
数据挖掘与R语言
第21讲:关联规则与Apriori算法
2026年06月10日
上讲回顾
- K均值目标:最小化 WCSS(簇内平方和);算法保证单调收敛,但可能陷入局部最优
-
四步迭代:随机初始化 → 分配(最近质心)→ 更新(重算均值)→ 判断收敛;
nstart=25多次运行取最优 - k 值选择:肘部法则(WCSS 拐点)+ 轮廓系数(最大化 \(s(i)\))双重验证
- 黄金组合:先用层次聚类探索 k 值,再用 K均值处理全量数据
- 今天的主题:关联规则挖掘——Apriori 算法,从购物篮数据中自动发现"啤酒 → 尿布"式的共现规律
本讲内容
- Part 1:关联规则概览 ——啤酒与尿布的故事
- Part 2:核心概念 ——支持度、置信度、提升度
- Part 3:Apriori 算法原理 ——逐步手算完整示例(5 笔交易,从头到尾)
-
Part 4:R 语言实现 ——
arules包与 Groceries 数据集 - Part 5:结果解读与可视化 ——散点图、网络图、分组矩阵图
- Part 6:小结 ——关联规则的适用场景与注意事项
Part 1:关联规则概览
从"啤酒与尿布"开始
真实故事:啤酒与尿布
1990 年代,美国沃尔玛的数据分析师发现了一个奇怪的规律……
- 超市销售数据显示,周五傍晚的啤酒和尿布销量同时飙升
- 直觉上两者毫不相关——一个是酒精饮料,一个是婴儿用品
- 数据分析揭示:下班后顺路购物的年轻父亲,在帮孩子买尿布的同时会顺手带几瓶啤酒犒劳自己
- 沃尔玛随即将两者相邻陈列,销量双双大幅提升
提示
关联规则的本质
从大量交易记录中,自动发现"如果购买了 A,则很可能也会购买 B"的规律。
这类分析也称为 购物篮分析(Market Basket Analysis),是零售业、电商推荐系统的核心技术之一。
关联规则的形式化定义
一条关联规则的形式:\(A \Rightarrow B\)
如果顾客购买了 \(A\)(前项/Left-Hand Side),那么很可能也会购买 \(B\)(后项/Right-Hand Side)
例子:
\[\{\text{啤酒,薯片}\} \Rightarrow \{\text{可乐}\}\]
读作:"购买了啤酒和薯片的顾客,很可能也会购买可乐"
注记
关联规则不是因果关系!
啤酒不会"导致"购买尿布——关联规则只描述同时出现的频率,不解释原因。
若要探究因果,需要额外的实验设计(如 A/B 测试)。
关联规则的典型应用场景
Part 2:核心概念
支持度、置信度、提升度——三大度量指标
基础术语一览
在介绍公式之前,先统一几个基本术语:
| 术语 | 英文 | 说明 |
|---|---|---|
| 项(Item) | Item | 单个商品,如"啤酒"、"尿布" |
| 项集(Itemset) | Itemset | 若干项的集合,如 {啤酒, 尿布} |
| 事务(Transaction) | Transaction | 一次购物的全部商品,即一张购物小票 |
| 事务数据库 | Transaction DB | 所有购物记录的集合,共 \(N\) 笔 |
| \(k\)-项集 | k-itemset | 含有 \(k\) 个项的项集 |
注记
记号约定
- \(N\) = 事务总数
- \(\text{count}(A)\) = 包含项集 \(A\) 的事务数
- \(\text{support}(A) = \text{count}(A) / N\)
概念一:支持度(Support)
支持度 = 项集在所有事务中出现的频率
\[\text{support}(A) = \frac{\text{count}(A)}{N}\]
\[\text{support}(A \Rightarrow B) = \frac{\text{count}(A 和 B)}{N} = P(A \cap B)\]
直觉理解:支持度衡量规则的"普遍性"——这条规则在数据中出现得有多频繁?
提示
最小支持度阈值(min_sup)
我们只保留支持度 \(\geq\) min_sup 的项集,称为频繁项集(Frequent Itemset)。
支持度过低的项集可能是偶然巧合,不具有实际意义。
概念二:置信度(Confidence)
置信度 = 给定前项 \(A\),后项 \(B\) 出现的条件概率
\[\text{confidence}(A \Rightarrow B) = \frac{\text{support}(A 和 B)}{\text{support}(A)} = P(B \mid A)\]
直觉理解:置信度衡量规则的"可靠性"——在买了 A 的顾客中,有多大比例也买了 B?
提示
最小置信度阈值(min_conf)
只有置信度 \(\geq\) min_conf 的规则才被保留。
高置信度意味着:知道顾客买了 A,我们对"他也会买 B"的预测有较高把握。
为什么置信度不够用?
陷阱:置信度高 ≠ 规则有价值!
反例: 假设牛奶出现在 80% 的购物篮中(本身就很畅销)
\[\text{confidence}(\text{啤酒} \Rightarrow \text{牛奶}) = 80\%\]
这条规则置信度很高,但没有任何意义——即使顾客什么都不买,预测"会买牛奶"也有 80% 准确率!
→ 我们需要排除 B 本身就很畅销的干扰,引入提升度。
概念三:提升度(Lift)
提升度 = 实际共现概率 ÷ 若 A、B 相互独立时的预期共现概率
\[\text{lift}(A \Rightarrow B) = \frac{\text{confidence}(A \Rightarrow B)}{\text{support}(B)} = \frac{P(A \cap B)}{P(A) \cdot P(B)}\]
解读:
| 提升度 | 含义 |
|---|---|
| \(\text{lift} > 1\) | \(A\) 和 \(B\) 正相关:买了 A 更可能买 B ✅ 有价值 |
| \(\text{lift} = 1\) | \(A\) 和 \(B\) 独立:购买 A 不影响购买 B 的概率 |
| \(\text{lift} < 1\) | \(A\) 和 \(B\) 负相关:买了 A 反而不太可能买 B |
重要
提升度是判断规则质量最重要的指标。实践中通常只保留 lift > 1 的规则,且越大越好。
三大指标综合示例

Part 3:Apriori 算法原理
逐步手算——从 1-项集到最终关联规则
为什么需要 Apriori 算法?
