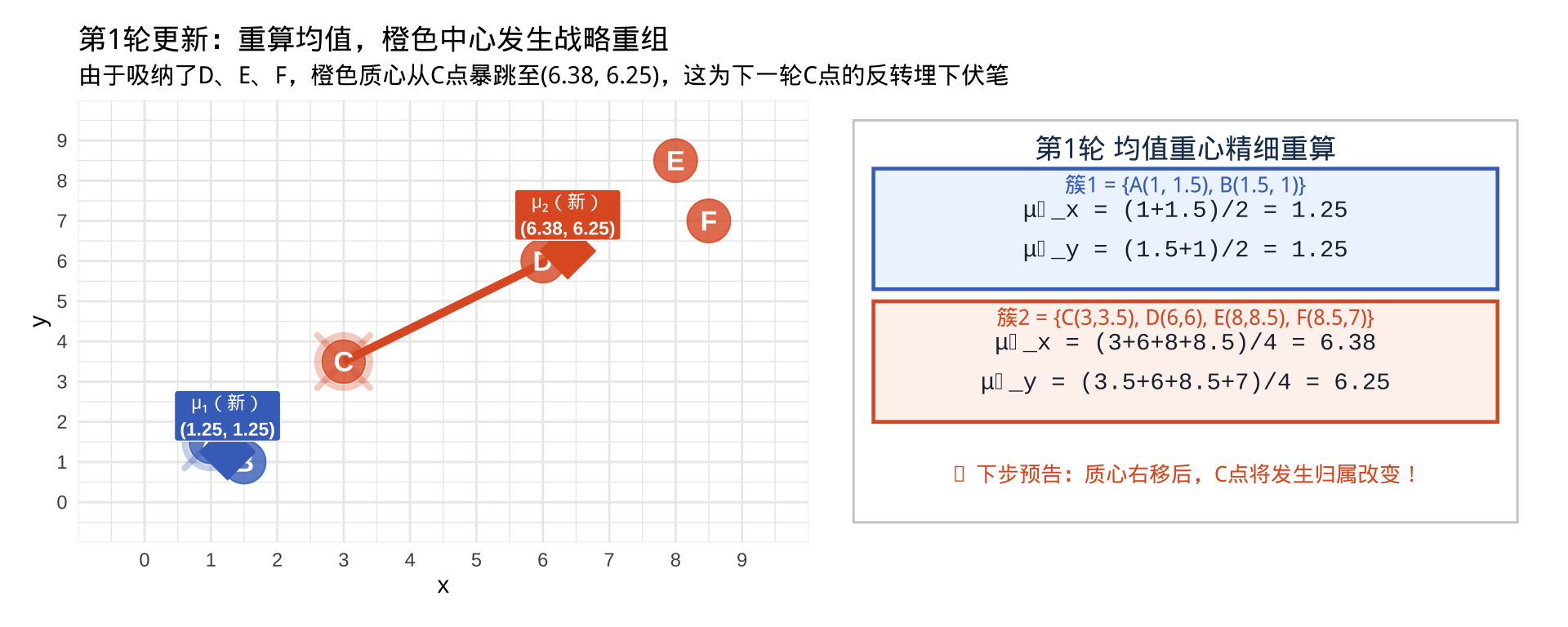
右侧高值引发橙色质心“大漂移”,重新计算两簇的均值坐标,橙色质心被大幅度拉向右上方,与 C 点彻底拉开距离
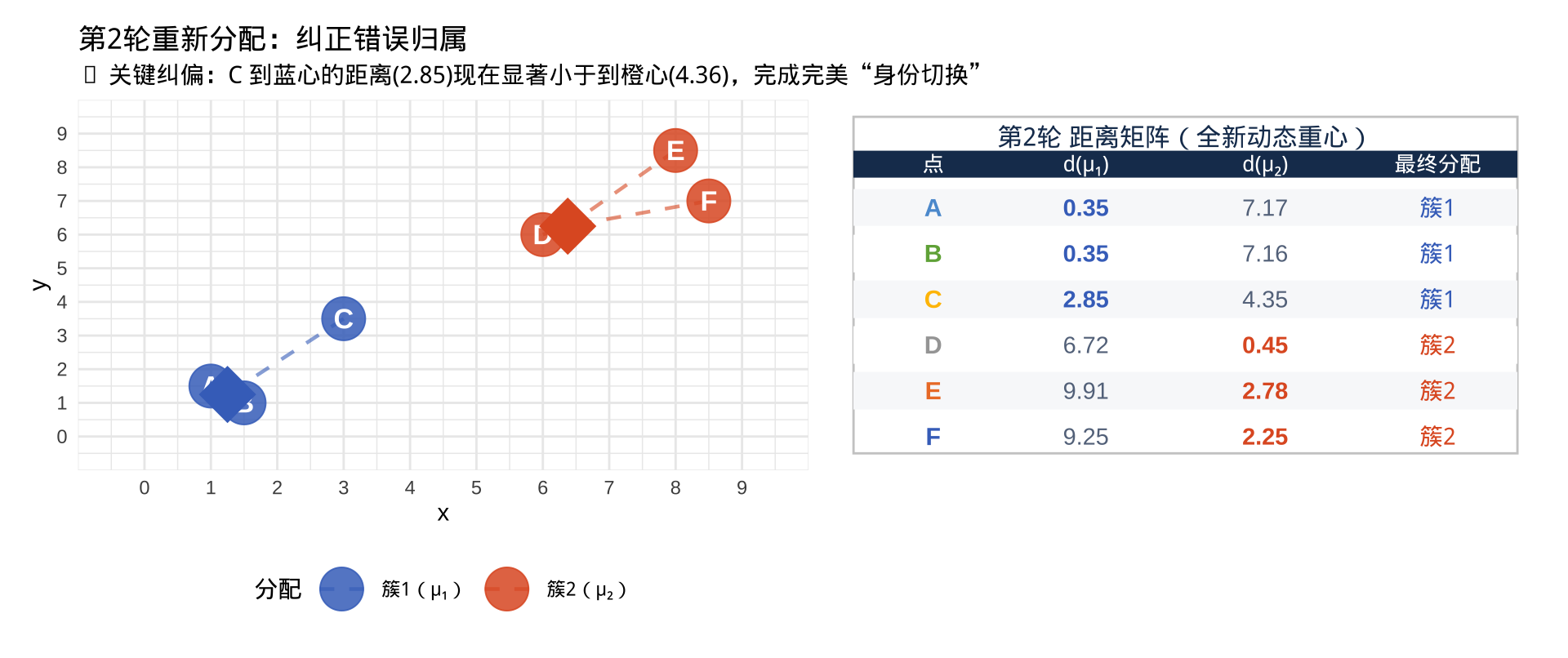
边界样本 C 的“戏剧性反转”,用全新质心重新度量距离:橙色质心离 C 变远了!C 点果断脱离橙色组,重新回归蓝色大家庭!
