
数据挖掘与R语言
第22讲:关联规则(二)——参数调优、可视化与购物篮分析实战
2026年06月12日
散点图:三指标全景鸟瞰
如何阅读散点图?

网络图的业务解读
提示
实际案例:超市购物篮网络图的典型发现

注记
财务审计场景的延伸
在财务审计中,网络图可以直观展示哪些违规行为是"成群结队"出现的——例如"虚增收入"节点与"应收账款异常"节点之间若有深色粗边,说明两者高度关联,需要联合排查。
可视化方法对比

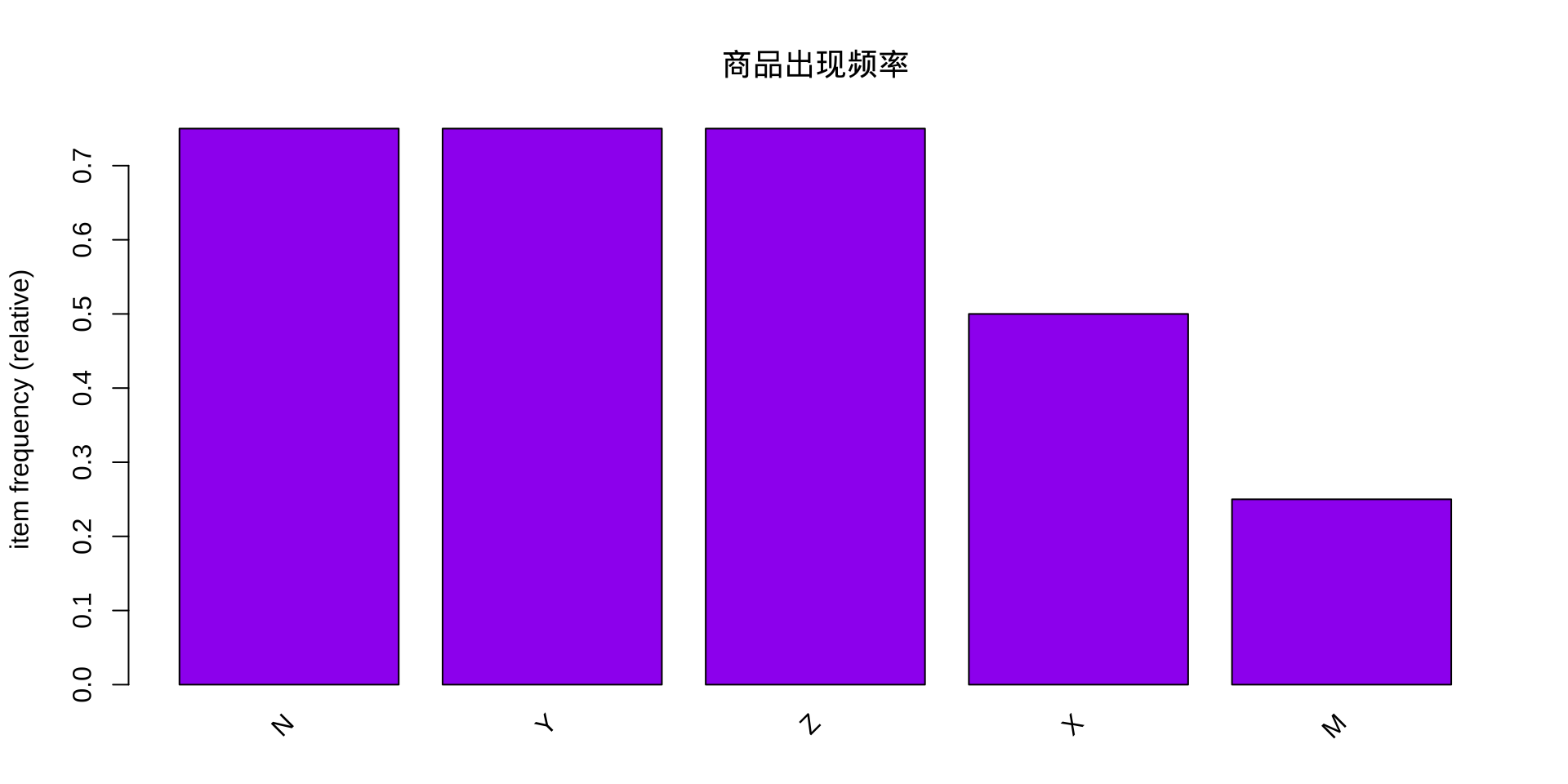
练习 1:读入数据与摘要分析
目标:了解数据集的基本结构与商品分布
▶️ 查看代码
transactions as itemMatrix in sparse format with
4 rows (elements/itemsets/transactions) and
5 columns (items) and a density of 0.6
most frequent items:
N Y Z X M (Other)
3 3 3 2 1 0
element (itemset/transaction) length distribution:
sizes
2 3 4
1 2 1
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.00 2.75 3.00 3.00 3.25 4.00
includes extended item information - examples:
labels
1 M
2 N
3 X M N X Y Z
0.25 0.75 0.50 0.75 0.75 ▶️ 查看代码
提示
summary() 会告诉你什么?