暴力枚举的代价
若共有 \(m\) 种不同商品,则所有可能的非空项集数量为 \(2^m - 1\)。
- \(m = 50\):约 \(10^{15}\) 个候选集
- \(m = 100\):约 \(10^{30}\) 个候选集——完全无法穷举!
Apriori 算法的核心洞察:反单调性(Anti-Monotonicity)
重要
先验原理(Apriori Principle):
\[\text{如果项集}\ A\ \text{是频繁的(support} \geq \text{min_sup),则}\ A\ \text{的所有子集也是频繁的}\]
逆命题(用于剪枝):
\[\text{如果项集}\ A\ \text{是非频繁的,则}\ A\ \text{的所有超集也一定是非频繁的}\]
→ 一旦发现某个项集不频繁,立刻剪掉其所有超集,无需再检验!
算法整体流程
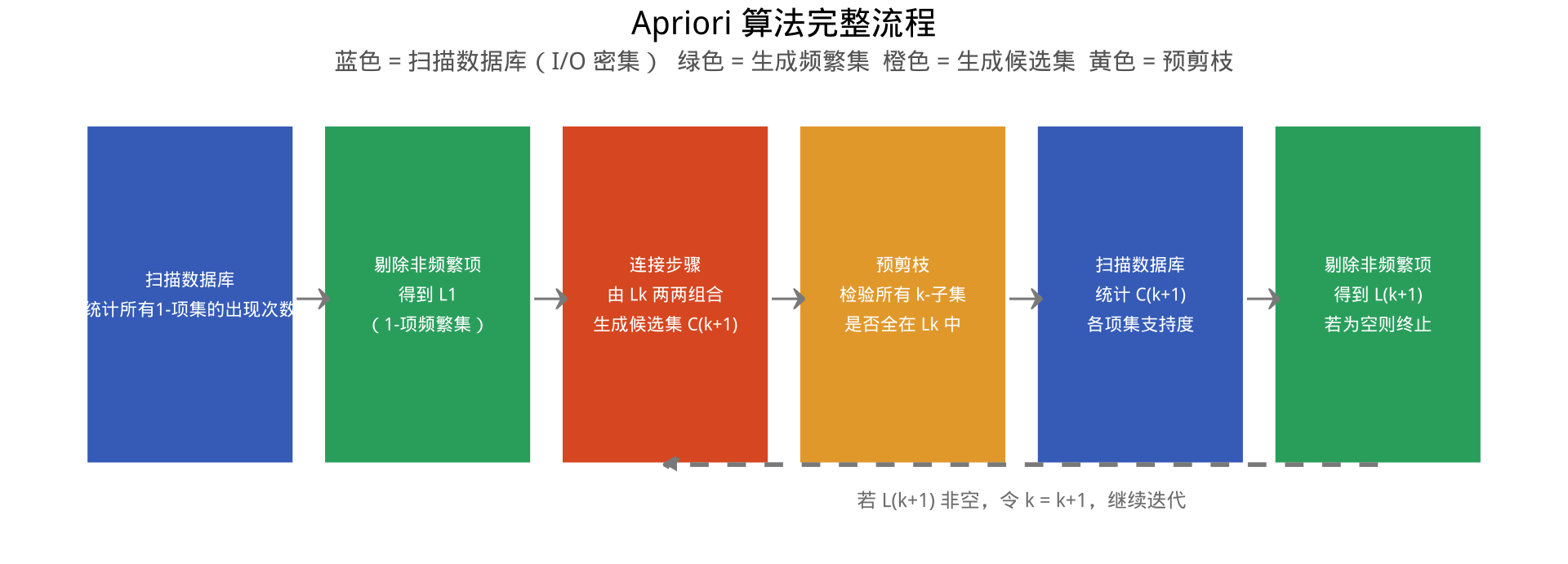
手算示例:数据集与参数设定
数据集:5 笔事务,6 种商品
| 事务ID | 购买商品 |
|---|---|
| T1 | 面包、牛奶、黄油 |
| T2 | 面包、尿布、啤酒、鸡蛋 |
| T3 | 牛奶、尿布、啤酒、可乐 |
| T4 | 面包、牛奶、尿布、啤酒 |
| T5 | 面包、牛奶、尿布、可乐 |
参数设定:
- 最小支持度 \(\text{min_sup} = 0.4\),即至少出现 \(\lceil 5 \times 0.4 \rceil = \mathbf{2}\) 次
- 最小置信度 \(\text{min_conf} = 0.6\)
Step 1:扫描数据库,生成 1-项频繁集 \(L_1\)
统计每个单个商品在 5 笔事务中的出现次数:
| 1-项集 | 出现事务 | 出现次数 | 支持度 | 是否频繁 |
|---|---|---|---|---|
| {面包} | T1,T2,T4,T5 | 4 | 4/5=0.80 | ✅ |
| {牛奶} | T1,T3,T4,T5 | 4 | 4/5=0.80 | ✅ |
| {黄油} | T1 | 1 | 1/5=0.20 | ❌ 剪枝 |
| {尿布} | T2,T3,T4,T5 | 4 | 4/5=0.80 | ✅ |
| {啤酒} | T2,T3,T4 | 3 | 3/5=0.60 | ✅ |
| {鸡蛋} | T2 | 1 | 1/5=0.20 | ❌ 剪枝 |
| {可乐} | T3,T5 | 2 | 2/5=0.40 | ✅ |
. . .