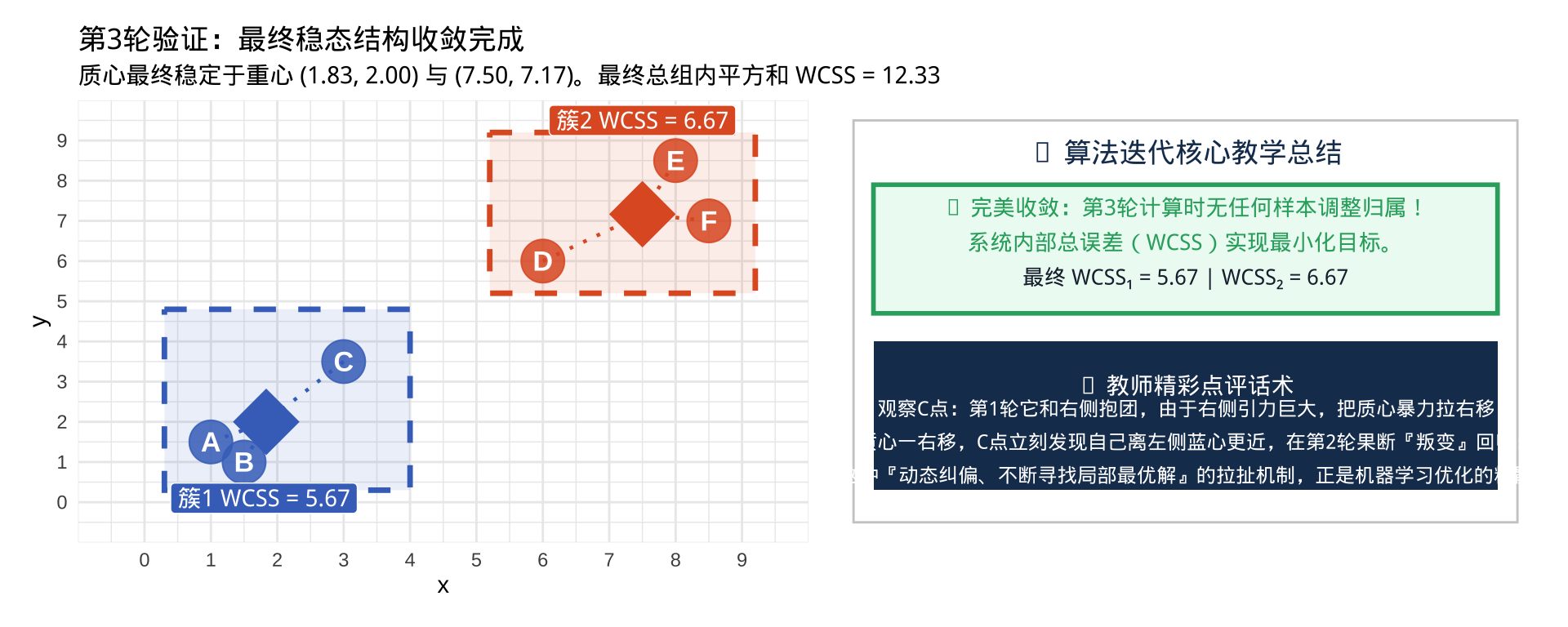
再无成员变动,迭代完美终止。
重要
K均值算法完整回顾:随机初始化 → 分配(1步)→ 更新质心 → 再分配(1步,结果不变)→ 收敛。
本例最终 WCSS = 12.33,两个簇完美分离,聚类效果极佳。
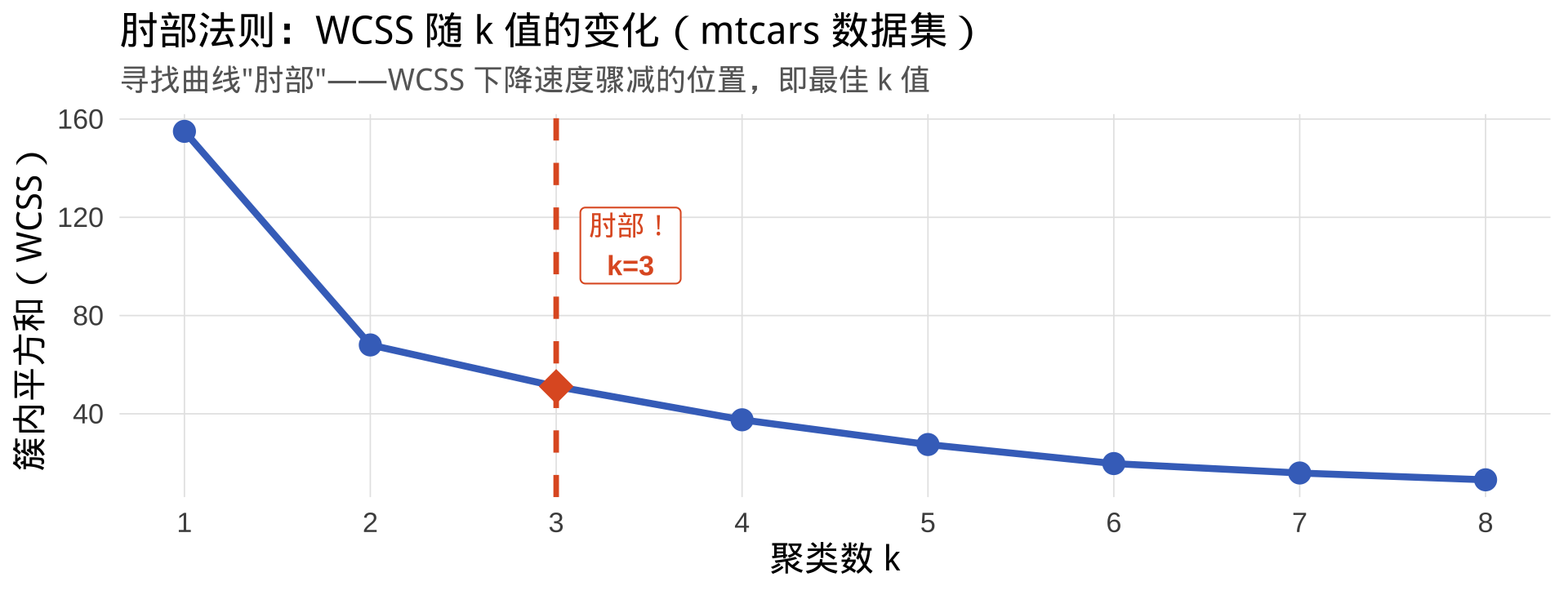