事务总数、商品总数、最短/最长事务长度,以及最常出现的商品排名。
练习7: 以 N 为前项集的规则,并作图
目标:找出所有前项(lhs)中包含 N 的规则
▶️ 查看代码
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen
0.8 0.1 1 none FALSE TRUE 5 0.5 1
maxlen target ext
10 rules TRUE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 2
set item appearances ...[1 item(s)] done [0.00s].
set transactions ...[5 item(s), 4 transaction(s)] done [0.00s].
sorting and recoding items ... [4 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 done [0.00s].
writing ... [1 rule(s)] done [0.00s].
creating S4 object ... done [0.00s]. lhs rhs support confidence coverage lift count
[1] {N} => {Y} 0.75 1 0.75 1.333 3 
预期结果:
| 规则 | 支持度 | 置信度 | 提升度 | 业务解读 |
|---|---|---|---|---|
| {N} ⇒ {Y} | 0.75 | 1.00 | 1.33 | 购买 N 的顾客中,100% 也购买了 Y |
| 可考虑 N、Y 捆绑促销 |
提示
业务意义:在所有购买了 N 的顾客中,100% 都同时购买了 Y。这条规则支持度高(75%)、 置信度满分(100%),是制定捆绑促销策略的有力依据。
练习 8:以 N 为后项集的规则
目标:找出所有后项(rhs)中包含 N 的规则——"什么会引发对 N 的需求?"
▶️ 查看代码