\[L_1 = \Big\{\{\text{面包}\},\ \{\text{牛奶}\},\ \{\text{尿布}\},\ \{\text{啤酒}\},\ \{\text{可乐}\}\Big\}\]
黄油(1次)和鸡蛋(1次)被剪枝——后续所有包含它们的项集无需再计算。
Step 2:由 \(L_1\) 生成候选集 \(C_2\),并统计支持度
从 \(L_1\)(5个项)中两两组合:\(\binom{5}{2} = 10\) 个候选 2-项集
| 候选2-项集 | 出现事务 | 次数 | 支持度 | 是否频繁 |
|---|---|---|---|---|
| {面包, 牛奶} | T1,T4,T5 | 3 | 0.60 | ✅ |
| {面包, 尿布} | T2,T4,T5 | 3 | 0.60 | ✅ |
| {面包, 啤酒} | T2,T4 | 2 | 0.40 | ✅ |
| {面包, 可乐} | T5 | 1 | 0.20 | ❌ 剪枝 |
| {牛奶, 尿布} | T3,T4,T5 | 3 | 0.60 | ✅ |
| {牛奶, 啤酒} | T3,T4 | 2 | 0.40 | ✅ |
| {牛奶, 可乐} | T3,T5 | 2 | 0.40 | ✅ |
| {尿布, 啤酒} | T2,T3,T4 | 3 | 0.60 | ✅ |
| {尿布, 可乐} | T3,T5 | 2 | 0.40 | ✅ |
| {啤酒, 可乐} | T3 | 1 | 0.20 | ❌ 剪枝 |
. . .
{面包, 可乐} 和 {啤酒, 可乐} 被剪枝 → 后续包含这两个 2-项集的所有 3-项集也无需生成!
Step 2(续):2-项频繁集 \(L_2\)
剔除非频繁候选集后,得到 \(L_2\)(8 个):
\[L_2 = \Big\{ \{\text{面包,牛奶}\},\ \{\text{面包,尿布}\},\ \{\text{面包,啤酒}\},\ \{\text{牛奶,尿布}\},\] \[\{\text{牛奶,啤酒}\},\ \{\text{牛奶,可乐}\},\ \{\text{尿布,啤酒}\},\ \{\text{尿布,可乐}\} \Big\}\]
. . .
预剪枝效果可视化:

Step 3:由 \(L_2\) 生成候选集 \(C_3\),并进行预剪枝
连接规则: 两个 \(L_2\) 中共享前 \(k-1\) 个项的频繁集合并,生成候选 \((k+1)\)项集。
预剪枝检验: 每个候选 3-项集的所有 2-子集必须都在 \(L_2\) 中,否则直接剪枝。
| 候选3-项集 | 所有2-子集(均需在L₂中) | 通过预剪枝 |
|---|---|---|
| {面包, 牛奶, 尿布} | {面包,牛奶}✅ {面包,尿布}✅ {牛奶,尿布}✅ | ✅ |
| {面包, 牛奶, 啤酒} | {面包,牛奶}✅ {面包,啤酒}✅ {牛奶,啤酒}✅ | ✅ |
| {面包, 尿布, 啤酒} | {面包,尿布}✅ {面包,啤酒}✅ {尿布,啤酒}✅ | ✅ |
| {牛奶, 尿布, 啤酒} | {牛奶,尿布}✅ {牛奶,啤酒}✅ {尿布,啤酒}✅ | ✅ |
| {牛奶, 尿布, 可乐} | {牛奶,尿布}✅ {牛奶,可乐}✅ {尿布,可乐}✅ | ✅ |
注记
例如,{面包, 牛奶, 可乐} 的子集 {面包,可乐} 不是频繁2项集,因此已被预剪枝排除,无需统计支持度。
Step 3(续):统计 \(C_3\) 支持度,得到 \(L_3\)
| 3-项集 | 出现事务 | 次数 | 支持度 | 是否频繁 |
|---|---|---|---|---|
| {面包, 牛奶, 尿布} | T4, T5 | 2 | 0.40 | ✅ |
| {面包, 牛奶, 啤酒} | T4 | 1 | 0.20 | ❌ 剪枝 |
| {面包, 尿布, 啤酒} | T2, T4 | 2 | 0.40 | ✅ |
| {牛奶, 尿布, 啤酒} | T3, T4 | 2 | 0.40 | ✅ |
| {牛奶, 尿布, 可乐} | T3, T5 | 2 | 0.40 | ✅ |
. . .
\[L_3 = \Big\{ \{\text{面包,牛奶,尿布}\},\ \{\text{面包,尿布,啤酒}\},\ \{\text{牛奶,尿布,啤酒}\},\ \{\text{牛奶,尿布,可乐}\} \Big\}\]
{面包,牛奶,啤酒} 被剪枝(只出现在 T4 一次,support = 0.20 < 0.4)
Step 4:尝试生成 \(C_4\)——算法终止
从 \(L_3\)(4 个 3-项集)尝试生成 4-项候选集:
-
\(\{\text{面包,牛奶,尿布}\}\) 和 \(\{\text{面包,尿布,啤酒}\}\):合并生成 \(\{\text{面包,牛奶,尿布,啤酒}\}\)
- 子集 \(\{\text{牛奶,尿布,啤酒}\}\) ✅ 在 \(L_3\) 中,但子集 \(\{\text{面包,牛奶,啤酒}\}\) ❌ 不在 \(L_3\) 中 → 剪枝
- 其他组合同理,所有候选 4-项集均被预剪枝消除
. . .