核心思路:k 增大 → WCSS 必然下降;找"下降速度骤减"的拐点

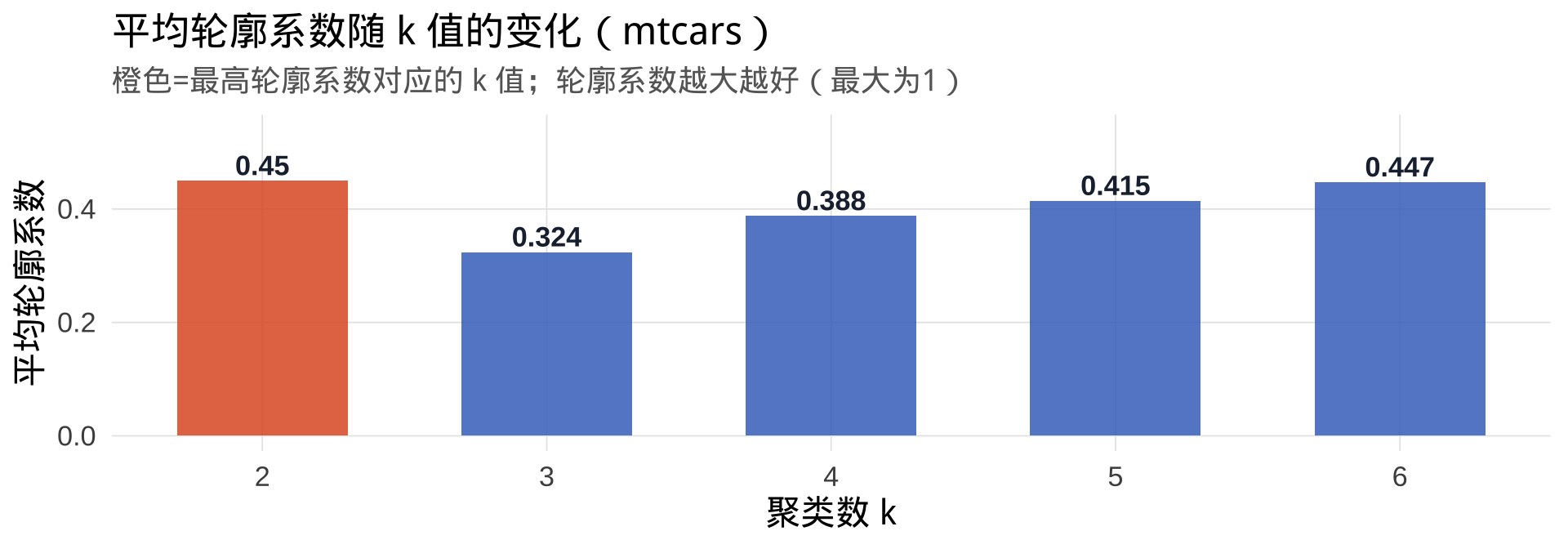
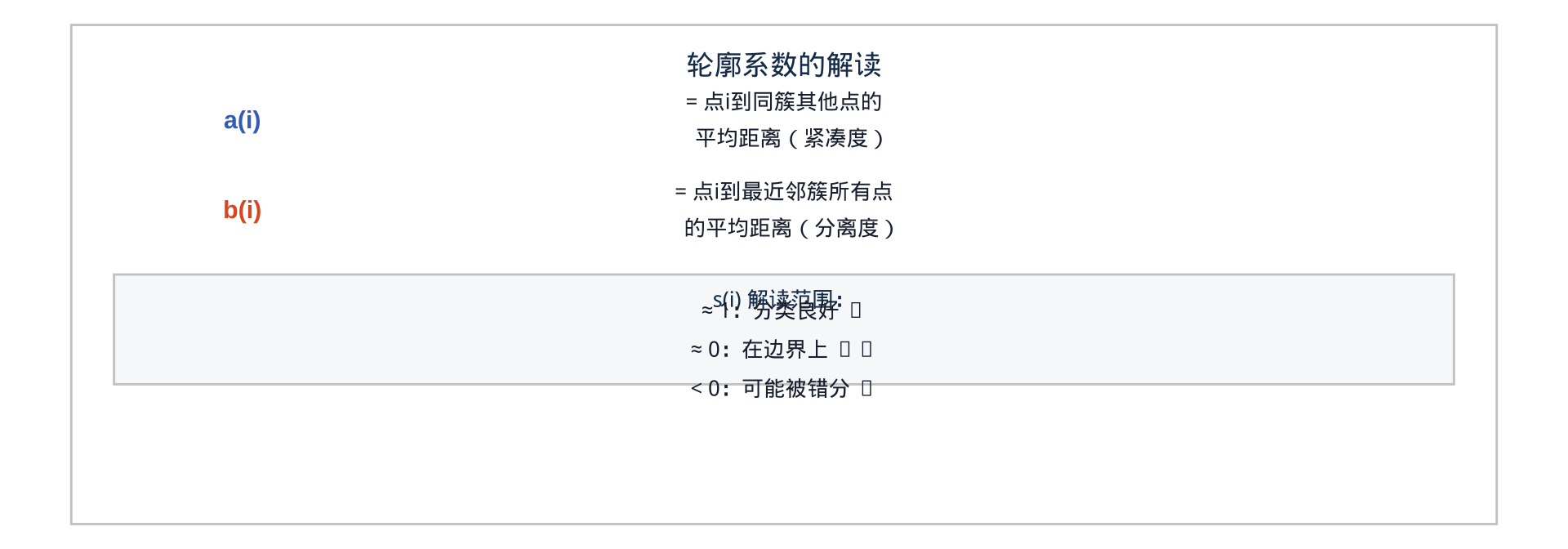
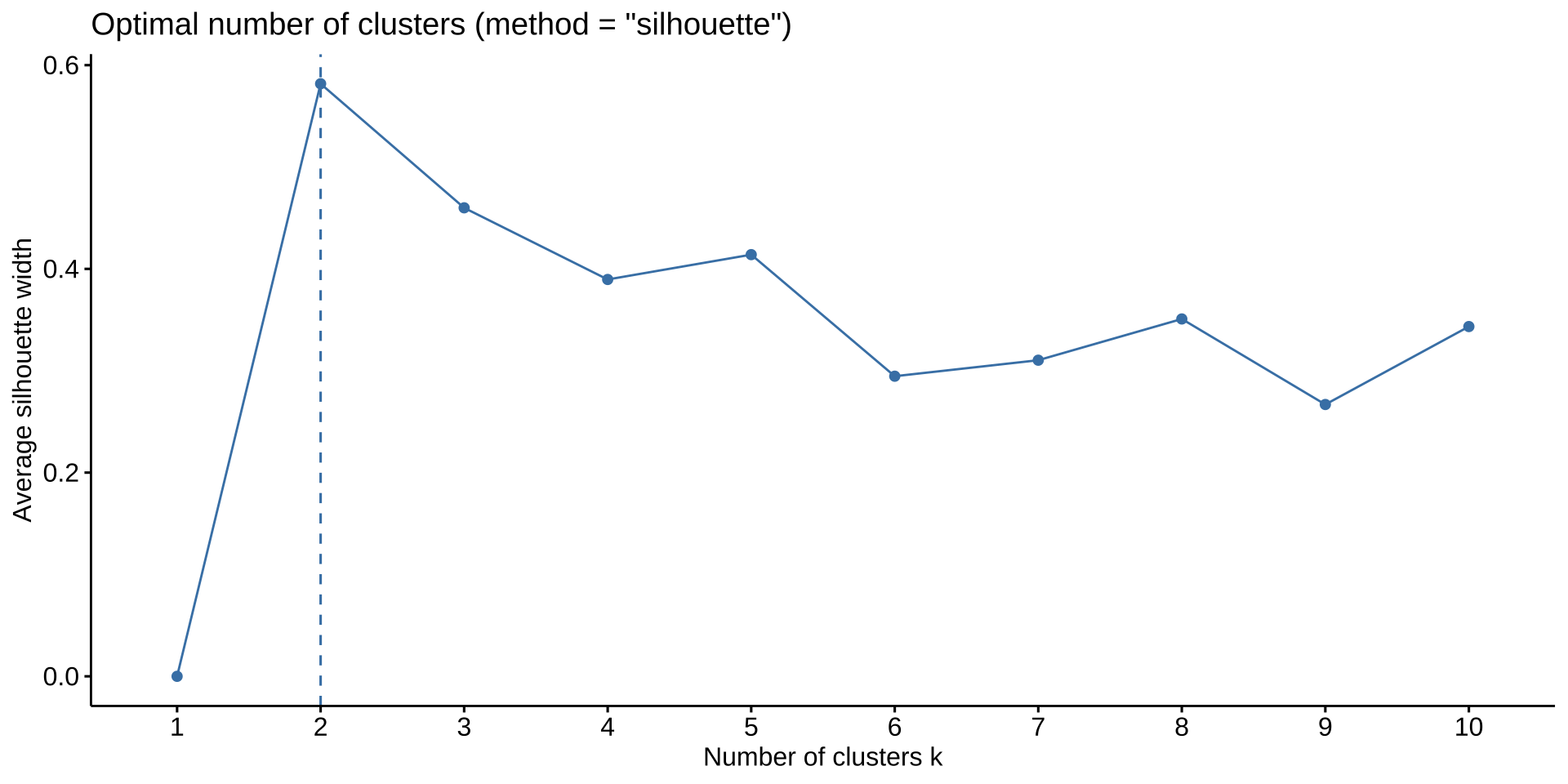
轮廓系数:同时考虑"簇内紧凑度"与"簇间分离度",是更严格的评估指标