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen
0.8 0.1 1 none FALSE TRUE 5 0.5 1
maxlen target ext
10 rules TRUE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 2
set item appearances ...[1 item(s)] done [0.00s].
set transactions ...[5 item(s), 4 transaction(s)] done [0.00s].
sorting and recoding items ... [4 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 done [0.00s].
writing ... [2 rule(s)] done [0.00s].
creating S4 object ... done [0.00s]. lhs rhs support confidence coverage lift count
[1] {Y} => {N} 0.75 1 0.75 1.333 3
[2] {Y, Z} => {N} 0.50 1 0.50 1.333 2 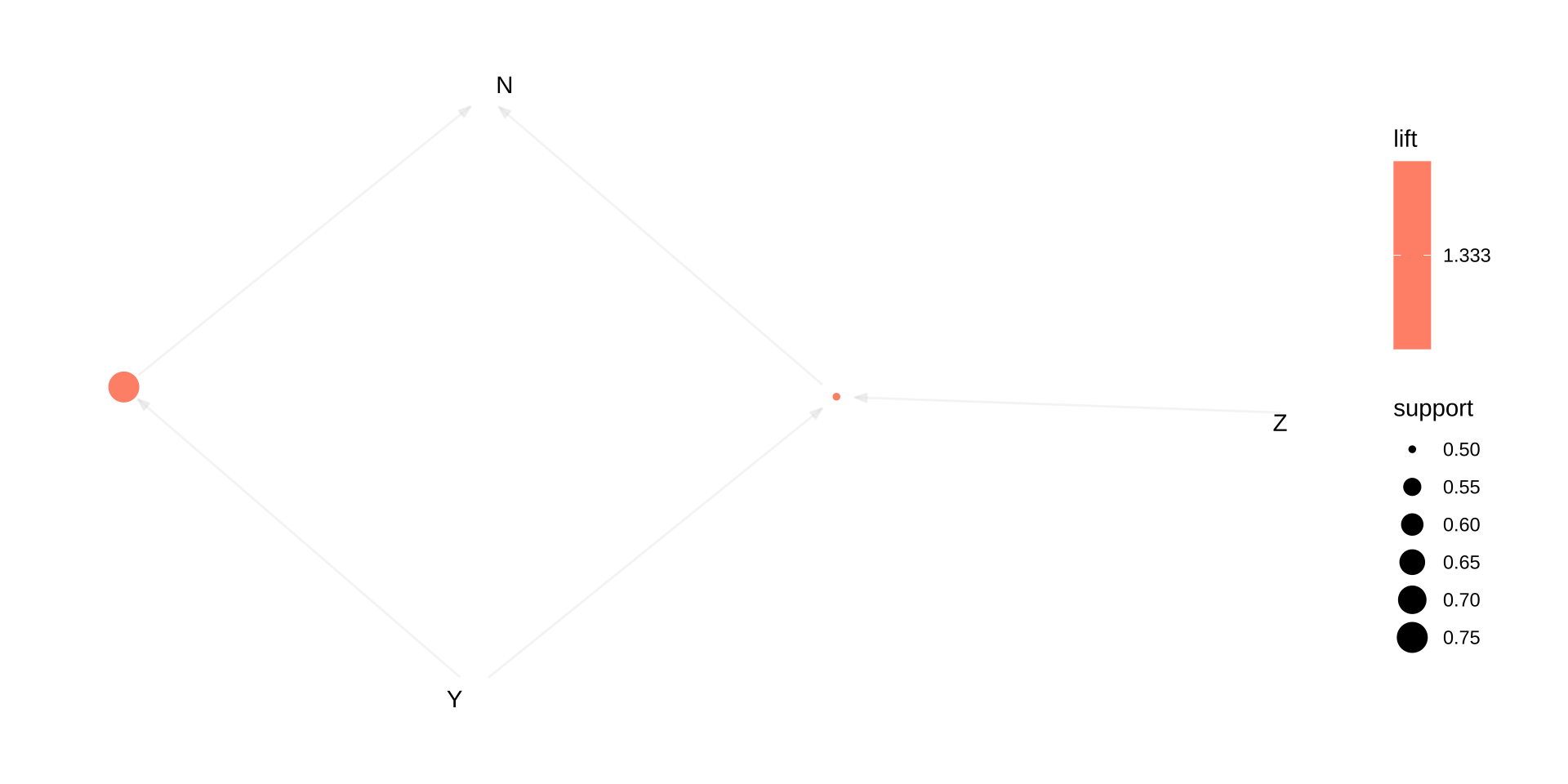
预期结果:
| 规则 | 支持度 | 置信度 | 提升度 | 业务解读 |
|---|---|---|---|---|
| {Y,Z} ⇒ {N} | 0.50 | 1.00 | 1.33 | 购买 Y 和 Z 的顾客 100% 也买 N |
| {Y} ⇒ {N} | 0.75 | 1.00 | 1.33 | 购买 Y 的顾客 100% 也买 N |
提示
交叉销售建议:Y 是驱动 N 销售的关键前导商品。可以在 Y 的货架旁放置 N 的推荐标签, 或在顾客将 Y 加入购物车时,弹出 N 的关联推荐。
综合练习小结:四步分析框架
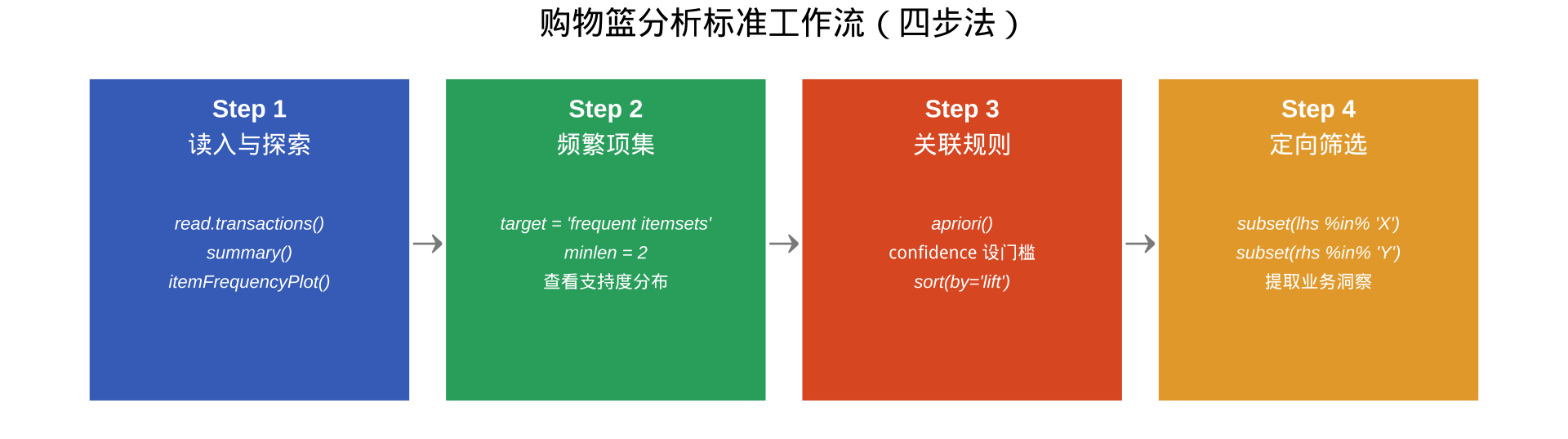
本讲核心知识点回顾

关联规则的局限性与进阶方向