重要
算法终止! \(C_4 = \emptyset\),无法生成任何频繁 4-项集。
最终频繁集汇总:
| 层级 | 频繁集数量 |
|---|---|
| \(L_1\):1-项频繁集 | 5 个 |
| \(L_2\):2-项频繁集 | 8 个 |
| \(L_3\):3-项频繁集 | 4 个 |
Step 5:从频繁集生成关联规则
对每个频繁项集,枚举所有非空真子集作为前项,其余为后项,计算置信度:
以 \(\{\text{牛奶,尿布,啤酒}\}\)(support = 0.40)为例:
| 规则 | 前项支持度 | 置信度计算(÷ 前项支持度) | 通过min_conf = 0.6 |
|---|---|---|---|
| 牛奶 → {尿布, 啤酒} | 0.80 | 0.40/0.80 = 0.50 | ❌ |
| 尿布 → {牛奶, 啤酒} | 0.80 | 0.40/0.80 = 0.50 | ❌ |
| 啤酒 → {牛奶, 尿布} | 0.60 | 0.40/0.60 = 0.67 | ✅ |
| {牛奶, 尿布} → 啤酒 | 0.60 | 0.40/0.60 = 0.67 | ✅ |
| {牛奶, 啤酒} → 尿布 | 0.40 | 0.40/0.40 = 1.00 | ✅ |
| {尿布, 啤酒} → 牛奶 | 0.60 | 0.40/0.60 = 0.67 | ✅ |
Step 5(续):计算提升度,筛选最有价值的规则
以 \(L_3\) 中的全部频繁集为基础,下表列出通过置信度筛选且提升度 > 1 的规则:
| 规则 | support | confidence | lift | lift > 1 |
|---|---|---|---|---|
| {牛奶, 啤酒} → 尿布 | 0.4 | 1.00 | 1.25 | ✅ 1.25 |
| {牛奶, 尿布} → 可乐 | 0.4 | 0.67 | 1.67 | ✅ 1.67 |
| 可乐 → {牛奶, 尿布} | 0.4 | 1.00 | 1.67 | ✅ 1.67 |
| {牛奶, 尿布} → 啤酒 | 0.4 | 0.67 | 1.11 | ✅ 1.11 |
| 啤酒 → {牛奶, 尿布} | 0.4 | 0.67 | 0.83 | ❌ 0.83 |
| {尿布, 啤酒} → 牛奶 | 0.4 | 0.67 | 0.83 | ❌ 0.83 |
| {面包, 啤酒} → 尿布 | 0.4 | 1.00 | 1.25 | ✅ 1.25 |
| {尿布, 啤酒} → 面包 | 0.4 | 0.67 | 0.83 | ❌ 0.83 |
. . .
提示
最优规则 → \(\{\text{牛奶,尿布}\} \Rightarrow \text{可乐}\),lift = 1.67
知道顾客同时购买牛奶和尿布后,其购买可乐的概率提升了 67%!
Part 4:R 语言实现
arules 包与 Groceries 数据集
Groceries 数据集简介
transactions in sparse format with
9835 transactions (rows) and
169 items (columns) items
[1] {citrus fruit,
semi-finished bread,
margarine,
ready soups}
[2] {tropical fruit,
yogurt,
coffee}
[3] {whole milk}
[4] {pip fruit,
yogurt,
cream cheese ,
meat spreads}
[5] {other vegetables,
whole milk,