\[s(i) = \frac{b(i) - a(i)}{\max\{a(i), b(i)\}}\]
提示
实践建议:同时使用肘部法则(看 WCSS 拐点)和轮廓系数(取最大值对应的 k);若二者结论一致,则该 k 值可信度更高。

提示
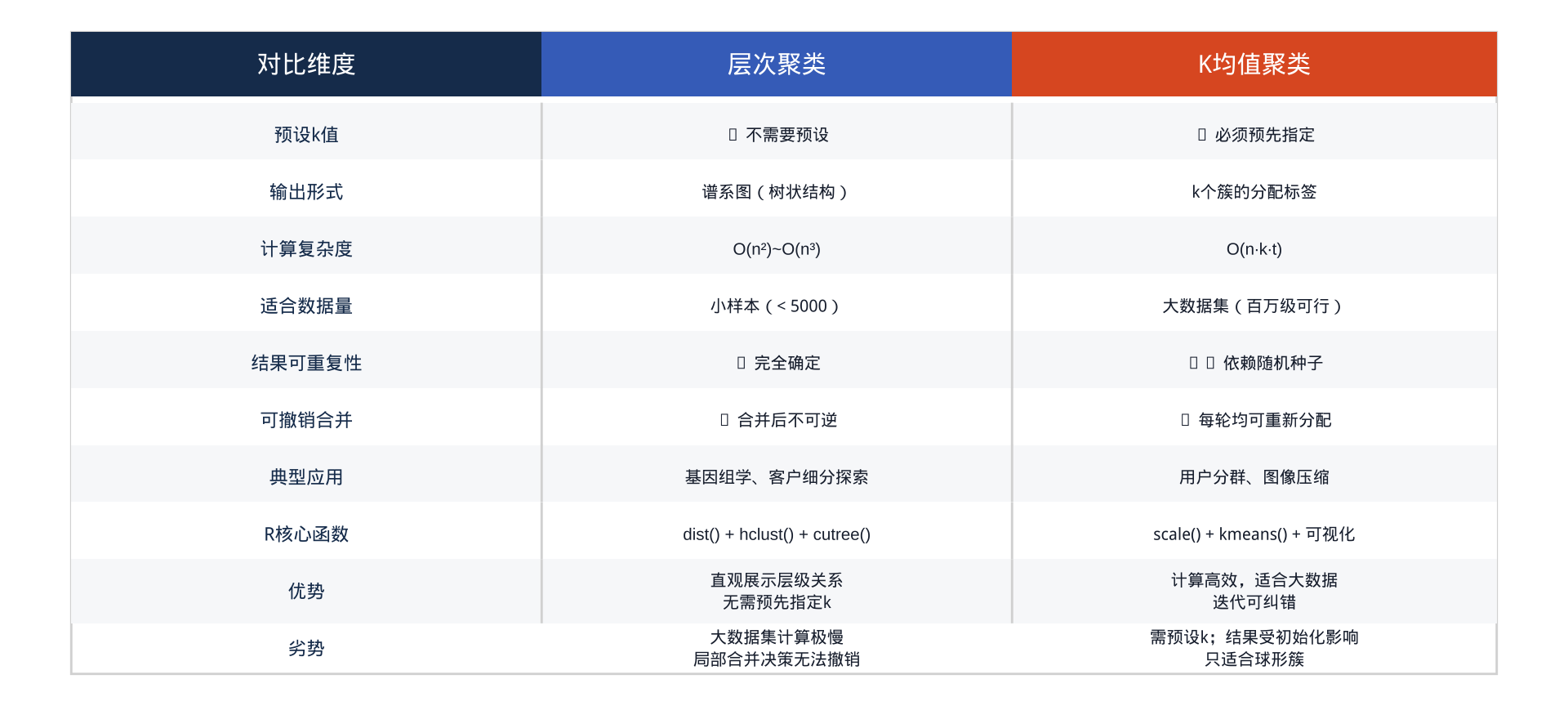
黄金组合:先用层次聚类在小样本上探索最优 k 值(看谱系图),再用K均值在全量数据上高效执行。