condensed milk,
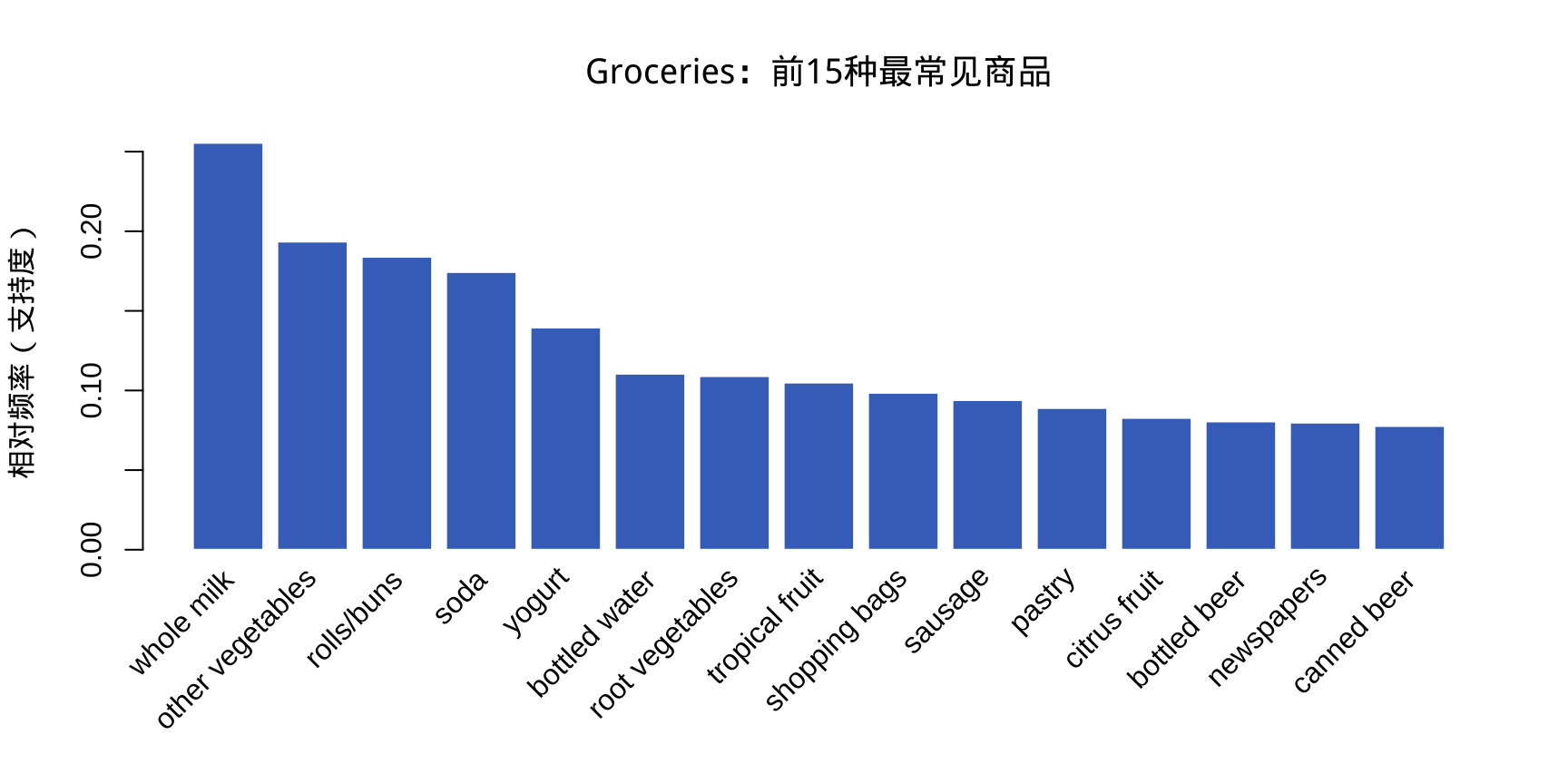
long life bakery product}数据探索:最常见的商品
运行 Apriori 算法
▶️ 查看代码
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen
0.3 0.1 1 none FALSE TRUE 5 0.01 2
maxlen target ext
10 rules TRUE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 98
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[169 item(s), 9835 transaction(s)] done [0.01s].
sorting and recoding items ... [88 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 4 done [0.00s].
writing ... [125 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].set of 125 rules set of 125 rules
rule length distribution (lhs + rhs):sizes
2 3
69 56
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.00 2.00 2.00 2.45 3.00 3.00
summary of quality measures:
support confidence coverage lift count
Min. :0.0101 Min. :0.308 Min. :0.0173 Min. :1.21 Min. : 99
1st Qu.:0.0115 1st Qu.:0.345 1st Qu.:0.0289 1st Qu.:1.61 1st Qu.:113
Median :0.0145 Median :0.398 Median :0.0371 Median :1.79 Median :143
Mean :0.0186 Mean :0.406 Mean :0.0478 Mean :1.91 Mean :183
3rd Qu.:0.0222 3rd Qu.:0.450 3rd Qu.:0.0566 3rd Qu.:2.16 3rd Qu.:218
Max. :0.0748 Max. :0.586 Max. :0.1935 Max. :3.30 Max. :736
mining info:
data ntransactions support confidence
Groceries 9835 0.01 0.3
call
apriori(data = Groceries, parameter = list(support = 0.01, confidence = 0.3, minlen = 2))排序与查看最强规则
▶️ 查看代码
lhs rhs support
[1] {citrus fruit, other vegetables} => {root vegetables} 0.01037
[2] {tropical fruit, other vegetables} => {root vegetables} 0.01230
[3] {beef} => {root vegetables} 0.01739
[4] {citrus fruit, root vegetables} => {other vegetables} 0.01037
[5] {tropical fruit, root vegetables} => {other vegetables} 0.01230
[6] {other vegetables, whole milk} => {root vegetables} 0.02318
[7] {whole milk, curd} => {yogurt} 0.01007
[8] {root vegetables, rolls/buns} => {other vegetables} 0.01220
[9] {root vegetables, yogurt} => {other vegetables} 0.01291
[10] {tropical fruit, whole milk} => {yogurt} 0.01515
confidence coverage lift count
[1] 0.3592 0.02888 3.295 102
[2] 0.3428 0.03589 3.145 121
[3] 0.3314 0.05247 3.040 171
[4] 0.5862 0.01769 3.030 102
[5] 0.5845 0.02105 3.021 121
[6] 0.3098 0.07483 2.842 228
[7] 0.3852 0.02613 2.761 99
[8] 0.5021 0.02430 2.595 120
[9] 0.5000 0.02583 2.584 127
[10] 0.3582 0.04230 2.568 149 筛选特定商品的规则
▶️ 查看代码
lhs rhs support confidence
[1] {curd, yogurt} => {whole milk} 0.01007 0.5824
[2] {other vegetables, butter} => {whole milk} 0.01149 0.5736
[3] {tropical fruit, root vegetables} => {whole milk} 0.01200 0.5700
[4] {root vegetables, yogurt} => {whole milk} 0.01454 0.5630
[5] {other vegetables, domestic eggs} => {whole milk} 0.01230 0.5525
[6] {yogurt, whipped/sour cream} => {whole milk} 0.01088 0.5245
[7] {root vegetables, rolls/buns} => {whole milk} 0.01271 0.5230
[8] {pip fruit, other vegetables} => {whole milk} 0.01352 0.5175
coverage lift count
[1] 0.01729 2.279 99
[2] 0.02003 2.245 113
[3] 0.02105 2.231 118
[4] 0.02583 2.203 143
[5] 0.02227 2.162 121
[6] 0.02074 2.053 107
[7] 0.02430 2.047 125
[8] 0.02613 2.025 133 ▶️ 查看代码
lhs rhs support confidence
[1] {root vegetables, yogurt} => {other vegetables} 0.01291 0.5000