两步走,兼顾准确性与计算效率。
Sepal.Length Sepal.Width Petal.Length Petal.Width
[1,] -0.8977 1.01560 -1.336 -1.311
[2,] -1.1392 -0.13154 -1.336 -1.311
[3,] -1.3807 0.32732 -1.392 -1.311
[4,] -1.5015 0.09789 -1.279 -1.311
[5,] -1.0184 1.24503 -1.336 -1.311
[6,] -0.5354 1.93331 -1.166 -1.049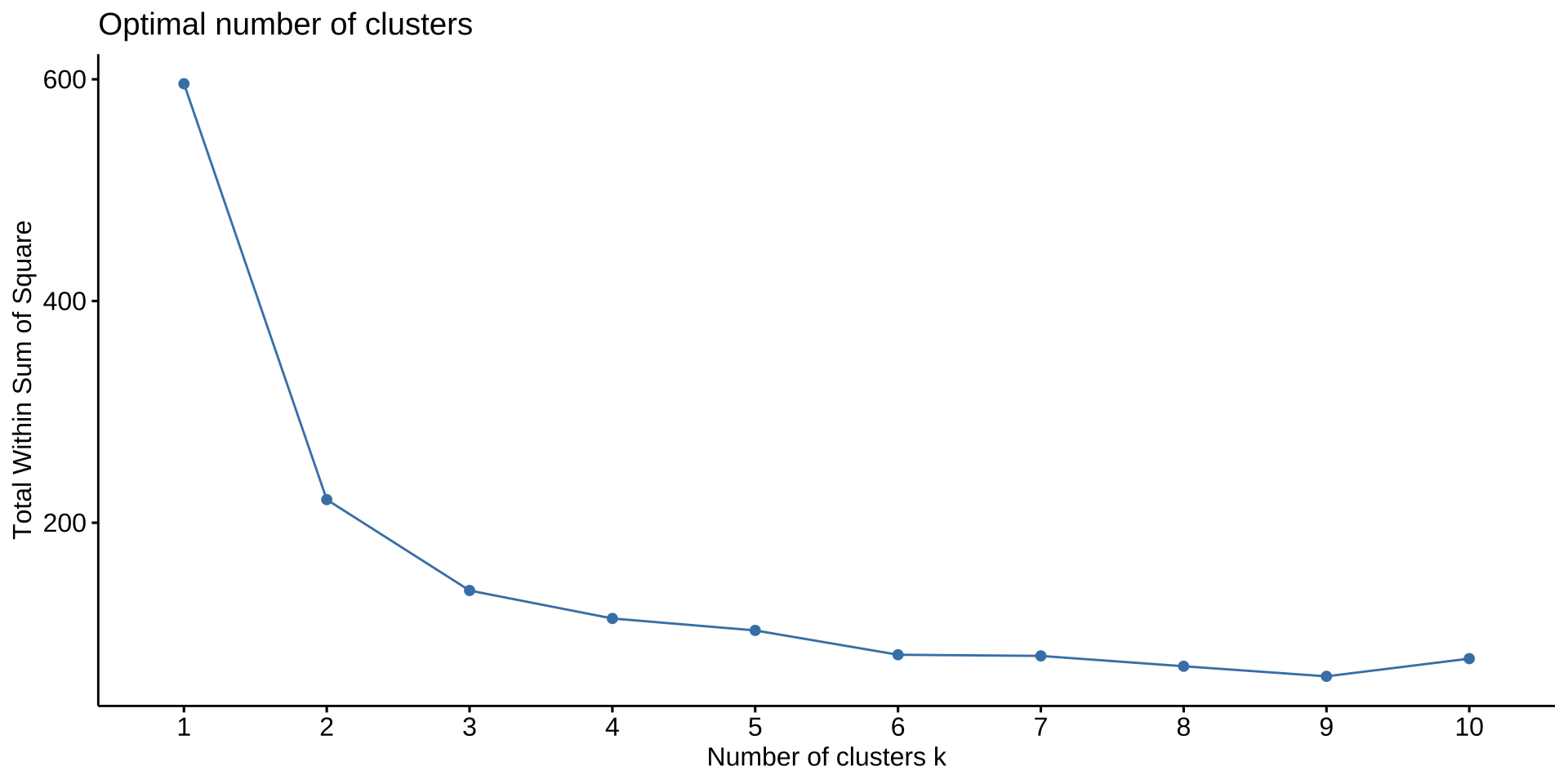
1 2 3
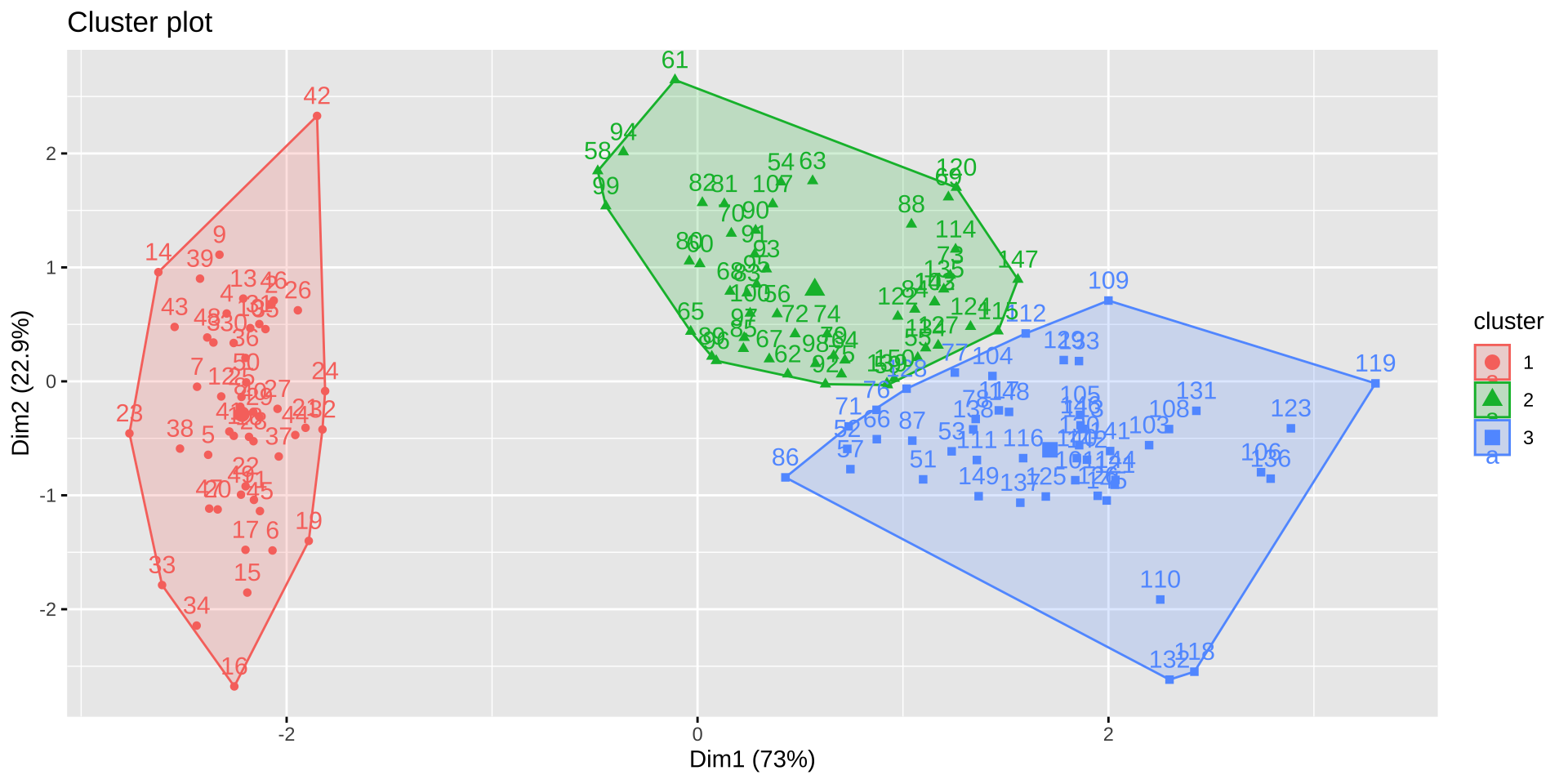
50 53 47 Murder(x轴)和 Assault(y轴)绘制散点图,颜色区分聚类library(ggplot2)
ggplot(arrests_clustered,
aes(x = Murder, y = Assault,
color = factor(cluster), label = rownames(USArrests))) +
geom_point(size = 3) +
geom_text(vjust = -0.6, size = 2.5) +
scale_color_manual(values = c("#4472C4","#e05c2a","#2eab6e"),
name = "聚类") +
labs(title = "美国各州犯罪率 K 均值聚类(k=3)",
x = "谋杀率(Murder)", y = "袭击率(Assault)")