[2] {yogurt, whipped/sour cream} => {other vegetables} 0.01017 0.4902
[3] {curd, yogurt} => {whole milk} 0.01007 0.5824
[4] {root vegetables, yogurt} => {whole milk} 0.01454 0.5630
[5] {tropical fruit, yogurt} => {other vegetables} 0.01230 0.4201
coverage lift count
[1] 0.02583 2.584 127
[2] 0.02074 2.533 100
[3] 0.01729 2.279 99
[4] 0.02583 2.203 143
[5] 0.02928 2.171 121 转换为数据框,便于进一步分析
▶️ 查看代码
rules support confidence
1 {citrus fruit,other vegetables} => {root vegetables} 0.01037 0.3592
2 {tropical fruit,other vegetables} => {root vegetables} 0.01230 0.3428
3 {beef} => {root vegetables} 0.01739 0.3314
4 {citrus fruit,root vegetables} => {other vegetables} 0.01037 0.5862
5 {tropical fruit,root vegetables} => {other vegetables} 0.01230 0.5845
6 {other vegetables,whole milk} => {root vegetables} 0.02318 0.3098
7 {whole milk,curd} => {yogurt} 0.01007 0.3852
8 {root vegetables,rolls/buns} => {other vegetables} 0.01220 0.5021
9 {root vegetables,yogurt} => {other vegetables} 0.01291 0.5000
10 {tropical fruit,whole milk} => {yogurt} 0.01515 0.3582
coverage lift count
1 0.02888 3.295 102
2 0.03589 3.145 121
3 0.05247 3.040 171
4 0.01769 3.030 102
5 0.02105 3.021 121
6 0.07483 2.842 228
7 0.02613 2.761 99
8 0.02430 2.595 120
9 0.02583 2.584 127
10 0.04230 2.568 149Part 5:结果解读与可视化
散点图、网络图、分组矩阵图
散点气泡图:三指标一览
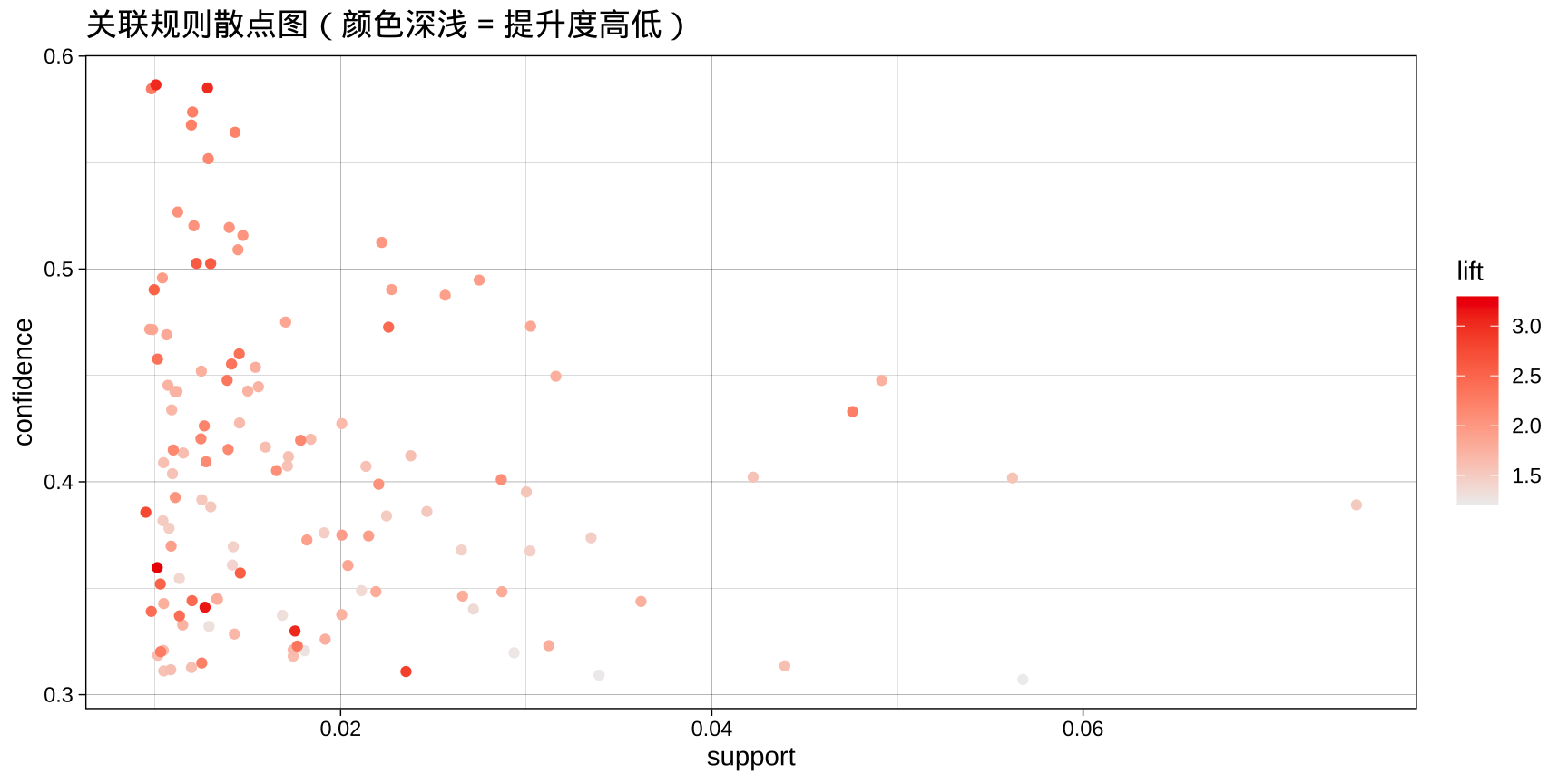
解读散点图

网络图:直观展示商品关联
分组矩阵图:前项 × 后项关联矩阵
▶️ 查看代码
Available control parameters (with default values):
k = 20
aggr.fun = function (x, ...) UseMethod("mean")
rhs_max = 10
lhs_label_items = 2
col = c("#EE0000FF", "#EEEEEEFF")
groups = NULL
engine = ggplot2
verbose = FALSE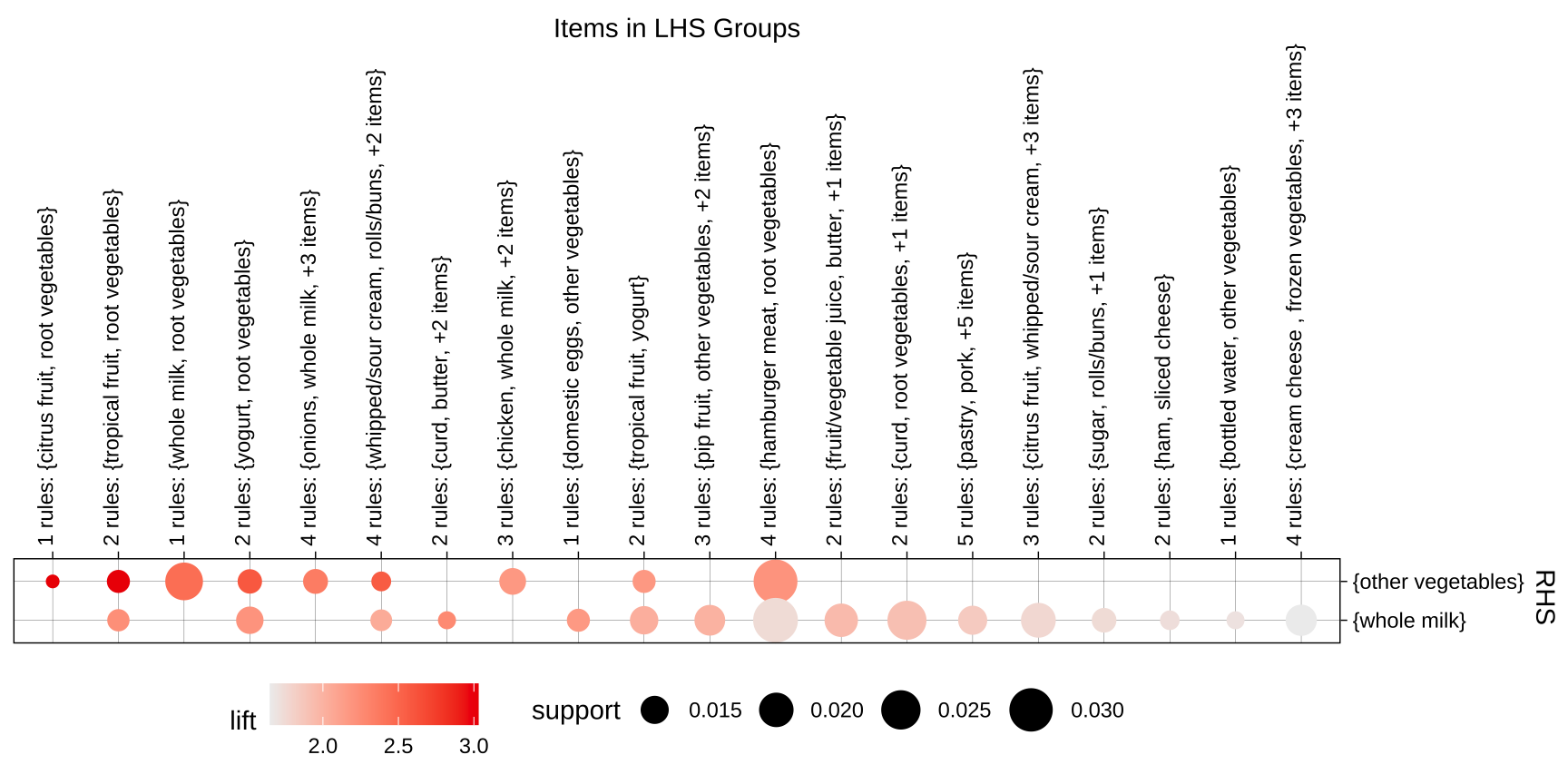
业务洞察:从可视化到决策
-
节点大小(网络图):代表商品的支持度(出现频率),
whole milk、other vegetables是超市的"枢纽商品" - 边的颜色:代表提升度,颜色越深说明规则越强
- 聚集性:高度关联的商品群体往往对应某种消费场景(如健康饮食、早餐搭配)
典型业务应用:

Part 6:小结
关联规则的适用场景与注意事项
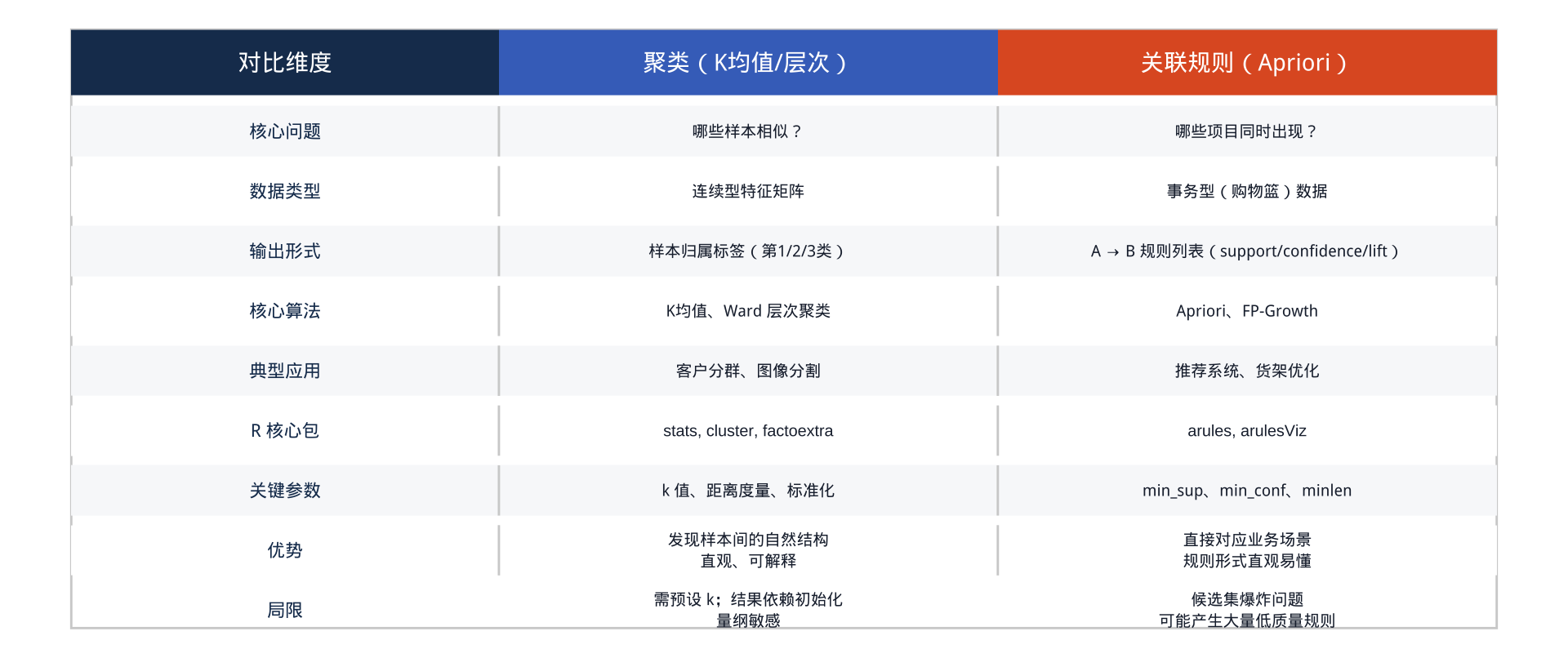
关联规则 vs 聚类:两种无监督学习的对比
使用关联规则的五大注意事项
- 调整阈值要谨慎:min_sup 过高会漏掉有价值的长尾规则;过低会产生海量低质量规则,难以筛选
- 以提升度为核心筛选器:高置信度 + 低提升度 = 该商品本身就很畅销,规则无任何意义
- 关联 ≠ 因果:啤酒和尿布的关联是相关性,而非"喝啤酒导致购买尿布"的因果
- 稀疏数据的挑战:若大多数事务只含 1–2 个项,min_sup 的分母很大,频繁集会很少
- 规则爆炸问题:商品种类极多时,建议先按品类分层,再在每类内部挖掘关联规则
本讲核心知识点回顾

本讲小结
关联规则:形如 \(A \Rightarrow B\) 的规律,刻画项目的共现模式;"啤酒与尿布"是最经典的案例
-
三大度量:
- 支持度(普遍性)→ 筛选频繁项集,过滤偶发规律
- 置信度(可靠性)→ 评估预测准确率,\(P(B|A)\)
- 提升度(实际价值)→ 排除畅销品干扰,是最重要的筛选指标,lift > 1 才有意义
-
Apriori 算法:利用反单调性进行逐层预剪枝,大幅减少候选集数量
- 连接步(由 \(L_k\) 生成 \(C_{k+1}\))→ 预剪枝步(检验所有 \(k\)-子集)→ 扫描数据库 → 迭代直至收敛
R 实现:
arules::apriori()+arulesViz可视化三件套(散点图、网络图、分组矩阵图)注意事项:阈值设置、提升度优先、关联非因果、稀疏数据挑战
课后练习
请用 arules 包完成以下分析:
练习 1:数据探索
加载 Groceries 数据集,绘制商品频率图,找出支持度最高的前 5 种商品,并说明它们为何支持度高。
练习 2:挖掘规则
用 apriori() 挖掘满足以下条件的规则:
统计:共挖掘出多少条规则?提升度的分布如何(最小值、最大值、均值)?
练习 3:筛选与排序
筛选出提升度 > 2.5 的规则,按提升度降序排列,选出最强的前 5 条,用自己的语言描述其业务含义。
练习 4:定向分析——酸奶
分别按 lift 降序排列,写出你的发现。
练习 5:可视化与洞察
绘制提升度最高的前 20 条规则的网络图,观察:
- 哪个商品节点最大(支持度最高)?
- 颜色最深(提升度最高)的边连接了哪两个商品?
- 根据结果,为某超市提出至少 2 条货架摆放或促销方案的建议,并说明依据。
. . .
重要
提示
- 用
subset(rules, lhs %in% "yogurt")筛选前项含酸奶的规则 - 用
plot(top20, method = "graph", engine = "htmlwidget")绘制交互式网络图 - 挖掘的规则越多,分析越有深度——建议适当降低 min_sup 探索更多规律
谢谢!
第21讲:关联规则与Apriori算法
「Apriori 的智慧在于:不是找出所有可能的组合,而是先问一个简单的问题——这个商品本身卖得好吗?卖不好的,连同它的所有"搭档"一起,全部不用考虑了。」
数据挖掘与R语言 | 关联规则与Apriori算法